Оглавление
- Введение
- Потенциальные преимущества
- Обзор архитектуры
- Логическое хранение
- Физическое хранение
- Индексация
- Язык запросов и оптимизация
- XML-схемы и проверка достоверности
- Поддержка администрирования
- Расширения языка программирования
- Заключение
Введение
Управление новыми форматами данных часто выставляет новые требования. Многие лидеры в сфере информационных технологий обнаружили, что это действительно так, когда дело касается формата Extensible Markup Language (XML).
Очень часто очевидные варианты управления и совместного использования XML-данных их не решают. Файловые системы хороши для простых задач, но они не достаточно масштабируемы, когда необходимо иметь дело с большим количеством документов. Проблемы параллельной работы, восстановления, защиты и простоты использования становятся неуправляемыми. Коммерческие системы управления реляционными базами данных (DBMS) решают их, но терпят неудачу в других областях. Они предлагают два фундаментальных варианта проекта базы данных - хранение каждого XML-документа в цельном виде как один большой объект или "измельчение" его на несколько столбцов, часто на несколько таблиц. Во многих ситуациях эти варианты сталкиваются с проблемами производительности, администрирования, повышения сложности запросов и др. Наконец, работающие только с XML DBMS, представляют новую, в большой степени непроверенную среду в IT-инфраструктуре, поднимая вопросы интеграции, наличия опытного персонала и жизнеспособности.
Версия "Viper" DB2 для платформ Linux, Unix и Windows представляет новый подход. Эта новая бета-версия поддерживает XML-данные как первоклассный тип. Для этого IBM расширила DB2 и включила:
- Новую технологию индексации для ускорения операций поиска в XML-документах;
- Поддержку нового языка запросов (для XQuery), новый графический конструктор запросов (для XQuery) и новые механизмы оптимизации запросов;
- Новую поддержку для проверки достоверности XML-данных на основе предоставленных пользователем схем;
- Новые функции администрирования, включая расширения ключевых инструментальных средств базы данных;
- Интеграцию с популярными интерфейсами прикладного программирования (application programming interface - API).
Важно отметить, что встроенная поддержка XML в DB2 является дополнением к существующей поддержке других технологий, в том числе SQL, табличных структур данных и разнообразных DBMS-функций. В результате пользователи могут создать один объект базы данных, работающий и с "традиционными" SQL-данными, и с XML-документами. Более того, они могут написать один запрос, производящий поиск и интегрирующий обе формы данных.
В данной статье исследуются эти функциональные возможности по мере изучения встроенной в DB2 поддержки XML. Но сначала рассмотрим вопрос, почему так важно правильно управлять XML-данными.
Потенциальные преимущества
С увеличением количества компаний, обращающихся к XML для реализации сервис-ориентированных архитектур (service-oriented architecture - SOA) с целью обмена данными между несовместимыми системами и приложениями и для адаптации к быстро меняющимся бизнес-условиям, многие здравомыслящие IT-лидеры ищут способы эффективного совместного использования, поиска и управления изобилием XML-документов и сообщений, которые генерируют их компании. Новая поддержка XML в DB2 предназначена для минимизации времени и усилий, требуемых для сохранения и использования XML-данных. Это, в свою очередь, может уменьшить стоимость разработки и улучшить бизнес-оперативность.
Например, в статье "Использование встроенной поддержки XML в DB2 с PHP" (developerWorks, октябрь 2005) рассматривается, как новая поддержка XML в DB2 уменьшает сложность разработки базы данных и прикладной программы для поддержки Web-сайта электронной коммерции. Аналогично, в статье "Управление XML для максимальной отдачи" (IBM, ноябрь 2005) рассматривается накопленный опыт, включая сравнительные тестовые сценарии, который тоже показывает потенциальное сокращение рабочего времени и улучшения рабочего цикла.
Что стоит за всеми этими преимуществами? DB2 предоставляет пользователям возможность хранить цельные XML-документы с полной поддержкой в DBMS их внутренней структуры. Это устраняет или минимизирует задачи администрирования и программирования по отношению к другим альтернативам. Более того, может увеличиться скорость операций поиска документов и в документах, а также предоставляется возможность более быстрого приспособления к изменениям бизнес-требований, отраженных в XML-схемах.
