Оглавление
- Роль моделей в XML-приложениях
- Что такое UML?
- Концептуальные модели XML-словарей
- Проектирование моделей схем XML
- Отображение UML-моделей в схемы XML
- Заключение
Сообщество разработчиков программ, системных интеграторов, XML-аналитиков, авторов и разработчиков B2B-словарей сразу же отреагировало на публикацию Спецификации W3C XML Schema. Некоторые радовались более богатой структуре и семантике, которая может быть выражена при помощи новых схем по сравнению с DTD, другие же наоборот говорили о чрезмерной их сложности. И многие сошлись на том, что результирующие схемы сложны для широкой аудитории пользователей и бизнес-партнеров.
Из всех различных подходов к XML Schema, мне удобнее рассматривать ее просто как синтаксис для реализации моделей бизнес-словарей. Зачастую при создании новых словарей или совместном использовании с пользователями уже определенных другие формы представления моделей более эффективны, чем W3C XML Schema. В частности, я предпочитаю использовать унифицированный язык моделирования UML, как широко применяемого стандарта для спецификаций систем и проектирования. Публикацией этого цикла статей я хотел бы донести до читателей некоторые свои соображения о том, как эти два стандарта дополняют друг друга и совместно работают. Для того, чтобы сделать изложение более понятным, я построил его на основе простого примера.
Хотя в этой статье идет речь о спецификации W3C XML Schema, аналогичные рассуждения верны и для других языков схем XML. В действительности, я уже применял подобные технологии при создании и реинжиниринге DTD и схем SOX также, как и при использовании RELAX, TREX, и RELAX NG. В общем, когда я использую термин "схема", я подразумеваю не какой-то конкретный язык, а семейство языков схем XML.
Роль моделей в XML-приложениях
Большие корпоративные системы часто сложны для понимания. В таких случаях порой необходимо разбить исходную проблему на множество вспомогательных подмоделей, представляющих различные точки зрения. В каждой из этих подмоделей целенаправленно игнорируютя некоторые аспекты системы, которые не относятся к их области применения. Такая декомпозиция является фундаментальным способом справиться со сложностью реального мира, опуская ненужные детали, мешающие нам сконцентрироваться на самой задаче. К тому же группам, работающим с системой на различных этапах, требуются модели с различной степенью абстрагирования.
В контексте системной интеграции уровня B2B, все бизнес-партнеры должны договориться об общей информационной модели, в рамках которой был бы определен словарь для коммуникации, ориентированный на конкретные задачи. Модели включают как структуру данных для XML-документов, которые участвуют в документооброте, так и процессы, моделирующие расширенные диалоги, требующиеся для выполнения сложных бизнес-транзакций.
Исторически, в системном анализе и проектировании существовали различные технологии, инструменты и методики для управления и поддержки подмоделей системных структур и поведений. В отсутствие формальных методов и инструментов для того, чтобы обеспечить взаимодействие разработчиков будующей системы, создавались модели с помощью PowerPoint, Visio или даже с помощью бумаги и карандаша. Если же нет явно записанных моделей, то системные архитекторы прибегают к использованию интуитивных подмоделей, позволяющих обхватить целое и части основной модели. Схема XML также является моделью словаря, записанной в синтаксисе языка этой спецификации.
Высоко-уровневый подход к разработке XML-словарей показан на рисунке 1. Она включает в себя три точки разветвления, которые обуславливают конечное определение словаря, независимо от того, какой язык схем использовался. Data- и text-ориентированные приложения должны отвечать различным требованиям. Например, data-ориентированные словари могут быть оптимизированы под построение последовательности объектов или под результаты запросов к базам данных, и их внутренние связи должны точно соответствовать типам данных. Документы, отвечающие таким data-ориентированным словарям, могут быть никогда не прочитанными людьми, разве только разработчиками, тестирующими приложения.
Напротив, информация, записанная с помощью text-ориентированных словарей, часто непосредственно используется людьми. При этом приходится править XML-документы, как с помощью так и без помощи визуальных средств редактирования. Структура таких документов должна быть проста, чтобы их могли понять люди, пишущие таблицы стилей для трансформации и представления содержимого документов. XML-приложение, идеально подходящее для работы с данными, иногда может вызвать у пользователя совершенно ненужную головную боль. Не забывайте о потребностях ваших пользователей, когда будете создавать XML-схему!
