Существуют ли ошибки в программах на C/C++, разработанных для платформ UNIX? Я думаю, мы все знаем ответ на этот вопрос. Вообще говоря, разработчики под UNIX встречаются с теми же проблемами, что и их коллеги работающие в среде Windows: синтаксические и логические ошибки, ошибки распределения и освобождения памяти, узкие места производительности и так далее. Список длинный, и каждый элемент в нем может отнять у разрабочтика большое количество времени, прежде чем приложение будет готово к доставке заказчику. Единственный путь тестирования C++ - приложений под UNIX для поиска проблем, связанных с динамическим распределением памяти - отладка во время исполнения. В этой статье я представлю решение для подобной отладки программ, которое совмещает один из популярных отладчиков - GNUGDB - с автоматизированной средой для определения ошибок, связанных с распределением и освобождением памяти: RationalPurify(В соответствии с Web-сайтом GNU «Проект GNU был начат в 1984 г. для разработки полной Unix-подобной бесплатной операционной системы: системы GNU»).
Оглавление
- Подготовка приложения к отладке
- Обработка приложения с помощью Rational Purify
- Запуск отладчика GDB
- Пример приложения
- Отладка приложения, подготовленного с помощью Rational Purify
- Детальная проверка и тестирование приложения с помощью Rational Purify и отладчика GDB
- Преимущества отладки при совместном использовании GDB и Rational Purify
- Комбинация Rational Purify с отладчиком экономит время и деньги
Ошибки памяти и определение ошибок с помощью RationalPurify
Языки программирования C и C++ позволяют разработчику динамически распределять и освобождать память, используя соответствующий API. Основной функцией распределения памяти в C во время исполнения является malloc(). Распределение памяти с помощью malloc() легко осуществимо: функция malloc() определяет тип и размер структуры, которая должна быть распределена в динамической области памяти, переданной ей в качестве параметра. В результате вызова функции malloc() система распределит запрошенный участок памяти (если доступно достаточное ее количество) и возвратит ссылку на этот участок в виде указателя на распределенную область памяти.
Удобство динамического распределения памяти в C и C++ состоит в том, что язык программирования предоставляет вам прямой доступ к памяти, позволяет изменять ее размер, перемещать, копировать и освобождать во время исполнения приложения. Однако важно иметь в виду, что этими мощными механизмами работы с памятью следует пользоваться с осторожностью.
Сбои при освобождении памяти
Наиболее типичная ошибка, которую вы можете совершить, работая с динамической памятью, - это забыть освободить ресурсы после того, как они больше не нужны. Память, распределенная с помощью malloc(), может быть возвращена системе с помощью API: вызова функции free() . Если память распределена с помощью malloc(), например, в цикле, и приложение является системным сервисом, что предполагает его работу без перезапуска в течение длительного времени, тогда «утечка» памяти может легко привести к переполнению памяти или даже сбою всей операционной системы.
К сожалению, этот сценарий, похоже, слишком часто встречается в реальности. Вот почему некоторые поставщики серверов, такие как IBM, поставляют свои сервера с приложениями для «омолаживания ПО»; они могут определять, когда работающее приложение вызывает переполнение памяти и перезапустить его до того, как оно захватит все доступные ресурсы других параллельно работающих приложений,, и приведет к сбою операционной системы.