Обзор архитектуры
DB2 предоставляет клиентским приложениям возможность работать и с табличными структурами данных, и со структурами XML-данных через язык запросов по выбору - SQL (включая SQL с XML-расширениями, часто называемым "SQL/XML") или XQuery. Как показано на рисунке 1, внутренние компоненты DB2 поддерживают запросы, выполненные на любом языке.
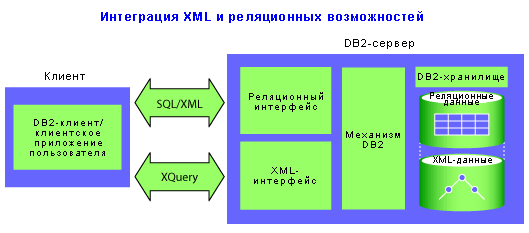
Рисунок 1. Архитектура новой версии DB2 "Viper"
Для эффективного управления традиционными SQL-типами данных и XML-данными в DB2 имеется два различных механизма хранения. Мы вскоре рассмотрим новую технологию хранения XML-данных. Однако необходимо отметить, что внутренний механизм хранения, используемый для конкретного типа данных, прозрачен для приложения. Другими словами, приложению не надо явно указывать, какой механизм использовать или управлять физическими аспектами хранения, например распределением XML-документов по различным страницам базы данных. Приложение просто пользуется преимуществами производительности механизмов хранения и операций запросов данных в формате, эффективном для целевых данных.
Рассмотрим новые XML-функции DB2 с точки зрения пользователя.
Логическое хранение
Наборы XML-документов сохраняются в таблицах DB2, содержащих один или несколько столбцов с новым XML-типом данных. Это позволяет администраторам использовать знакомые SQL-команды языка определения данных (data definition language - DDL) при создании объектов базы данных для хранения XML-данных. Однако этот знакомый интерфейс скрывает то факт, что DB2 хранит XML-данные другим способом, используя новую технологию для сохранения иерархической структуры XML-данных и для поддержки операций поиска по всем или части оригинальных XML-данных.
Для облегчения интеграции пользователями традиционных форм бизнес-данных с XML-данными администраторы DB2 могут создать таблицы, содержащие столбцы как традиционных SQL-типов данных, так и нового XML-типа данных. Вот пример одной такой таблицы:
Листинг 1. Создание таблицы с XML-столбцом
create table items ( id int primary key not null, brandname varchar(30), itemname varchar(30), sku int, srp decimal(7,2), comments xml ) |
Первые пять столбцов этой таблицы используют традиционные SQL-типы данных для хранения информации о каждом товаре для продажи, включая его идентификационный номер, название торговой марки, название товара, единицу хранения (stock keeping unit - SKU) и предлагаемую розничную цену (suggested retail price - SRP). Столбец "comments" содержит XML-данные с отзывами пользователей о данном товаре.
Обратите внимание, что внутренняя структура XML-данных при создании таблицы не указывается. Это сделано умышленно. XML-документы являются самоописываемыми, и их внутренняя структура может варьироваться очень значительно. Единственное требование DB2 для хранения XML-данных состоит в том, что эти данные должны быть "правильно сформированными" - то есть, они должны четко придерживаться определенных синтаксических правил, указанных в спецификации "W3C-стандарт для XML". Либеральный подход DB2 предоставляет пользователям значительную гибкость и облегчает хранение наборов XML-документов, содержащих различные атрибуты и внутренние структуры, зависящие от бизнес-требований или ситуаций, когда определенная информация отсутствует или является несущественной.
Однако, пользователи, желающие гарантировать соответствие этих XML-данных своим собственным структурным правилам, могут указать DB2 проверять достоверность данных перед сохранением. Этот вопрос очень детально рассмотрен в статье "XML-схемы и проверка достоверности". По существу, для этого необходимо создать XML-схемы (тоже являющиеся частью XML-стандарта W3C) и зарегистрировать эти схемы в DB2.