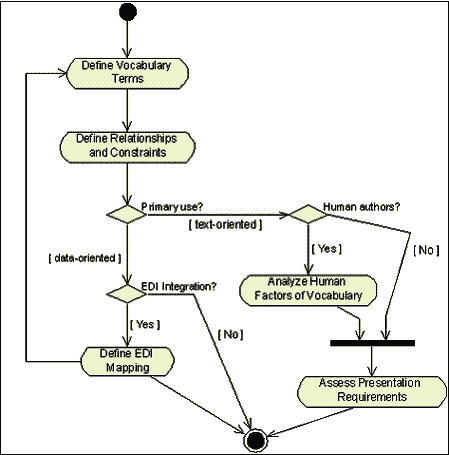
Рис. 1: Диаграмма деятельности UML для процесса разработки схемы
Диаграмма процесса, изображенная выше, является диаграммой деятельности UML, одной из девяти типов, определенных стандартом. Эта диаграмма была создана в пакете Rational Rose, одном из самых широко используемых инструментов для UML-моделирования. Однако, большинство из наших рассуждений базируется на диаграмме классов UML, которая используется для определения статической информационной структуры XML-словаря конкретной системы в контексте нашего приложения.
Что такое UML?
Унифицированный язык моделирования (Unified Modeling Language, UML) определяет стандартный язык и графическую систему обозначений для создания моделей бизнес и технических систем. Вопреки широкораспространенному мнению, UML является инструментом не только для программистов. UML определяет типы моделей, которые покрывают промежуток от функциональных требований и бизнес-моделей до проектирования структур классов и диаграмм компонент. Такие модели, и процесс разработки, использующий их, улучшают и упрощают коммуникацию между многими различными группами исполнителей.
Диаграмма классов UML может быть построена для визуального представления элементов, взаимоотношений и внутренних связей XML-словаря. После небольшого обучения, использование диаграмм классов позволяет использовать сложные словари совместно с нетехническими группами исполнителей. Очень простое подмножество словаря для каталога продуктов показано в виде диаграммы классов на рисунке 2.
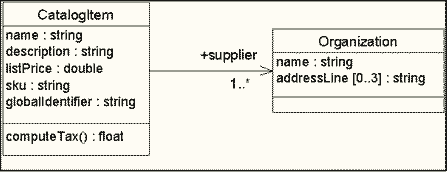
Рис. 2: Простая диаграмма классов UML
Основные элементы диаграммы классов UML следующие.
- Класс (Class) -- в этом примере определяется два класса: класс CatalogItem и класс Organization. Класс представляет совокупность структурных свойств и определяет пространство имен для обозначений этих свойств. Таким образом, оба класса могу содержать атрибут "name", но пространство имен, определяемое их классом делает эти два атрибута различными.
- Атрибут (Attribute) -- каждый класс может опционально определять множество своих атрибутов. Каждый атрибут имеет тип; в этом примере string, double, и float в соотвествии со встроенными типами данных, как определено в спецификации XML Schema. Для тех из вас, кто уже задумывется о проектировании схемы XML, определенными в UML атрибуты не ограничиваются атрибуты в схеме XML; отображение в синтаксис схемы позволяет определить или атрибут XML или дочерний элемент.
- Операция (Operation) -- операция computeTax() внутри CatalogItem частично отражает поведение этого класса. Другими словами, что класс может делать, кроме непосредственно определения структуры своих данных? Выражаясь объектно-ориентированной терминологией, если вы отправите сообщение computeTax объекту CatalogItem, то будет возвращено значение типа float. Эта операция не ожидает каких-либо параметров, но они могут быть определены между круглыми скобками. Мы не будем использовать операции класса в спецификации XML-словаря, но их определение может быть критично для веб-сервисов, особенно для спецификации WSDL сообщений SOAP.