Ошибки записи и чтения памяти за границами выделенной области
Другой очень серьезной ошибкой работы с памятью является чтение и запись за границами выделенной области памяти (out-of-bounds). Эта ошибка встречается тогда, когда вы обращаетесь в режиме чтения или записи к участку памяти, который лежит за пределами распределенной области памяти. Например, если у вас есть строка stringA, которая состоит из десяти символов, и вы пытаетесь скопировать ее в участок памяти, выделенный под строку stringB из пяти символов, тогда пять дополнительных символов будут записаны за концом участка памяти, выделенного под строку stringB. То же самое случится, если вы просто неправильно индексируете массив. Положим, у вас есть массив из десяти целых, а вы пытаетесь получить доступ к пятнадцатому элементу массива. Языки C/C++ позволяют вам сделать это, так что вы не заметите этой ошибки до тех пор, пока копируемая строка не испортит какие-нибудь корректные данные за границами распределенной области памяти. Однако следует помнить, что вы можете не ощутить последствий этой ошибки за один прогон (может даже и за сотню прогонов), но рано или поздно ошибка уничтожит какие-нибудь важные данные, и приложение будет разрушено. Скорее всего, сбой произойдет через длительный период времени после того, как приложение будет поставлено заказчику, но это может случиться в любой момент.
Другие ошибки работы с памятью
Кроме «утечки» памяти и ошибок записи и чтения за границами выделенной области, существуют и другие важные ошибки, связанные с работой с памятью:
-
Доступ к неинициализированной памяти. Этот тип ошибок встречается, когда вы осуществляете доступ по чтению к неинициализированному участку памяти. Эта память распределена программе, но не инициализирована. Примером может служить память, распределенная с помощью malloc() . Для ее инициализации мы должны выполнить memset(), в противном случае содержимое памяти не определено.
-
Доступ к уже освобожденной памяти. Эта ошибка появляется при использовании указателя на участок памяти, которая была освобождена или перераспределена. Память уже возвращена операционной системе, но указатель продолжает адресовать ее и приложение может ошибочно попытаться ее использовать.
-
Некорректное освобождение или перераспределение. Это происходит при попытке приложения освободить или перераспределить ( realloc ) память, которая уже была освобождена, или не была предварительно распределена. Некорректное освобождение так же встречается при несогласованном использовании функций распределения и освобождения. Например, распределение с помощью new() , с последующим освобождениемё с помощью free() . Правильным в этом случае будет освобождение с помощью delete() .
К сожалению, эти ошибки памяти трудно определяются, даже при использовании отладчика. Для реальной проверки всех ошибок памяти, вы должны трассировать исполнение программы в отладчике, рассматривая каждое обращение к памяти для определения, корректно оно или нет.
Вот почему вам нужна система RationalPurify. Она сделает все это для вас автоматически и сообщит об ошибках обращений к памяти во время работы приложения. Purify отслеживает ошибки памяти с помощью отметки каждого байта распределенной памяти специальным шаблоном битов. Вся память, используемая приложением, классифицируется и помечается цветами, как показано на Рисунке 1.
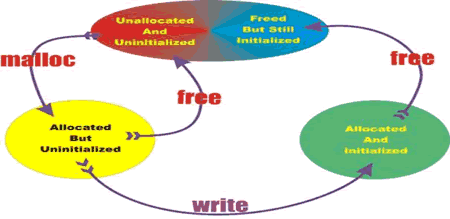
Рис. 1. Цвета, используемые RationalPurify при классификации состояний памяти.
В зависимости от состояния памяти и операции, которую хочет выполнить программист, Purify сообщит об ошибке или выдаст предупреждение. Если операция корректна, исполнение программы после этого продолжится.
В качестве примера рассмотрим массив, распределенный с помощью malloc() :
char *string2 = malloc(10);
Если программа пытается читать содержимое этой строки без предварительной инициализации, Purify немедленно сообщит о чтении из неинициализированного участка памяти - UMR (UninitializedMemoryRead). Бит состояния установится в «желтый цвет» для распределенной, но не инициализированной памяти. Если вы осуществляете запись в распределенную память, помеченную желтым, бит состояния изменится на «зеленый цвет», который соответствует распределенной и инициализированной памяти. «Красная» память не была ни распределена, ни инициализирована приложением. Каждая попытка доступа к этой памяти приведет к ошибке. Если программа пытается читать из этой памяти, Purify сообщит об ошибках доступа, таких как ABR (ArrayBoundsRead - чтение за границами массива), ZPR (ZeroPageRead - чтение из нулевой страницы), NPR (NullPointerRead - чтение по пустому указателю), IPR (InvalidPointerRead - чтение по некорректному указателю) и т.п., в зависимости от типа памяти, к которой осуществляется доступ. Так же Purify будет реагировать на попытки записи в эту память.
