Если вы собираетесь работать с проектами, связанными с обработкой больших объемов данных и опирающимися на применение IBM InfoSphere BigInsight, то вам будет важно изучить основы извлечения, обработки и анализа этих данных. Настоящая статья познакомит вас с простыми примерами формирования запросов данных, которые покажут, как считывать, записывать, фильтровать и уточнять структурированные данные и данные, полученные из социальных сетей. Кроме того, вы узнаете, как бизнес-аналитики могут визуализировать результаты запросов с помощью инструмента в стиле электронных таблиц.
Работа с данными больших объемов часто требует применения запросов, позволяющих извлекать интересующую вас информацию и обрабатывать ее различными способами. В этой статье вы познакомитесь с Jaql - языком запросов и сценариев, предлагаемым в InfoSphere BigInsights. Кроме того, вы узнаете, как формировать запросы к данным, полученным из социальных сетей, и объединять эти данные с информацией, извлеченной из систем управления реляционными базами данных (СУРБД).
Введение
InfoSphere BigInsights - это программная платформа, предназначенная для поиска и анализа информации, скрытой в больших объемах разнородных данных, которые часто игнорируются или отбрасываются из-за непрактичности или сложности их обработки с использованием традиционных средств. Примерами таких данных являются журналы событий, данные о посещаемости сайтов, данные социальных сетей, ленты новостей, выходные сигналы электронных датчиков и даже некоторые транзакционные данные.
Призванная помочь компаниям в эффективном извлечении ценной информации из таких данных корпоративная версия пакета BigInsights содержит несколько проектов с открытым исходным кодом (включая Apache™ Hadoop™) и разработанные корпорацией IBM технологии. Hadoop и дополняющие его проекты предлагают эффективную программную среду для приложений, работающих с большими объемами данных, которая использует распределенную вычислительную среду для достижения высокой степени масштабируемости. Технологии IBM обогащают эту среду с открытым исходным кодом, добавляя в нее аналитическое ПО, интеграцию с корпоративным ПО, расширения платформ и инструменты.
Настоящая статья познакомит вас с базовыми возможностями формирования запросов, предлагаемыми BigInsights через Jaql - язык запросов и сценариев, использующий модель данных на основе JavaScript Object Notation (JSON). И хотя Jaql не является единственным способом формирования запросов к данным, управляемым базовой или корпоративной версией BigInsights (например, можно использовать Hive или Pig), он отлично работает с переменными структурами данных, включая структуры данных с большой глубиной вложенности. Кроме того, BigInsights содержит модуль Jaql для доступа к источникам данных, поддерживающим JDBC. Такие возможности особенно полезны в нашем сценарии, который включает анализ небольших наборов данных социальных сетей, собранных в виде записей JSON, и объединение этих данных с корпоративными записями, извлеченными из реляционной СУБД в формате CSV (с разделителями-запятыми) с помощью модуля JDBC, входящего в состав Jaql.
Описание образцового сценария
В этой статье мы будем использовать Jaql для сбора касающихся IBM Watson сообщений из социальной сети с последующим применением различных выражений Jaql для фильтрации, преобразования и обработки этих данных. IBM Watson - это исследовательский проект, цель которого - формирование путем сложного анализа ответов на вопросы, заданные на естественном языке. Для этого программа Watson использует Apache Hadoop, работающий на кластере серверов IBM Power 750, что позволяет эффективно обрабатывать данные, собранные из разных источников. В 2011 году IBM Watson занял первое место в телевизионном шоу Jeopardy!, победив двух лучших "живых" участников конкурса.
Бизнес-аналитики многих фирм интересуются мониторингом видимости, охвата и суждений, высказываемых о том или ином продукте или услуге, и в данной статье в роли такого продукта будет выступать IBM Watson. Бизнес-аналитики используют BigSheets - инструмент в стиле электронных таблиц из состава BigInsights - для анализа данных социальных сетей об IBM Watson, собранных с множества сайтов. В настоящей статье вы соберете и обработаете небольшой массив данных с одного сайта (Twitter), что поможет сосредоточиться на изучении ключевых аспектов Jaql.