- Ассоциация (Association) -- ассоциация является взаимоотношением двух или более классов в модели. Хотя отношения ассоциации по умолчанию двунаправленное, часто накладываются ограничения на направление навигации. В этом случае на конце ассоциации уют стрелку.
- Роль и Мощность (Role & Multiplicity) -- также на конце ассоциации может определяться роль класса; Organization играет роль поставщика для CatalogItem в нашей модели. Дополнительно, "1..*" обозначает мощность, в смысле, что может быть один или более поставщиков для каждого пункта каталога.
- Обобщение (Generalization) -- хотя унок 2 не содержит наследования класса, эта структура является фундаментальной для объектно-ориентированной модели и включена в следующий расширенный пример.
Концептуальные модели XML-словарей
Теперь, когда вы понимаете простейшие диаграммы классов UML, давайте применим их для проектирования более обширных XML-словарей. Мы будем работать со словарем для языка заказов, который определялся в разделе 2.1 документа XML Schema Part 0: Primer и далее используется во всей спецификации W3C. В нашей модели дополнительно определены международные адреса и поддержка нескольких схем, как описано в разделе 4.1 спецификации W3C. Если вы новичок в XML Schema, я советую вам просмотреть Primer после чтения этой статьи и затем сравнить наш UML-процесс проектирования в этих трех статьях с аналогичным словарем для языка заказов в спецификации схемы.
Словарь для языка заказов определяется в двух модулях, соответствующих основному типу PurchaseOrder и отдельному модулю Address. В UML такие модули называются пакетами. Спецификация первого пакета показана на диаграмме классов UML на рисунке 3. Класс PurchaseOrder имеет два атрибута и три ассоциации, которые определяют его структуру. Некоторые из этих атрибутов включают мощность, определенную символами [0..1], подразумевая, что значение этих атрибутов опционально и принимает значения либо 0, либо 1.
Класс Address играет роль как shipTo, так и billTo в ассоциации с PurchaseOrder. (Замечание: может статься, что shipTo и billTo являются дочерними элементами в схеме.) Мощность 1 обозначает, что для каждого PurchaseOrder должен существовать ровно 1 адрес. Заметим, что в классе Item quantity имеет тип QuantityType. Это тип определен как другой класс в UML-модели. На той же диаграмме QuantityType определен как подкласс класса positiveInteger, который объявляется как приходящий из пакета XSD_Datatypes в этой UML-модели. Таким образом, quantity является специальным типом положительных целых чисел.
И QuantityType, и SKU являются определенными пользователем типами данных, и оба включают атрибуты, что ограничивает их область использования. Атрибуты pattern и maxExclusive являются заданными значениями и используются на следующих этапах процесса проектирования для управления созданием XML Schema. Наконец, имя класса Address показывается курсивом; это означает, что это абстрактный класс, и что он не предназначен для непосредственного использования. Как далее будет видно, Address кроме того определяется в других диаграммах классов UML.
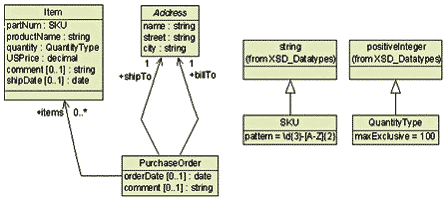
Рис. 3: Концептуальная модель словаря заказов покупок
Спецификация пакета Address, изображенная на унке 4, следует подобной логике. На этой диаграмме USAddress и UKAddress являются подтипами Address. В терминах объектно-ориентированного подхода это означает, что оба этих подтипа наследуют три атрибута, определенные в их суперклассе. Атрибут exportCode класса UKAddress инициализируется со значением 1.
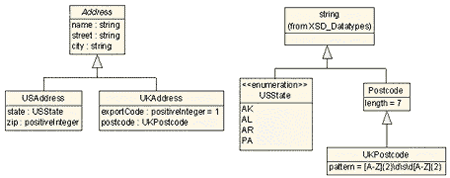
Рис. 4: Компонент схемы Modularized Address
Проектирование моделей схем XML
Теперь, когда мы создали концептуальную модель содержания нашего XML-словаря и получили одобрение от всех бизнес и технических групп исполнителей, что далее? Как было замечено в предыдущем разделе, на этапе отображения нашей модели в XML schema имеется ряд вариантов.