Различные комбинации состояний (цвета) и операций с памятью будут приводить к различным сообщениям об ошибках в Purify.
Подготовка приложения к отладке
GDB представляет собой бесплатный отладчик GNU. Длинный список его возможностей и его доступность, сделали его очень популярным среди разработчиков под UNIX. Вместе с бесплатным компилятором GCC, он обеспечивает надежную основу для гарантии качества приложений, написанных на C/C++. GDB может использоваться совместно с RationalPurify для тщательного анализа приложений на наличие «утечек» памяти и ошибок работы с памятью. Как отладчик, так и Purify используют символьную отладочную информацию для управления контрольными точками и привязки машинного кода к исходным файлам тестируемого приложения. Для генерации отладочной информации вам необходимо использовать опцию (-g) при компиляции исходных кодов с помощью компилятора GCC:
gcc -g helloEdge.c
Обработка приложения с помощью RationalPurify
RationalPurify необходимо вставить дополнительные инструкции языка ассемблера в вашу программу для контроля ее исполнения и мониторинга распределения памяти после ее старта. Ниже приведен пример того, как это делается:
purify gcc -g helloEdge.c
Когда вы запустите обработанный таким образом исполнимый модуль, тестируемая программа - PUT (ProgramUnderTest) автоматически запустит графический интерфейс Purify (GUI - GraphicalUserInterface) и начнет собирать информацию о выполнении.
Вы можете запустить отладчик GDB из командной строки с помощью команды gdb. Как только GDB запущен, вы можете вводить команды отладчика. Простейший способ запуска вашего приложения в отладчике GDB - это использование его имени в качестве параметра запуска:
gdb ./a.out
Наш пример - это простенькая программа "Hello, RationalEdge", которая ничего особенно не делает, кроме создания нескольких ошибок, трудно обнаруживаемых без специализированных средств типа RationalPurify.
int main(void){int i, length;char *string1 = "Hello, theEdge";char *string2 = malloc(10);length = strlen(string2); // UMRfor (i = 0; string1[i] != '\0'; i++) {string2[i] = string1[i]; // ABW's}length = strlen(string2); // ABRprintf("\nHello");printf("\n");return 0;}
Что здесь неправильного? Опытный глаз разработчика на С/C++ возможно сразу заметит некоторые очевидные ошибки, даже не зная аббревиатур, используемых в комментариях. Однако если вы откомпилируете и запустите это приложение, ни компилятор, ни система не сообщат об ошибках. Будет казаться, что приложение работает нормально.
А что если бы это была программа из тысяч строк кода? Может ли опытный глаз разработчика помочь в этом случае? Я сомневаюсь. Даже средства статического анализа не смогут обнаружить ошибки, похожие на ошибки в нашем примере. Вам придется исполнить программу, чтобы выловить все проблемные участки.
Первая ошибка - чтение из неинициализированного участка памяти. Мы распределили память под строку и читаем из распределенного участка памяти без присвоения какой-либо строки этому участку памяти.
Вторая ошибка - запись за пределами массива (ABW - ArrayBoundsWrite), относящаяся к типу ошибок выхода за пределы памяти (Out-of-Bounds). Программа пытается скопировать строку длиной в пятнадцать символов (включая символы конца строки) - "Hello, theEdge" - в область памяти, распределенную с помощью malloc() , которая предназначена только для десяти символов. Это значит, что «лишние» символы первой строки перезапишут исходные символы конца строки, и запись продолжится за границами распределенной памяти.
Третья ошибка (Out-Of-BoundsRead) заключается в чтении из той же строки, границы которой мы уже нарушили.