Вам, возможно, интересно знать, как пользователи заполняют таблицу DB2 XML-данными. Ответ прост - они используют один из двух знакомых механизма DB2. Команды SQL INSERT и функция DB2 IMPORT размещают XML-данные вместе с другими типами данных (DB2 IMPORT использует команды INSERT). Если вы зададите вопрос, почему DB2 поддерживает добавление данных только через SQL, а не через XQuery, ответ тоже довольно прост - первая версия появившегося стандарта XQuery концентрировалась на чтении данных, не на записи. В отсутствие общепринятого стандарта IBM предпочла предложить пользователям два знакомых средства для хранения XML-данных.
Физическое хранение
На практике большинству пользователей не нужно беспокоиться о новой архитектуре управления физическим хранением XML-данных. Однако, для лучшего понимания работы DB2, рассмотрим кратко внутренний механизм хранения XML-данных.
DB2 хранит и управляет XML-данными в синтаксически разобранном формате, отражающим иерархическую природу оригинального XML-документа. DB2 использует деревья и узлы в качестве модели для хранения и обработки XML-данных. Если пользователи указывают DB2 проверять достоверность XML-данных по зарегистрированной XML-схеме перед сохранением, DB2 будет аннотировать все узлы в XML-иерархии информацией о типах схемы; в противном случае, узлы аннотируются информацией о типе по умолчанию.
Имея ранее определенную таблицу "items", давайте рассмотрим пример XML-документа, который нужно сохранить в этой таблице. Как показано на рисунке 2, этот XML-документ содержит несколько элементов, представленных иерархически, включая корневой элемент "Comments" и один или более индивидуальных элементов "Comment", принадлежащих данному товару. С каждым элементом "Comment" связан идентификатор, пользовательская информация, которая может содержать субэлементы для имени пользователя и его адреса электронной почты, текст сообщения или комментария пользователя и индикатор того, желает ли пользователь получить ответ.
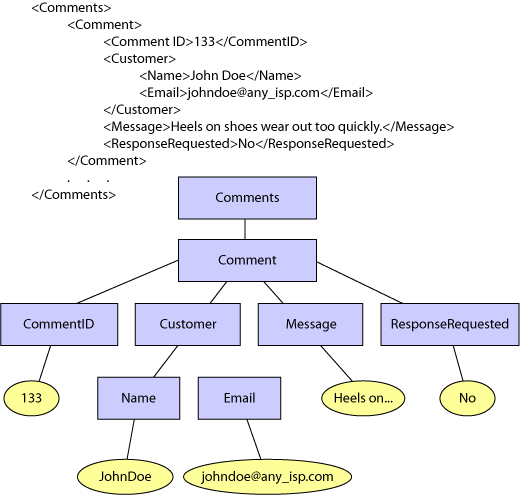
Рисунок 2. Пример XML-документа и его иерархическое представление
При хранении DB2 будет сохранять внутреннюю структуру этого документа, преобразуя имена тегов и другую информацию в целые значения. Это позволяет уменьшить используемое дисковое пространство, а также улучшить производительность запросов, использующих навигационные выражения. Например, DB2 может при сохранении преобразовать тег "Comments" (рисунок 2) в "0". Однако пользователям не обязательно знать об этом внутреннем представлении.
Наконец, DB2 автоматически распределит части документа (то есть, узлы дерева документа) при необходимости по нескольким страницам базы данных. На самом деле DB2 при необходимости может разделить набор (или поддерево) узлов на любом уровне иерархии документа. В таких случаях DB2 автоматически генерирует и поддерживает индекс "regions" для предоставления эффективного средства хранения физического представления всего документа.
Индексация
Вместе с новой поддержкой управления хранением иерархических структур XML-данных DB2 поддерживает новую технологию индексации для ускорения операций поиска по XML-данным. Аналогично их реляционным эквивалентам эти новые XML-индексы создаются знакомыми DDL-командами: CREATE INDEX. Однако, кроме указания столбца индексации, пользователи указывают также "xmlpattern" (по существу, XPATH-выражение без предикатов) для идентификации подмножества нужного XML-документа.