Отображаются ли UML-атрибуты и концы ассоциаций в XML-атрибуты или элементы? Как обобщение классов и типов данных UML отображается в определения схемы? Как на это отображение повлияет изменение целевого языка схемы с W3C XML Schema на RELAX NG? Как насчет DTD?
Если вы вернетесь чуть назад к процессу разработки схемы, изображенному на унке 1, следующая задача проектирования зависит от того, будет ли наш словарь data- или text-ориентированным. Так как словарь для языка заказов является data-ориентированным, большинство оставшихся решений проектирования имеет отношение результатам внедрения: соглашения разработчиков по использованию XML-атрибутов или дочерних элементов, соответствие типов данных с другими точками входа и выхода данных, которыми должны обмениваться при использовании этого словаря, и предполагемые будущие требования для расширения этого словаря или комбинирования его с другими пространствами имен XML.
Если это было бы text-ориентированным приложением, то контент-менеджеры и авторы имели бы дополнительный подход при выборе способа разработки. Например, большинство авторов предпочитают избегать в XML-документах чрезмерного использования контейнерных элементов, для группирования связанных элементов, в то время как это является нормальным подходом в data-ориентированных приложениях. Также, порядок элементов в документе зачастую более важен для людей, чем для приложений, осуществляющих анализ данных.
Основной идеей настоящей статьи являлся обзор концептульной модели словаря, построение которой является первым логическим этапом в процессе разработки. Следующая статья этого цикла представляет список способов разработки и альтернативных подходов для отображения UML в W3C XML Schema. Модель UML, представленная в этой статье, будет доработана для того, чтобы отразить способы разработки, выполненные авторами W3C's XML Schema Primer, откуда взят этот пример. Для наших целей, эти авторы являются соразработчиками системных требований.
В третьей статье быдет введен UML-профиль для схем XML schemas, что позволит добавить все способы детальной разработки к определению модели и затем использовать их для автоматического порождения завершенной схемы. Результатом будет UML-модель, которая используется для порождения W3C XML Schema. Полученная схема может быть использована для успешной проверки на корректность примеров XML-документов, взятых из спецификации Schema Primer. Попутно, я введу веб-инструментарий, используемый для порождения схем из UML и реинжинериинга схем в UML.
Три совета на будущее
Чтобы помощь вам при осуществлении ваших будущих проектов, я предлагаю следующий ряд советов:
- Ваш словарь для электронного бизнеса определяет соглашение или контракт между всеми заинтересованными сторонами. Получите начальные требования всех ключевых соучастников, используя визуальные модели UML для улучшения взаимопонимания.
- Определите все известные термины, ассоциации и внутренние связи, а для документов их цель, источник и область использования. Не ограничивайте ваши спецификации использованием только выражений DTD или даже расширенного языка W3C XML Schema. Используя UML, вы можете получить полную спецификацию и затем преобразовать ее в любой язык схем XML. Фрагменты документации, добавленные в UML-модель, могут быть автоматически преобразованы в примечания в схеме XML.
- Создавайте общую UML-модель, чтобы иметь возможность управлять определением схемы XML и другими неXML-компонентами системы. Многие системы используют XML в подмножестве их компонент, но анализ должен быть выполнен целостно.
Модели - это неотъемлемые части анализа и проектирования, даже если они существуют лишь в голове разработчика. Используя UML для создания концептуальной модели планируемого словаря, мы можем обрисовать существенные моменты и взаимосвязи, не попав в ловушку синтаксических проблем выбранного языка схем. Фактически, группы разработчиков отраслевых стандартов могут использовать UML для первичного определения их словарей, а окончательный выбор языка (или языков) схем оставить тем, кто уже непосредственно будет заниматься их реализацией.