Кроме того, мы имеем «утечку» памяти из-за динамического распределения массива String2 , поскольку мы не вызываем free() для строки, распределенной с помощью malloc() , для освобождения распределенной памяти и возвращения ее в систему.
Работа с подготовленным приложением в GDB ни чем не от работы с исходной, неподготовленной версией тестируемой программы. Исполнение приложения начинается с помощью команды " r ".
Если вы не выбирали каких-либо специфических условий выполнения, приложение будет работать без прерываний и Purify сообщит о трех ошибках, только что описанных выше (см. Рисунок 2).
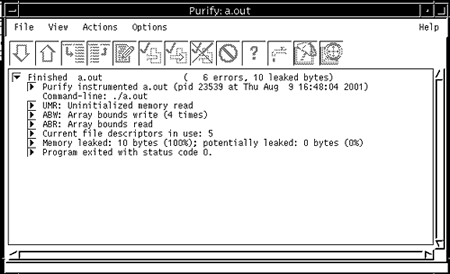
Рис. 2. Подготовленная программа, работающая в среде RationalPurify
Во время исполнения приложения, в отладчике, или самостоятельно, Purify собирает информацию и отображает ее, в режиме времени, близком к реальному. На Рисунке 3 показан первый отчет о чтении из неинициализированной области памяти (UMR).
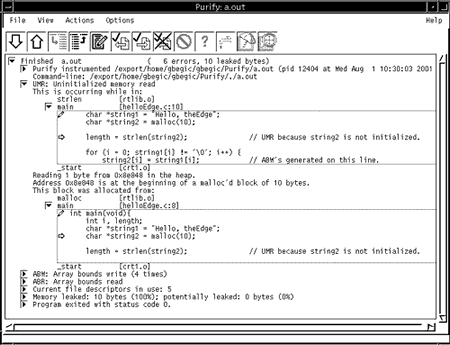
Рис. 3. Отчет Purify об ошибке UMR.
Как показано на этом экране, Purify корректно определила попытку чтения неинициализированной памяти, и указала в сообщении на месте в исходном файле, где этот вызов был осуществлен. Здесь так же показана строка, где массив был распределен.
Если вы продолжите выполнение, следующий отчет будет сходным: будут показаны местоположение ошибки и место распределения памяти, не оставляющие сомнений об ошибке работы с памятью во время исполнения. Это действительно важно, так как иначе приложение будет работать «нормально» большую часть времени, мы можем не обнаружить ошибку записи в память за рамками границ (ABW - Out-of-BoundsWrite), как не сможем и предсказать, когда это реально приведет к затиранию корректных данных и вызовет сбой.
Рисунок 4 показывает отчет об ошибке ABW. В цикле for() приложение копирует элементы массива из десяти символов в память, распределенную для массива из пяти символов. Этот тип ошибок очень опасен и не должен оставаться в приложении, особенно в версии, отправляемой заказчику.
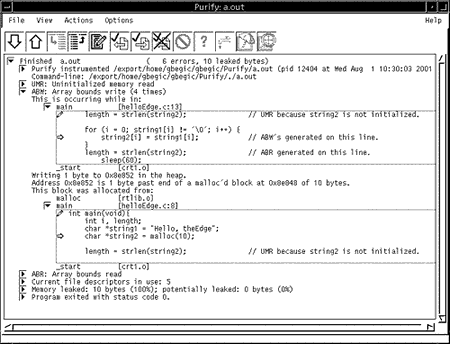
Рис. 4. Отчет об ошибке ABW в Purify
Детальная проверка и тестирование приложения с помощью RationalPurify и отладчика GDB
Теперь, если вы хотите просмотреть каждый фрагмент приложения (а вы должны это сделать!), вы можете совместно использовать отладчик GDB и Purify. Эти инструменты похожи, но вместе они дадут вам даже больше информации, чем вы можете получить, запуская каждый из нихпо отдельности.