Стоит упомянуть, что многие социальные сети предлагают API, которые можно использовать для извлечения общедоступных данных. В настоящей статье мы будем использовать поисковый REST-API сайта Twitter для извлечения небольших объемов данных, содержащих последние интересующие нас сообщения. Производственное приложение, скорее всего, будет использовать для извлечения больших объемов данных сервисы Twitter, но поскольку основной темой этой статьи является Jaql, мы будем использовать простые операции сбора данных.
Зачастую API, предлагаемые сайтами социальных сетей, возвращают данные в форме JSON - в той самой форме, которую использует Jaql. Прежде чем погрузиться в изучение примеров на языке Jaql, вам нужно познакомиться со структурой данных JSON социальных сетей, с которой мы будем работать в этой статье. Нет ничего проще - достаточно ввести в браузер, способный обрабатывать данные JSON (например, Chrome), адрес http://search.twitter.com/search.json?q=IBM+Watson.
Это заставит Twitter вернуть 15 самых последних сообщений, соответствующих заданному критерию поиска ("IBM Watson"). И хотя возвращенная информация может быть различной в зависимости от времени подачи запроса, структура результатов будет аналогична фрагменту, показанному в листинге 1, где показан пример созданных для иллюстрации данных. Далее мы рассмотрим некоторые ключевые аспекты этого фрагмента, позволяющими провести параллели с остальной частью статьи.
Листинг 1. Пример структуры записи JSON, полученной в результате поиска на сайте Twitter
{
"completed_in": 0.021,
"max_id": 99999999111111,
"max_id_str": "99999999111111",
"next_page": "?page=2&max_id=99999999111111&q=IBM%20Watson",
"page": 1,
"query": "IBM+Watson",
"refresh_url": "?since_id=99999999111111&q=IBM%20Watson",
"results": [
{
"created_at": "Mon, 30 Apr 2012 18:42:37 +0000",
"from_user": "SomeSampleUser",
"from_user_id": 444455555,
"from_user_id_str": "444455555",
"from_user_name": "Some Sample User",
"geo": null,
"id": 000000000000000001,
"id_str": "000000000000000001",
"iso_language_code": "en",
"metadata": {
"result_type": "recent"
},
"profile_image_url":
"http://a0.twimg.com/profile_images/222222/TwitterPic2_normal.jpg",
"profile_image_url_https":
"https://si0.twimg.com/profile_images/222222/TwitterPic2_normal.jpg",
"source": "<a href="http://news.myUniv.edu/" rel="nofollow">MyUnivNewsApp</a>",
"text": "RT @MyUnivNews: IBM's Watson Inventor will present at
a conference April 12 http://confURL.co/xrr5rBeJG",
"to_user": null,
"to_user_id": null,
"to_user_id_str": null,
"to_user_name": null
},
{
"created_at": "Mon, 30 Apr 2012 17:31:13 +0000",
"from_user": "anotheruser",
"from_user_id": 76666993,
"from_user_id_str": "76666993",
"from_user_name": "Chris",
"geo": null,
"id": 66666536505281,
"id_str": "66666536505281",
"iso_language_code": "en",
"metadata": {
"result_type": "recent"
},
"profile_image_url":
"http://a0.twimg.com/profile_images/3331788339/Mug_Shot.jpg",
"profile_image_url_https":
"https://si0.twimg.com/profile_images/3331788339/Mug_Shot.jpg",
"source": "<a href="http://www.somesuite.com" rel="nofollow">SomeSuite</a>",
"text": "IBM's Watson training to help diagnose and treat cancer
http://someURL.co/fBJNaQE6",
"to_user": null,
"to_user_id": null,
"to_user_id_str": null,
"to_user_name": null
},
. . .
"results_per_page": 15,
"since_id": 0,
"since_id_str": "0"
}Ниже представлено очень краткое введение в JSON. В листинге 1 приведена запись JSON, на что указывают фигурные скобки "{ }" в его начале и конце. Эта запись содержит несколько пар имя/значение, дополнительные (вложенные) записи JSON и массивы JSON (выделенные квадратными скобками "[ ]"). Данная ситуация вполне типична для JSON, который легко справляется с глубоко вложенными и переменными структурами данных.
Взглянув на этот пример, можно увидеть, что первая часть записи JSON содержит пары имя/значение с общей информацией о результатах поиска в Twitter. К примеру, наш поиск занял 0,021 секунды, а запрос при этом выполнялся по строке IBM Watson. В массив "results" (результаты) вложена запись, содержащая самые интересные для этой статьи данные - дополнительные записи JSON с сообщениями об IBM Watson.