Я также хочу подчеркнуть, что подход к разработке схемы, базирующийся на моделях и описанный в этом цикле статей, гораздо ближе к итерационной методологии разработки, а не к каскадной. Первая схема, созданная с применением правил отображения, используемых по умолчанию, из модели словаря заказа покупок, может быть и не идеальна, но она точно схватывает семантику моделируемой области. В третьей части этого цикла статей описывается, как модель может быть специализирована с учетом особенностей проектирования, уникальных для XML-схем. Этот подход соответствует современной методологии быстрого программирования и моделирования, где модели выполняют очень прагматичную роль в процессе разработки. (См. XMLmodeling.com, веб-портал, который я создал, чтобы объединить данные конкретных исследований и ресурсы по моделированию).
Для того, чтобы достичь этих довольно высоких целей, важно, что мы имеем полные и гибкие спецификации отображения между UML и схемами XML. Приведенные ниже примеры не представляют законченной картины, но являются попыткой ввести вас в лабиринт терминологии UML и W3C XML Schema Definition Language (в дальнейшем я буду его называть XSD).
Отображение UML-моделей в схемы XML
Именно это является ключевым моментом использования UML при разработке XML-схем. Основной целью, определяющей спецификацию такого отображения, является обеспечение его достаточной гибкостью, чтобы покрыть большинство требований к разработке схем, но при этом сохранить "мягкий" переход от концептуальной модели словаря к его детальной проработке и последующей реализации.
Родственная цель - создать условия для автоматической генерации корректной XML-схемы из любой диаграммы классов UML, даже если тот, кто моделирует не знаком с синтаксисом XML-схем. Наличие такой возможности допускает быстрый процесс разработки и поддерживает многократное использование моделей словарей для различных языков реализации или окружений, поскольку сама модель не слишком привязана непосредственно к XML.
Отметьте, пожалуйста, что примеры схем в этой статье не полностью сопоставимы с соответствующим примером в XML Schema Primer. Тем не менее, следующие фрагменты схем являются корректными интерпретациями концептуальной модели. Третья статья этого цикла продолжит процесс усовершенствования вплоть до логического завершения, когда результирующая схема сможет подтвердить пример из XSD Primer.
Концептуальная модель для нашего словаря заказов показана на рисунке 5, она воспроизведена из первой статьи с очень небольшими изменениями. Мы разобъем эту диаграмму на главные структуры и отобразим каждую ее часть на язык W3C XML Schema. Я отмечу несколько случаев, где возможны другие альтернативы, и также укажу, где результирующая схема отличается от примера из XSD Primer.
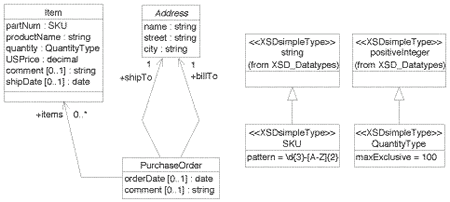
Рис. 5: Концептуальная модель словаря заказов покупок
Класс и атрибут
Класс в UML определяет сложную структуру данных (и соответствующее поведение), которая по умолчанию отображается в complexType в XSD. На первом этапе класс Purchase Order и его UML атрибуты создают следующее определение XML Schema:
<xs:complexType name="PurchaseOrder">
< xs:all>
< xs:element name="orderDate" type="xs:date"
minOccurs="0" maxOccurs="1"/>
< xs:element name="comment" type="xs:string"
minOccurs="0" maxOccurs="1"/>
< /xs:all>
< /xs:complexType>
Атрибуты в UML-классе не имеют заданного порядком, поэтому для создания неупорядоченной группы используется элемент XSD <xs:all>. Кроме того, класс UML создает различные пространства имен для имен своих атрибутов (например два класса могут содержать атрибуты, имеющие одинаковые имена), так что они создаются в схеме как локальные определения элементов. Для более широкого ознакомления с этой темой смотрите A New Kind of Namespace. Оба атрибута в нашей модели UML не обязательны, что показано на Рисунке 1 как [0..1]. Эти значения отображаются в атрибуты minOccurs и maxOccurs в XSD. UML-атрибуты определялись с помощью простейших типов данных из спецификации XSD, так что они записываются прямо в результирующую схему с использованием подходящего префикса пространства имен. Если же в модели UML используются другие типы данных, то для использования этих типов в схеме может быть создана библиотека типов XSD. Например, я создал библиотеку типов XSD для простейших типов языка Java и для простейших классов Java таких, как Date, String, Boolean, и т.д.