Установка контрольных точек в отладчике
Контрольные точки - очень важный инструмент, используемый при отладке. Контрольная точка - это специальная команда, вставляемая пользователем в код. Когда эта команда достигает процессора, исполнение останавливается точно на этой команде и пользователь может просмотреть содержимое стека, регистров и памяти. Для работы с контрольными точками программа должна быть скомпилирована с опцией -g для создания символьной отладочной информации. Контрольная точка может быть установлена в определенную строку кода. Например:
(gdb) break 10
Эта инструкция предписывает приложению остановить выполнение на десятой строке исходного кода.
Для начала исполнения приложение должно быть запущено в отладчике GDB. Для этого служит команда ' r ' (run).
(gdb) r
Подготовленное приложение стартует, запустит Purify, и остановится в контрольной точке.
После остановки в указанной строке кода, или при вызове функции, становится возможным запросить значение конкретной переменной. Например:
(gdb) print string1
Вы можете продолжить исполнение подготовленного приложения с помощью команды 'c' (от continue - продолжить).
(gdb) c
Другой способ установки контрольных точек заключается в указании имени функции, при вызове которой приложение должно остановиться. Например:
(gdb) break main
Эта команда приведет к остановке приложения при вызове функции main(). Вместо установки контрольной точки на вызов функции или в строку кода, вы можете установить ее на конкретный адрес. Кроме того, вы можете поставить дополнительные условия для контрольной точки. Полный синтаксис выражения для этих случаев будет выглядеть следующим образом:
(gdb) break <line number, or function name> <additional condition>
И в завершение, вы можете использовать следующую команду для удаления всех контрольных точек:
(gdb) delete
За подробными инструкциями по работе с контрольными точками обратитесь к руководству по отладчику GDB, указанному в Библиографии.
Подключение к отладчику GDB во время исполнения
Вы можете модифицировать приложение таким образом, что оно не будет прекращать работу автоматически, путем добавления следующей строки кода, например:
sleep(30);
Это позволит вам приостановить выполнение приложения в этой точке, предоставив достаточно времени для подключения к отладчику GDB во время исполнения. В действительности, это может понадобиться для программ, работающих в качестве сервисов в течение длительного периода времени.
Я добавил эту строку в наш небольшой пример "Hello, RationalEdge", перекомпилировал и повторно подготовил приложение. Так как нам нужен PID (Processidentifier - идентификатор процесса) для подготовленного приложения, мы запустим программу с помощью следующей команды:
./a.out &
В результате мы получим PID. В данном случае:
[1] 15050
После этого, если мы запустим отладчик GDB и передадим ему PID работающей программы, мы подключим отладчик GDB к процессу, имеющему указанный ID (идентификатор) и сможем продолжить тестирование (устанавливая контрольные и сторожевые точки, как и раньше):
gdb ./a.out 15050
Преимущество отладки при совместном использовании GDB и RationalPurify
В то время как мы запускали наше приложение "Hello, RationalEdge" в отладчике GDB, система RationalPurify собирала данные о ходе исполнения. Это не единственный способ совместного использования Purify с отладчиком GDB. Не много ниже я опишу некоторые менее известные, но мощные функции Purify, которые могут оказаться очень полезными при тестировании вашего ПО для обнаружения ошибок работы с памятью.
Использование функций APIRationalPurify
APIPurify включает функции, которые могут вам помочь при отладке и диагностике ошибок работы с памятью.
Вызов функций APIPurify из отладчика GDB. Некоторые функции API предназначены для вызова из отладчика. Например:
purify_stop_here()
В отладчике GDB вы можете вызвать эту функцию с помощью следующей команды GDB:
(gdb) break purify_stop_here
После этого API установит контрольную точку на вызов любого отчета Purify об ошибке. В нашем примере первая остановка программы произойдет в момент выдачи сообщения Purify об ошибке UMR.