Каждая запись JSON, вложенная в массив результатов, содержит имя, под которым известен пользователь ("from_user_name"), время создания сообщения ("created_at"), текст сообщения ("text"), язык текста "iso_language_code" и другую информацию. В действительности для объединения данных социальной сети с данными, извлеченными из реляционной СУБД, мы будем использовать идентификатор пользователя ("from_user_id_str"). Сценарий объединения для этой статьи будет очень простым и, вероятно, даже немного надуманным. Он предполагает, что работодатель ведет реляционную таблицу, которая отслеживает идентификаторы социальной сети, использующиеся его сотрудниками для служебной деятельности, и что эта фирма хочет проанализировать последние сообщения сотрудников. Тем не менее такой простой метод применения Jaql для объединения данных из разных источников можно использовать в широком диапазоне сценариев.
Выполнение операторов Jaql
BigInsights Enterprise Edition предлагает несколько опций выполнения операторов Jaql, в том числе следующие:
- оболочка Jaql, интерфейс командной строки;
- специальное приложение для формирования запросов Jaql, доступное через Web-консоль BigInsights. Перед запуском этого приложения администратор должен развернуть его в вашем кластере BigInsights и предоставить вам права доступа к этому приложению.
- испытательная среда Jaql, предлагаемая инструментами Eclipse для BigInsights.
- Web-сервер Jaql, который позволяет выполнять сценарии Jaql через вызовы REST API;
- Jaql API для встраивания Jaql в программы Java.
В настоящей статье используется оболочка Jaql. Для запуска оболочки Jaql откройте командное окно Unix/Linux и выполните следующую команду: $BIGINSIGHTS_HOME/jaql/bin/jaqlshell
NОбратите внимание, что $BIGINSIGHTS_HOME представляет собой переменную среды, определяющую директорию, в которую установлен BigInsights (обычно это /opt/ibm/biginsights). После запуска оболочки Jaql ваш экран будет выглядеть примерно так, как показано на рисунке 1.
Рисунок 1. Оболочка Jaql
Jaql и MapReduce
Jaql ориентирован на прозрачное применение модели программирования MapReduce, которая ассоциируется со средами на основе Hadoop. Благодаря Jaql вы можете сосредоточиться на решаемой вами проблеме, а не на базовой реализации задач вашей работы. Другими словами, ваши запросы указывают, что вы хотите получить, а система Jaql прозрачно переписывает ваши запросы, определяя способ выполнения работы. Технология переписывания запросов широко применяется в реляционных системах управления базами данных (РСУБД), и Jaql использует эту фундаментальную идею для упрощения вашей работы.
Технология переписывания запросов языка Jaql среди прочего предусматривает разделение вашей логики на задачи Map-Reduce, что позволяет выполнять работу параллельно в кластере BigInsights. Запросы, которые можно переписать в таком стиле, называются разделяемыми. После того как вы познакомитесь с Jaql, мы обсудим типы запросов, которые Jaql может преобразовать в последовательность задач Map-Reduce.
Сбор образцовых данных
Запрос, обработка и анализ данных через Jaql начинаются с чтения данных из источника, в качестве которого может выступать распределенная файловая систем Hadoop (HDFS), управляемая BigInsights; локальная файловая система; реляционная СУБД; сайт социальной сети с поисковым API на основе REST и другие источники. В этом разделе вы узнаете, как использовать Jaql для заполнения HDFS данными JSON, полученными из Twitter, и реляционными данными, полученными из DB2 Express-C. Несмотря на то, что BigInsights поддерживает и другие механизмы сбора и загрузки данных, описанные здесь методы вполне подходят для простого сценария, который мы используем в этой статье, и позволяют познакомиться с основными возможностями Jaql.
Работа с данными социальных сетей
BigInsights содержит несколько адаптеров ввода/вывода для Jaql. Каждый адаптер обеспечивает доступ к определенному источнику данных, такому как HDFS, Web-сервер или база данных, и преобразует данные из собственного формата в массивы значений JSON. Как можно предположить, адаптеры ввода/вывода Jaql тесно связаны с функциями read() и write(), предлагаемыми этим языком.