Полезно заметить, что элемент верхнего уровня автоматически создается в схеме для каждого complexType. По умолчанию имя для этого элемента такое же как и имя класса, - это возможно в W3C XML Shema, поскольку используются различные пространства имен внутри одной схемы для complexType и для элементов верхнего уровня. Для PurchaseOrder элемент верхнего уровня схемы создается следующим образом:
<xs:element name="PurchaseOrder" type="PurchaseOrder"/>
Если вы обратитесь к примеру в XSD Primer, вы увидите, что orderDate моделируется как XML-атрибут, а не как дочерний элемент PurchaseOrder. Кроме того там используется группирующий элемент <sequence> вместо <all>. И, в-третьих, элемент верхнего уровня определялся в Primer с помощью строчной первой буквы, то есть purchaseOrder (его часто называют форматом "lower camel case"). Здесь я адресую вас к третьей статье, где используется UML profile /*профили*/ для расширения отображений на схемы XML.
Ассоциация
Тип PurchaseOrder в нашей модели определялся не только при помощи атрибутов UML, но также своими ассоциациями с другими классами в модели. На Рисунке 1 показаны три ассоциации, в которых участвует PurchaseOrder. У каждой ассоциации есть роль и мощность, которые точно определяют отношение с целевым классом. Эти ассоциации добавляются к группе complexType в XSD вместе с элементами, созданными из атрибутов UML.
<xs:complexType name="PurchaseOrder">
<xs:all>
<xs:element name="orderDate" type="xs:date"
minOccurs="0" maxOccurs="1"/>
<xs:element name="comment" type="xs:string"
minOccurs="0" maxOccurs="1"/>
<xs:element name="shipTo">
<xs:complexType>
<xs:sequence>
<xs:element ref="Address"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="billTo">
<xs:complexType>
<xs:sequence>
<xs:element ref="Address"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="items" minOccurs="0" maxOccurs="1">
<xs:complexType>
<xs:sequence>
<xs:element ref="Item"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:all>
< /xs:complexType>
Поскольку UML-атрибуты для orderDate и comment имеют простейшие типы данных, схема включает их в себя в качестве содержания элемента. Однако, по умолчанию при отображении для ассоциаций в XSD создаются покрывающие элементы в соответствии с именем роли в UML. Кроме того эти элементы содержат требования к ассоциированному классу, к которому схема обращается при помощи элемента верхнего уровня, созданного для каждого complexType.
Если вы хотите создать W3C XML Schema, используя модель содержания <all>, то покрывающий элемент будет необходим всегда, когда ассоциированный класс имеет более одного случая. Причина в том, что <all> может быть использован только, когда внутренние элементы имеют мощность либо [0..1], либо [1..1]. Так, когда создается покрывающий элемент для ассоциации с Item, элемент, называющийся item, может иметь либо ноль, либо одну реализацию, которая, в свою очередь, содержит ноль, или более элементов Item внутри себя.
Разница между схемой, созданной с помощью правил по умолчанию из UML, и схемой, включенной в XSD Primer в том, что роли shipTo и billTo в Primer содержат прямое указание на адрес, без обращения к элементам ассоциированного класса. Другими словами, дочерние элементы для имени, улицы, города и т.д. содержатся прямо в shipTo и billTo. Этот альтернативный подход мы еще раз дополнительно осветим в третьей статье.
Тип данных, определенный пользователем
По умолчанию при отображении в XSD должно генерироваться определения complexType для SKU и QuantityType, но мы хотим, чтобы это происходило, как определение пользователем простых типов данных в XML-схеме. Этого достаточно просто добиться, добавив UML-стереотип, который показан как <<XSDsimpleType>> на Рисунке 1, в каждый из этих двух классов. Эта возможность включения стереотипов является неотъемлемой частью стандарта UML и используется для формального определения дополнительных характеристик модели, которые, как правило, уникальны для каждой конкретной области, в нашем случае, уникальны для проектирования XML-схемы.