Например, используя определенную ранее таблицу "items" и соответствующий пример XML-документа, показанный на рисунке 2, администратор может выполнить следующую команду для индексирования всех идентификаторов комментария (значений "CommentID"), содержащихся в столбце "comments". Элемент "CommentID" в нашем примере документа является потомком элемента "Comment", который, в свою очередь, является потомком корневого элемента "Comments".
Листинг 2. Создание индекса для XML-столбца
create index myindex on items(comments) generate key using xmlpattern '/Comments/Comment/CommentID' as sql double |
Стоит отметить несколько деталей. Указанный в выражении "xmlpattern" путь чувствителен к регистру символов. То есть, "/Comments/Comment/CommentID" не будет индексировать значения XML-элемента как "/comments/comment/commentid." Более того, поскольку DB2 не требует одной XML-схемы для данного XML-столбца, DB2 может не знать, какой тип данных связан с указанным шаблоном. Пользователь должен явно использовать один из поддерживаемых SQL-типов (VARCHAR, VARCHAR HASHED, DOUBLE, DATE и TIMESTAMP).
Наконец, хотя для создания индекса используется DDL-команда, индекс по XML-данным не такой, как индекс по столбцам с традиционными SQL-типами данных. И хотя детали технологии индексации XML-данных в DB2 выходят за рамки нашей статьи, вы, возможно, заметили два важных отличия:
- Индексы по XML-данным обычно содержат только подмножество содержимого документа (столбца). В отличие от этого, индексы по традиционным SQL-данным всегда содержат полное содержимое столбца.
- Одна строка таблицы может сгенерировать несколько записей XML-индекса, поскольку один XML-документ может содержать ноль, один или несколько "узлов", соответствующих указанному xmlpattern. В отличие от этого, SQL-индексы содержат одну запись для каждой строки таблицы.
Для некоторых приложений может быть критичным полнотекстовый поиск. IBM расширила существовавшие в DB2 возможности текстового поиска, подключив к ним данные, хранящиеся в XML-столбцах. Расширения команды CREATE INDEX позволяют администраторам создавать полнотекстовые индексы для улучшения производительности такого поиска.
Язык запросов и оптимизация
Новая поддержка XML в DB2 включает в себя новые возможности языка запросов. Программисты могут теперь выполнять операцию поиска данных, используя SQL или XQuery - новый язык запросов, поддерживающий навигационные (или основанные на пути) выражения. В действительности приложения могут свободно использовать команды из обоих языков запроса, и одна команда запроса может включать в себя и SQL, и XQuery.
У нас нет времени исследовать широту и глубину всех этих возможностей в данной статье, поэтому рассмотрим только несколько основных. Если вы являетесь SQL-программистом без опыта работы с XML, то будете рады узнать о том, что простой SQL-командой можно извлечь данные, хранящиеся в XML-столбце. Например, эти два знакомых запроса возвратят все данные из таблицы "items", относящиеся к конкретной единице измерения (sku), включая XML-документы с пользовательскими комментариями:
Листинг 3. Запрос XML-данных при помощи SQL
select * from items where sku = 112233 select id, brandname, itemname, sku, srp, comments from items where sku = 112233 |
Теперь рассмотрим немного другую ситуацию, в которой нужно извлечь только сообщения, содержащиеся в пользовательских комментариях таблицы "items", при этом использовать XQuery. Вот наиболее простой способ сформулировать запрос:
Листинг 4. Запрос XML-данных при помощи XQuery
xquery db2-fn:xmlcolumn('ITEMS.COMMENTS')/Comments/Comment/Message
|
Поскольку DB2 поддерживает два языка запросов, пользователи должны указывать ключевое слово "xquery" в качестве префикса для команд XQuery. Функция "db2-fn:xmlcolumn" является одним из способов указания запрашиваемых данных. Она имеет параметр, указывающий XML-столбец желаемой таблицы - в данном случае, столбец COMMENTS таблицы ITEMS. Далее, вы ограничили извлекаемые данные конкретным подмножеством XML-данных, а именно - элементом "Message", который является потомком элемента "Comment", который в свою очередь является потомком корневого элемента "Comments" (см. рисунок 2).