Теперь давайте познакомимся с одним простым методом извлечения 15 последних сообщений Twitter, касающихся IBM Watson. Как показано в листинге 2, сначала мы определяем переменную url, содержащую URL-адрес Twitter, который мы будем использовать для извлечения интересующих нас данных. Затем мы определяем переменную tweets, присваивая ей выражение, которое использует функцию read() языка Jaql с адаптером HTTP для получения данных из указанного адреса.
Листинг 2. Применение адаптера Jaql HTTP для получения данных из URL
url = "http://search.twitter.com/search.json?q=IBM+Watson";
tweets = read(http(url));
tweets;Поскольку Jaql выполняет присвоения переменных "ленивым" образом, результат операции чтения может не появляться вплоть до выполнения последнего оператора. Ввод переменной в оболочке Jaql сообщает Jaql команду на отображение содержимого переменной, что заставляет его выполнить определяемую ею операцию.
Несмотря на то, что использование переменных не является обязательным, зачастую это удобно, поскольку эти переменные можно использовать в последующих запросах для упрощения кода. Для иллюстрации этого утверждения приведенные ниже листинги будут обращаться к ранее определенным переменным.
Результат исполнения операторов, показанных в листинге 2, будет напоминать содержимое листинга 1. AКак и во всех остальных упражнениях этой статьи, конкретные результаты могут различаться, поскольку самые последние сообщения об IBM Watson постоянно меняются. Тем не менее между данными, возвращаемыми программами в двух листингах, существует различие. Jaql встраивает данные, возвращенные Web-сервисом, в массив верхнего уровня, например, [ twitter-json-data-content]. Таким образом, сообщения представляют собой массив, содержащий одну запись JSON со структурой, показанной выше в листинге 1.
Работа с данными реляционной СУБД
BigInsights Enterprise Edition включает приложения для импорта и экспорта баз данных, которые можно запускать из Web-консоли для чтения или записи реляционных СУБД.
В этой статье мы используем оболочку Jaql для динамического извлечения данных из реляционной СУБД. Jaql поддерживает подключение JDBC к СУБД IBM и других производителей, включая Netezza, DB2, Oracle и Teradata. Мы будем использовать универсальный модуль подключения JDBC для доступа к базе данных DB2 Express-C, содержащей таблицу с именем IBM.TWEETERS, которая отслеживает адреса электронной почты, идентификаторы Twitter, имена и должности сотрудников IBM, которые размещали сообщения на этом сайте. Используемая в настоящей статье таблица содержит образцовые данные, созданные для тестирования.
Теперь давайте исследуем код Jaql, приведенный в листинге 3.
Листинг 3. Динамический опрос реляционной СУБД из оболочки Jaql
// Блок 1: импорт модуля Jaql JDBC
import dbms::jdbc;
// Блок 2: установка пути класса для драйверов JDBC
addRelativeClassPath(getSystemSearchPath(), '/home/hdpadmin/myDrivers/db2jcc4.jar');
addRelativeClassPath(getSystemSearchPath(),
'/home/hdpadmin/myDrivers/db2jcc_license_cu.jar');
// Блок 3: подключение к базе данных
db := jdbc::connect(
driver = 'com.ibm.db2.jcc.DB2Driver',
url = 'jdbc:db2://myserver.ibm.com:50000/sample',
properties = { user: "myID", password: "myPassword" }
);
// Блок 4: подготовка и выполнение запроса
desc := jdbc::prepare(db, query =
"SELECT EMAIL, ID, NAME, TITLE FROM IBM.TWEETERS");
ibm = read(desc);
ibm;
// Пример вывода
[
{
"EMAIL": "john.doe@us.ibm.com",
"ID": "1111111",
"NAME": "John Doe",
"TITLE": "Researcher"
},
. . .
{
"EMAIL": "mary.johnson@us.ibm.com",
"ID": "71717171",
"NAME": "Mary Johnson",
"TITLE": "IT Architect"
}
]Блок 1 импортирует интересующий нас модуль Jaql. В данном случае dbms- это имя пакета Jaql, содержащего несколько соединителей СУБД, реализованных в виде отдельных модулей. Оператор import делает все функции и переменные модуля JDBC доступными для вашей сессии. Определение области действия конструкций JDBC Jaql выполняется в JDBC (см. вызовы, показанные в блоках 3 и 4 листинга 3).