Используя стереотип, генератор схемы знает, как создать следующее определение для SKU:
<xs:simpleType name="SKU">
<xs:annotation>
<xs:documentation>Stock Keeping Unit, a code
for identifying products</xs:documentation>
</xs:annotation>
<xs:restriction base="xs:string">
<xs:pattern value="\d{3}-[A-Z]{2}"/>
</xs:restriction>
< /xs:simpleType>
Кроме того, UML-модель может включать документацию для каждого элемента модели. Такая документация приводится в определении XML-схемы, как показано в этом примере. Обобщенное отношение UML показывает, какие существующие простые типы данных должны быть использованы в качестве основы для определяемого нового типа. В конце концов, атрибут pattern в SKU, отображенный в формат XSD, вынужден принять в качестве значения строку SKU.
Второй модуль в определении схемы purchase order представляет повторно используемый набор формальных определений для адресов (это показано на рисунке 6). Эти определения позаимствованы из раздела 4.1. в XSD Primer. В нашей модели успользуются два дополнительных конструктора схемы, в добавление к использованным при составлении схемы на рисунке 5.
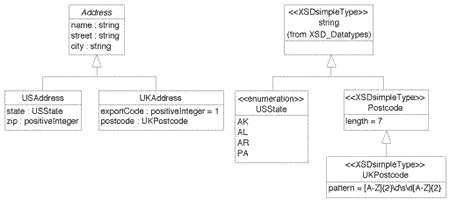
Рис. 6: Компонента схемы Modularized Address
Обобщение
Обобщение - это Фундаментальное и распространенное понятие в объектно-ориентированном анализе и проектировании. Специализированные подклассы наследуют атрибуты и ассоциации от всех родительских классов. Это легко представляется в W3C XML Schema, хотя требует более изощренных механизмов при использовании других языков XML-схем.
На Рисунке 2 класс Address, обозначенный курсивом, использующимся в UML для обозначения абстрактного класса, предназначается только для определения других специализированных классов. Следуя тем же правилам, использующимся по умолчанию для PurchaseOrder, определения complexType для Address и USAddress создаются следующим образом:
<xs:element name="Address" type="Address" abstract="true"/>
< xs:complexType name="Address" abstract="true">
<xs:all>
<xs:element name="name" type="xs:string"/>
<xs:element name="street" type="xs:string"/>
<xs:element name="city" type="xs:string"/>
</xs:all>
< /xs:complexType><xs:element name="USAddress" type="USAddress"
substitutionGroup="Address"/>
< xs:complexType name="USAddress">
<xs:complexContent>
<xs:extension base="Address">
<xs:all>
<xs:element name="state" type="USState"/>
<xs:element name="zip" type="xs:positiveInteger"/>
</xs:all>
</xs:extension>
</xs:complexContent>
< /xs:complexType>
Здесь три отличия от прошлых примеров. Во-первых, элемент верхнего уровня и определение complexType для Address включают XSD-атрибут abstract="true". Во-вторых, элемент USAddress включает в себя substitutionGroup="Address"; это означает, что каждый раз, когда элемент Address запрашивается в качестве элемента содержания, USAddress может быть заменен. Таким образом, мы можем использовать USAdress (или, аналогично, UKAdress), как содержание shipTo и billTo в PurchaseOrder.
В-третьих, определение complexType для USAddress распространяется из основного complexType для Address. В этом и заключается очень серьёзное различие между тем, как эти структуры наследования интерпретируются в UML и, как это происходит в XSD. В UML порядок атрибутов и ассоциаций внутри класса не имеет значения, а в подклассе характерные особенности, наследуемые из родительских классов, свободно перемешиваются с локально определенными атрибутами и ассоциациями. В XSD наследуемые элементы трактуются как группа, так что три элемента, унаследованные из Address представляют из себя неупорядоченную группу в USAddress, и следуют один за другим рядом с другой неупорядоченной группой из двух элементов, определенной в USAddress. Вы не можете определить пятиэлементную группу, когда один или более элемент унаследован.