Этот же запрос может быть сформулирован при помощи выражения FLWOR, обычно связанного с командами XQuery. Выражения FLWOR (это неформальный способ ссылки на выражения for, let, where, order by и return) предоставляет возможность программисту выполнять итерации по группам узлов внутри XML-документов и связывать переменные с промежуточными результатами. В данном простом запросе вы можете использовать выражения for и return для извлечения сообщений из пользовательских комментариев, как показано ниже:
Листинг 5. Использование выражений FOR и RETURN в XQuery
xquery for $y in db2-fn:xmlcolumn('ITEMS.COMMENTS')/Comments/Comment
return ($y/Message)
|
Стоит отметить, что DB2 Viper поставляется с Developer's Workbench, основанной на Eclipse программе разработки, включающей в себя графический конструктор XQuery и помогающей пользователям генерировать и тестировать запросы.
SQL и XQuery могут комбинироваться в одной команде для ограничения поиска по XML и SQL-столбцам. Например, рассмотрим следующую XQuery-команду:
Листинг 6. Комбинирование SQL и XQuery в одной команде
xquery db2-fn:sqlquery('select comments from items
where srp > 100')/Comments/Comment/Message
|
Выражение db2-fn:sqlquery ограничивает входную информацию для более широкого выражения XQuery; а именно, в качестве входной информации передаются только пользовательские комментарии, связанные с товарами, имеющими рекомендуемую розничную цену (srp), большую $100. Затем, XQuery-информация указывает, что DB2 должен возвращать только часть "Message" этих комментариев.
Большое количество статей и Web-сайтов могут помочь вам в освоении расширений DB2 SQL/XML, поддержки XQuery в DB2 и появляющегося стандарта по XQuery.
Наконец, вы, наверное, хотели бы узнать о связанной теме: оптимизации запросов. DB2 имеет два синтаксических анализатора языков запроса: один для XQuery и один для SQL. Оба генерируют общее, независимое от языка внутреннее представление запросов. Это означает, что запросам, написанным на любом языке, предоставлены все преимущества ценных механизмов оптимизации запросов DB2, которые включают эффективную перезапись операторов запроса и выбор наилучшего плана доступа к данным. Кроме того, DB2 может воспользоваться новыми операторами запроса и соединения, а также новыми механизмами обработки индексов, для обеспечения высокой производительности запросов, содержащих XML-документы.
XML-схемы и проверка достоверности
Гибкая природа XML иногда беспокоит разработчиков баз данных, которые заботятся о качестве данных. Как уже упоминалось, DB2 позволяет пользователям хранить любой "правильно сформированный" XML-документ в любом столбце, определенном с новым XML-типом данных. Таким образом, один столбец может содержать документы с разной структурой (или схемами) и с разным содержимым. Когда природа данных неясна или трудна для предсказания, такая гибкость может быть абсолютной необходимостью. Но в других случаях она может быть источником неприятностей. Вот почему DB2 предоставляет пользователям возможность регистрировать их XML-схемы и указывать DB2 проводить проверку достоверности XML-документов согласно этим схемам перед сохранением.
Для тех, кто не знаком с XML-схемами, объясним, что это - просто правильно сформированные XML-документы, описывающие структуру и содержимое других документов. Например, XML-схемы указывают, какие элементы разрешены, в каком порядке эти элементы должны появляться в документе, какие XML-типы данных связаны с каждым элементом и т.д. Создать XML-схему из существующих XML-документов можно при помощи различных инструментальных средств, в том числе IBM WebSphere Studio и продуктов Rational.