Блок 2 определяет местоположения необходимых jar-файлов драйвера JDBC и добавляет их в путь класса Jaql. Поскольку он обращается к DB2 Express-C, файлы db2jcc4.jar и db2cc_license_cu.jar копируются в локальную файловую систему. Затем блок 3 вызывает функцию connect() модуля Jaql JDBC, передавая ей необходимые параметры подключения JDBC, в том числе класс драйвера JDBC, URL-адрес JDBC, а также имя и пароль пользователя. Обратите внимание, что оператор присвоения для переменной db, объявленной в этом выражении, отличается от оператора присвоения, использованного ранее в листинге 2. В частности, показанный здесь оператор:= принуждает к незамедлительному исполнению задачи, содержащейся в правой части уравнения (задачи подключения к СУБД). В данном случае он вынуждает Jaql немедленно получить указатель на подключение к DB2 и присвоить этот указатель переменной db.
После успешного подключения к базе данных мы можем подготовить и выполнить запрос, как показано в блоке 4. В данном примере выражение SQL SELECT просто извлекает из таблицы четыре столбца. Обратите внимание, что модуль Jaql JDBC не анализирует запрос и не проверяет его синтаксис перед передачей его в целевую базу данных. Функция read() исполняет подготовленный запрос, вызывая отображение результатов в виде массива JSON, содержащего несколько записей, каждая из которых состоит из четырех полей, соответствующих четырем столбцам, указанным в SQL-запросе.
Начиная с версии BigInsights 1.4 соединитель Jaql JDBC позволяет использовать ссылку на файл свойств в хранилище полномочий BigInsights, который содержит информацию о подключении к СУБД (такую как идентификатор и пароль пользователя), вместо непосредственной передачи этих данных, как показано в листинге 3.
Теперь, когда вы узнали, как извлекать данные из социальной сети и реляционной базы данных, мы применим полученные знания для объединения данных этих разных источников с помощью Jaql. Но сначала давайте рассмотрим некоторые базовые возможности формирования запросов в Jaql.
Запрос и обработка данных
Типичная операция запроса включает извлечение некоторых полей из входных данных. Если вы знакомы с SQL, представьте это как проекцию или извлечение из таблицы подмножества столбцов. Теперь посмотрите, как можно извлечь указанные поля из образцовых данных Twitter, собранных в предыдущем разделе. Затем вы увидите, как обрабатывать или преобразовывать выходные данные в другие структуры JSON.
Извлечение одного поля
Начнем с очень простого примера. Выполнив код Jaql, показанный выше в листинге 2, вы получите массив JSON верхнего уровня, содержащий запись JSON с возвращенными Twitter данными о недавних сообщениях об IBM Watson (в листинге 1 приведен пример возвращаемых Twitter данных такой записи JSON). В запись JSON включен массив результатов, содержащий несколько записей JSON, которые представляют собой сообщения. Каждая подобная запись содержит различные поля. А что если мы хотим получить лишь одно поле каждой записи, например, поле id_str? Как осуществить это в Jaql?
Листинг 4 демонстрирует один из подходов к такому запросу и затем пример выходных данных.
Листинг 4. Извлечение одного поля с помощью выражения transform Jaql
tweets -> transform $.results.id_str;
// Пример выходных данных Jaql
[
[
"999992200059387904",
"999992003644329985",
"999991910044229633",
"999991880671531008",
"999991865702064128",
"999991853391769601",
"999991708440817664",
"999991692309524480",
"999991655370293248",
"999991582779469826",
"999991442597437442",
"999991361437655041",
"999991343142100992",
"999991269276213249",
"999991175747436544"
]
]Давайте кратко рассмотрим этот запрос. В результате выполнения кода из листинга 2, в переменной tweets будут содержаться полученные с сайта данные. Оператор конвейера (->) передает эти данные выражению transform, которое указанным способом изменяет выходные значения. В данном случае Jaql дается команда на извлечение поля id_str, содержащегося в массиве результатов в текущей записи. Использованный в листинге 4 знак доллара является сокращением, применяемым в Jaql для обозначения текущей записи.