Перечисляемый тип данных
Элемент state USAddress приписывает определение простого типа для USState. Это определение производится из UML-перечисления. На Рисунке 2 USState показан вместе со стереотипом <<enumeration>>, что извещает генератора схемы о необходимости создать XSD-перечисления для каждого атрибута, определенного для данного класса. Перечисляемый тип в XSD, это всего лишь специализированный вид определений simpleTipe, так что он должен еще указывать суперкласс в UML, чтобы использоваться как базовый тип в XSD. Получается следующая схема:
<xs:simpleType name="USState">
<xs:restriction base="xs:string">
<xs:enumeration value="AK"/>
<xs:enumeration value="AL"/>
<xs:enumeration value="AR"/>
<xs:enumeration value="PA"/>
</xs:restriction>
< /xs:simpleType>
Заключение
Правила отображения по умолчанию, описанные в этой статье, могут быть использованы для создания полной XML-схемы из любой диаграммы классов UML. Это, может быть, ранее существовавшая модель приложения, которая сейчас должна использоваться в рамках архитектуры веб-сервисов XML, или это может быть модель нового XML-словаря, определяемая в качестве стандарта для обмена данными уровня B2B. В любом случае, схема, полученную с помощью этих правил, обеспечивает удобный способ получения первого приближения, которое уже может быть немедленно использована в первоначальном развертывании приложения, хотя и может потребовать некоторой доработки для соответствия другим архитектурным и проектным требованиям.
Первая статья этого цикла посвящена процессу разработки схемы, в ней подчеркивалось различие между созданием для data-ориентированного и для text-ориентированного приложения.Правил отображения по умолчанию часто достаточно для data-ориентированных приложений. Фактически, эти правила соответствуют спецификации OMG XML Metadata Interchange (XML) 2.0 для использования XML в качестве формата обмена моделями. Этот подход еще хорошо реализован вместе с новой инициативой OMG по Model Driven Architecture (MDA).
Text-ориентированные схемы, и любая другая, которая может быть кем-нибудь придумана и использована для содержания для веб-порталов, часто должны быть усовершенствованы, чтобы упростить структуру XML-документов. Например, многие проектировщики схем устраняют покрывающие элементы, соответствующие роли ассоцииации (но это также предупреждает использование группирующего элемента XSD <all>). Эта доработка, а также многие другие, могут быть определены в модели словаря путем помещения нового параметра по умолчанию для одного пакета UML, который затем применяется ко всем содержащимся в нем классам.
В этой статье мы рассмотрели два примера стереотипов UML, которые были созданы, чтобы отметить специализированное использование класса UML. Более обобщенно, эти стереотипы и ассоциированные с ними значения свойств являются частью UML-профиля для XML-схем, который я вначале разрабатывал в рамках моей книги о моделировании приложений XML. Третья статья этого цикла представляет дополнительные примеры использования других стереотипов для уточнения результирующей схемы. Также я предложу вашему вниманию описание инструментов, которые были нами разработаны. Эти инструменты представляют полный UML-профиль для пректирования схемы и преобразования любой модели класса UML либо в W3C XML Schema, либо в грамматику OASIS RELAX NG.
Советы на будущее
Для того, чтобы облегчить вам применение изложенных идей на практике при выполнении собственных проектов, я предлагаю следующие полезные советы.
- План концептуальной модели ваших рабочих словарей может быть использован в нескольких различных контекстах развертывания, т.е. W3C XML Schema, DTD, реляционной DBMS, Java или EJB, и т.д. Альтернативные UML-профили могут быть использованы для трансформации общей рабочей модели на другую платформу. Однако помните, что полная реализация этой цели лежит за пределами возможностей большинства современных инструментов UML.
- Существующие UML-модели могут быть специализированы под конкретную платформу развертывания, библиотеки и типы данных (Java, NET, и т.д.) Изолируйте модель предметной области от конкретной платформы, чтобы иметь возможность ее повторного использования и дальнейшей разработки XML-схем для обмена данными.
- Используйте совместимые правила моделирования для имен и структуры, как в рамках простого словаря, так и для всех родственных моделей. Например, спецификация архитектуры FpML предусматривает нормативы для написания DTD, что делает не сложным переход к UML-моделям или любой другой объектно-ориентированной среде.