Пользователи могут решить хранить различные XML-документы, соответствующие различным зарегистрированным схемам, в одном столбце. Это важно, поскольку возникающие бизнес-требования могут влиять на структуру и содержимое обрабатываемых XML-данных. Рассматривая нашу таблицу "items", предположим, что через несколько месяцев после развертывания этой таблицы вы решили собрать дополнительную информацию в XML-столбец, например, более подробную информацию о пользовательских адресах для контактов, запись о предпринятых действиях в ответ на определенные комментарии и т.д. DB2 может приспособиться к этим новым улучшениям без необходимости изменения пользователем структуры таблицы или какого-либо приложения, ее использующего. Существующие данные (основанные на "старой" XML-схеме) могут оставаться на своих местах, а новые данные могут быть добавлены в соответствии с одной или несколькими новыми схемами. Таким способом администраторы могут поддерживать новые бизнес-требования с минимальным временем развертывания и стоимостью. Более того, для этого им не требуется подвергать риску целостность своих XML-данных - можно просто обеспечить DB2 новой информацией о том, что "правильно" для XML-данных.
Регистрация XML-схемы во внутреннем репозитории DB2 проста. DB2 предоставляет хранимые процедуры для автоматизации процесса, либо администраторы могут вручную выполнить соответствующие команды. При желании одна схема может быть использована для проверки на достоверность нескольких XML-столбцов в нескольких таблицах.
Поддержка администрирования
Новая поддержка XML в DB2 включает расширения знакомых инструментальных средств и программ, помогающих администраторам управлять и настраивать свои базы данных. Например, функции резервного копирования и восстановления (в том числе широкодоступная репликация данных для восстановления после отказа) поддерживают документы, хранящиеся в XML-столбцах. Аналогичным образом расширения функций IMPORT и EXPORT теперь работают и с традиционными SQL-данными, и с XML-данными. То есть, вы можете выполнить одну команду IMPORT для заполнения таблицы "items" полностью (читая XML-данные из оригинальных файлов), а также выполнить команду EXPORT для записи всех данных таблицы во внешние файлы.
Кроме того, графическая программа администрирования DB2 (DB2 Control Center) предоставляет администраторам возможность просматривать таблицы, содержащие XML-данные, создавать и управлять основанными на XML-данных индексами, выполнять команды SQL/XML и XQuery, а также большое число других задач по администрированию. Поскольку производительность часто является основной целью, соответствующие возможности DB2 были тоже расширены для работы с XML-данными. К ним относятся: DB2 Snapshot Monitor, обеспечивающий временные срезы, или "мгновенные снимки", активности DB2; RUNSTATS, собирающая статистику о природе данных, хранимых в базе данных DB2; EXPLAIN, составляющий отчеты по тому, каким способом оптимизатор запроса выбирает данные для выполнения данного запроса. Исследование информации от EXPLAIN дает возможность администратору определить, какие используются XML-индексы.
Расширения языка программирования
Новая поддержка XML в DB2 не была бы очень полезна, если бы XML-данные, хранящиеся в базах данных, не были доступны для программистов. Осознавая это, IBM реализовала улучшения различных интерфейсов языка программирования для поддержки простого доступа к XML-данным. Эти улучшения распространяются на Java™ (JDBC), C (встроенный SQL и интерфейс уровня вызовов), COBOL (встроенный SQL), PHP и на среду Microsoft® .NET (через провайдер DB2.NET).
Поскольку API отличаются в зависимости от используемого языка программирования, мы не будем здесь рассматривать каждое из этих расширений. Однако вы можете ознакомиться с итоговой информацией по этим расширениям в ранее опубликованной статье "Внутренняя поддержка XML в DB2 Universal Database", либо прочесть статью "Использование встроенной поддержки XML в DB2 с PHP".
Заключение
Версия DB2 Viper является первой реализацией IBM гибридной или многоструктурной системы управления базами данных. Кроме поддержки табличной модели данных DB2 поддерживает также иерархическую модель данных, свойственную XML-документам и сообщениям. Пользователи могут свободно смешивать при хранении традиционные SQL-данные и XML-данные в одной таблице. Они могут также запрашивать и интегрировать обе формы данных при помощи SQL (при желании с XML-расширениями) и XQuery, разрабатывающегося стандарта для запроса XML-данных. Создавая проверенную инфраструктуру управления базами данных, IBM обеспечивает пользователей DB2 Viper развитой поддержкой как реляционных, так и XML DBMS технологий.