Если внимательней взглянуть на выходные значения, то можно увидеть, что они содержат один массив JSON, возвращаемый внутри другого массива JSON. Выражение transform выполняет цикл и трансформирует все элементы входного массива, возвращая выходной массив. В данном случае входной массив представляет собой массив с одной записью JSON, и эта запись содержит вложенный в нее массив. Таким образом, Jaql возвращает массив, который содержит один (вложенный) массив значений id_str.
Теперь представьте, что вы хотите получить один простой плоский массив значений. Этого можно достичь с использованием выражения expand/code>. Выражение expand получает на входе массив вложенных массивов [ [ T ] ] и создает выходной массив [ T ], продвигая элементы каждого вложенного массива к выходному массиву верхнего уровня. Листинг 5 показывает, как использовать expand для возврата одиночного массива значений id_str.
Листинг 5. Превращение вложенного массива в плоский с помощью выражения expand
tweets -> transform $.results.id_str -> expand;
// Пример выходных данных Jaql
[
"999992200059387904",
"999992003644329985",
"999991910044229633",
"999991880671531008",
"999991865702064128",
"999991853391769601",
"999991708440817664",
"999991692309524480",
"999991655370293248",
"999991582779469826",
"999991442597437442",
"999991361437655041",
"999991343142100992",
"999991269276213249",
"999991175747436544"
]Запись и чтение данных из HDFS
До сих пор мы запрашивали данные, динамически извлекаемые из Web-источника. Конечно, можно продолжить делать это и дальше, но практичнее будет записать интересующие нас данные в HDFS, чтобы они остались доступными после закрытия сессии Jaql. Поскольку нас интересуют только данные, содержащиеся во вложенном массиве результатов, который вернул Twitter, именно их мы и запишем в HDFS.
Листинг 6 использует функцию write() для записи определенных данных из Twitter в файл SequenceFile с именем recentTweets.seq в указанной директории HDFS. SequenceFiles является одним из многочисленных форматов, поддерживаемых языком Jaql.
Листинг 6. Запись данных в SequenceFile
// Запись "результирующих" данных первого элемента сообщений в HDFS
// Эти данные содержат сообщения Twitter и соответствующую информацию
tweets[0].results ->
write(seq("/user/idcuser/sampleData/twitter/recentTweets.seq"));
// Выходные данные Jaql
{
"inoptions": {
"adapter": "com.ibm.jaql.io.hadoop.DefaultHadoopInputAdapter",
"configurator": "com.ibm.jaql.io.hadoop.FileInputConfigurator",
"format": "org.apache.hadoop.mapred.SequenceFileInputFormat"
},
"location": "/user/idcuser/sampleData/twitter/recentTweets.seq",
"outoptions": {
"adapter": "com.ibm.jaql.io.hadoop.DefaultHadoopOutputAdapter",
"configurator": "com.ibm.jaql.io.hadoop.FileOutputConfigurator",
"format": "org.apache.hadoop.mapred.SequenceFileOutputFormat"
}
}Первая строка листинга 6 указывает данные, которые мы хотим записать - результирующую часть первого элемента в массиве сообщений, возвращенном нашим поиском по Twitter. Для доступа к первому и единственному элементу массива верхнего уровня, возвращенному в переменной tweets, используется обычное обращение к массиву по индексу. Таким образом, tweets[0] возвращает первый элемент, который представляет собой большую запись JSON с данными Twitter. Внутри этого элемента можно легко выделить одиночное поле. В данном случае мы хотим получить массив результатов со всеми полями Twitter. Оператор -> в первой строке представляет собой простой оператор конвейера, который направляет содержимое переменной tweets в функцию write().
Выходные данные Jaql, возвращенные первым выражением, показаны во второй части листинга 6. Выход представляет собой дескриптор файла Jaql, который включает информацию об адаптерах ввода/вывода и форматах, используемых для обработки этого выражения.