Если вы остановите выполнение в этой контрольной точке и посмотрите стек вызовов, это подкрепит отчет Purify показом функций, вызванных в момент обнаружения ошибки. Содержимое стека вызовов в GDB можно просмотреть с помощью команды bt:
(gdb) bt#0 0x535d4 in purify_stop_here ()#1 0x413a4 in strlen ()#2 0x5710c in main () at helloEdge.c:10
Давайте рассмотрим другой пример функции API, которая может быть вызвана из отладчика.
purify_describe(addr)
Эта функция сообщит, как Purify рассматривает данный фрагмент памяти: как «глобальные данные» (globaldata), как «содержимое стека» (onthestack) или как «X байт, начиная с распределенного блока по адресу Y». В отладчике GDB вызов этой функции может быть объединен с командой print. Например:
(gdb) print purify_describe(addr)
Вызов функций APIPurify из вашего приложения. Для вызова функции из приложения вам понадобится включить файл заголовков (Purify.h) в ваш проект. Этот файл заголовков находится в домашнем каталоге продукта, и путь к нему вы можете получить с помощью команды:
purify -printhomedir
В этом каталоге находится и библиотека заглушек APIPurify (purify_stubs.a).
#include<purify.h>
Вы можете использовать библиотеку заглушек APIPurify при редактировании связей вашего приложения, чтобы избежать необходимости условной компиляции.
Вот несколько примеров функций API, которые могут быть вызваны из вашего приложения:
|
purify_is_running - |
Возвращает TRUE (истина) если программа приготовлена для работы с Purify. |
|
purify_printf (_with_call_chain) - |
Записывает сообщение в журнал (с информацией о стеке вызовов). |
|
purify_new_leaks / purify_new_inuse - |
Сообщает объем утерянной/занятой памяти со времени последнего вызова. |
Установив специальные сторожевые точки (watchpoint) в Purify вы можете отслеживать конкретные типы операций доступа к памяти. Использование сторожевых точек может оказаться очень полезным в ситуации, когда память мистическим образом изменяется между моментом инициализации и моментом использования. Когда сторожевые точки установлены, Purify автоматически сообщает о точной причине и результатах каждой операции доступа к памяти.
Существуют четыре причины, по которым сторожевые точки Purify предпочтительнее сторожевых точек отладчика. Сторожевые точки Purify:
-
Работают быстрее - так как получаются «бесплатно» во время работы Purify.
-
Могут определять операцию доступа к памяти (например, чтение; нет необходимости писать в память).
-
Могут быть установлены в вашей программе путем использования API сторожевых точек.
-
Могут обеспечить больше информации. Например, вы можете обнаружить, когда адрес стека находится внутри и вне границ стека.
Наш пример "Hello, Rational Edge" так мал и тривиален, что нам в действительности не нужны сторожевые точки для понимания того, что случается в ходе исполнения программы. Но давайте посмотрим на следующий фрагмент кода:
Object * myObject = NULL ; // global pointerint main(){myObject = create();result = compute(myObject);report(result);destroy(myObject);return 0;}
Для разработчика, отвечающего за этот фрагмент, следующий сценарий может быть реальной проблемой. Предположим, мы запускаем нашу программу в Rational Purify и Purify сообщает об «утечке» памяти для объекта - несмотря на то, что мы уничтожили объект myObject в функции destroy() .
Нам необходимо использовать отладчик для анализа конкретных событий, приведших к утечке памяти. С помощью отладчика мы можем определить, например, что объект myObject уже был уничтожен (указатель - NULL) в момент вызова destroy() ! Так что же случилось с глобальным указателем на " myObject " в этой программе?
#include "purify.h" // header file for Purify APIObject * myObject = NULL ; // global pointerint main(){if (purify_is_running() ) {purify_watch_n(&myObject, 4, "w") ;}myObject = create_object();result = compute(myObject);report(result);destroy(myObject);return 0;}
Простой и элегантный способ ответить на этот вопрос заключается в установке сторожевых точек Purify в коде, которые остановят исполнение в момент удаления глобальной ссылки на объект. После установления сторожевой точки, которая будет останавливать исполнение каждый раз при изменении указателя на myObject, мы можем ожидать, что сторожевая точка остановит исполнение на операторе myObject = create_object() , так как в этой строке мы создаем наш объект.
Если у нас ошибка в функции compute() , например, за счет преждевременного обнуления указателя на объект, без предварительного уничтожения объекта, то Purify будет корректно сообщать об утечке памяти - даже если мы создали функцию уничтожения объекта. Эта ошибка будет обнаружена практически мгновенно при неожиданной остановке на сторожевой точке в функции compute() . Строка кода, вызвавшая ошибку, сама по себе может не вызывать никаких подозрений. Разработчик может обнулить ссылку на объект до его уничтожения в строке MyObject = NULL; .
Сторожевая точка Purfy приведет нас прямо к источнику проблемы, как показано на Рисунке 5.
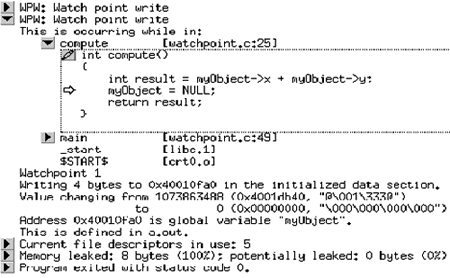
Рис. 5. Отчет Rational Purify о неожиданном срабатывании второй сторожевой точки Purify.
Rational Purify позволяет вам подавить сбор и отображение определенных сообщений в окне просмотра. Это может быть полезно если:
-
У вас есть ошибки, которые вы не можете исправить, такие как ошибки в библиотеках сторонних производителей, исходные коды которых недоступны.
-
Вы хотите сконцентрироваться только на специфических ошибках. Например, если вы хотите спрятать информацию об известных ошибках, что бы новые ошибки было легче увидеть.
-
Вы хотите спрятать сообщения о безобидных, известных ошибках, таких как небольшая однократная утечка памяти.
Есть несколько способов выполнить это подавление:
-
Путем активации подавления в окне просмотра.
-
Путем спецификации подавления прямо в файле .purify.
-
Путем использования опции " -suppression-filenames. "
Положим, у вас есть программа, иногда использующая счетчик (counter):
if (use_the_counter)object.counter = counter_initialize();object.counter++;if (use_the_counter)return object.counter;elsereturn 0;use_the_counter - логическая переменная, имеющая только два состояния: "true" или "false."
В этом кусочке кода мы инициализируем счетчик только при условии "true"; если условие ложно (false) тогда мы читаем из него. Это создаст ошибку UMR, в случае если use_the_counter равно "false." Но в действительности это не ошибка и это является хорошим кандидатом для подавления.
Некоторые ошибки подавлены по умолчанию. Например, Purify отличает общие операции чтения неинициализированной памяти от чтения неинициализированной памяти только для создания копии. Такие сообщения о копировании неинициализированной памяти (UMC - Uninitialized Memory Copy) подавляются по умолчанию. Если позже вы будете использовать эту копию, Purify сгенерирует сообщение UMR.
Вот пример сообщения UMR:
/* Suppose arg_ptr points to uninitialized memory */void SomeFun(int *arg_ptr) {int local = *arg_ptr; /* UMC (suppressed) */printf("value is %d\n", local); /* UMR here */}
Если вы хотите видеть эти сообщения в Purify, тогда вам нужно включить режим " View/Suppressed Messages. "
Комбинация RationalPurify с отладчиком экономит время и деньги
Процесс отладки приложения не должен ограничиваться использованием отладчика для обнаружения причин известных проблем. Использование средств автоматического обнаружения ошибок времени исполнения и утечки памяти, таких как RationalPurify может помочь вам обнаружить и зафиксировать ошибки работы с памятью, трудно поддающиеся диагностике. Комбинируя такие средства с отладчиком, вы можете сделать задачу отладки программ проще и сэкономить для вашей команды разработчиков, как время, так и деньги.
Библиография