Возможно, вас удивило то, что для данного примера выбран формат SequenceFile. Как вы узнаете позже, Jaql может считывать и записывать такие данные параллельно, автоматически используя этот ключевой аспект системы MapReduce. Такой параллелизм невозможен при непосредственном чтении данных из Web-сервиса (как это делалось в листинге 2). Кроме того, для обеспечения эффективности обработки запросов мы преобразовали и структурировали данные так, чтобы выделить только интересующую нас информацию и получить набор небольших объектов (в данном случае записей JSON, представляющих собой сообщения). Такую структуру можно опрашивать с более высокой степенью параллелизма по сравнению с возвращаемыми Twitter исходными данными JSON, состоящими из массива верхнего уровня с одной записью JSON - структуры, которую нельзя разделить, чтобы воспользоваться выгодами параллелизма. И хотя объем этих образцовых данных крайне невелик, описанные здесь фундаментальные идеи играют очень важную роль при обработке больших объемов данных.
После сохранения данных в HDFS их можно извлечь с помощью функции read(), как показано в листинге 7.
Листинг 7. Чтение SequenceFile из HDFS
tweetsHDFS = read(seq("/user/idcuser/sampleData/twitter/recentTweets.seq"));
tweetsHDFS;
// Пример выходных данных Jaql
[
{
"created_at": "Mon, 30 Apr 2012 18:42:37 +0000",
"from_user": "SomeSampleUser",
"from_user_id": 444455555,
"from_user_id_str": "444455555",
"from_user_name": "Some Sample User",
"geo": null,
"id": 000000000000000001,
"id_str": "000000000000000001",
"iso_language_code": "en",
"metadata": {
"result_type": "recent"
},
"profile_image_url":
"http://a0.twimg.com/profile_images/222222/TwitterPic2_normal.jpg",
"profile_image_url_https":
"https://si0.twimg.com/profile_images/222222/TwitterPic2_normal.jpg",
"source": "<a href="http://news.myUniv.edu/" rel="nofollow">MyUnivNewsApp</a>",
"text": "RT @MyUnivNews: IBM's Watson Inventor will present
at a conference April 12 http://confURL.co/xrr5rBeJG",
"to_user": null,
"to_user_id": null,
"to_user_id_str": null,
"to_user_name": null
},
. . .
{
"created_at": "Mon, 30 Apr 2012 17:31:13 +0000",
"from_user": "anotheruser",
"from_user_id": 76666993,
"from_user_id_str": "76666993",
"from_user_name": "Chris",
"geo": null,
"id": 66666536505281,
"id_str": "66666536505281",
"iso_language_code": "en",
"metadata": {
"result_type": "recent"
},
"profile_image_url":
"http://a0.twimg.com/profile_images/3331788339/Mug_Shot.jpg",
"profile_image_url_https":
"https://si0.twimg.com/profile_images/3331788339/Mug_Shot.jpg",
"source": "<a href="http://www.somesuite.com" rel="nofollow">SomeSuite</a>",
"text": "IBM's Watson training to help diagnose and treat cancer
http://someURL.co/fBJNaQE6",
"to_user": null,
"to_user_id": null,
"to_user_id_str": null,
"to_user_name": null
}
]Теперь, когда мы выделили интересующие нас данные и извлекли их из HDFS, можно исследовать некоторые другие сценарии запроса.
Извлечение нескольких полей
Давайте посмотрим, как извлечь несколько полей из данных, сохраненных в HDFS. В частности, предположим, что необходимо получить набор записей, каждая из которых содержит поля с датой создания (created_at), географическим положением (geo), идентификатором пользователя (from_user_id_str), кодом языка (iso_language_code) и текстом (text), которые относятся к возвращенным сообщениям. Если вы знакомы с SQL, у вас может возникнуть искушение написать нечто похожее на показанный в листинге 8 код, который применяет выражение transform к нескольким полям. Однако это приведет к ошибке.
Листинг 8. Неправильное применение выражения Jaql для извлечения нескольких полей записи
// Неправильный синтаксис извлечения нескольких полей
tweetsHDFS -> transform $.created_at, $.geo,
$.from_user_id_str, $.iso_language_code, $.text;Теперь познакомьтесь с правильным способом достижения поставленной цели, как показано в листинге 9.
Листинг 9. Извлечение выбранных полей и возврат их в виде записей JSON внутри массива
tweetsHDFS -> transform {
created_at: $.created_at,
geo: $.geo,
id: $.from_user_id_str,
iso_language_code: $.iso_language_code,
text: $.text };
// Пример выходных данных Jaql
[
{
"created_at": "Mon, 30 Apr 2012 17:30:09 +0000",
"geo": null,
"id": "888888888",
"iso_language_code": "en",
"text": "#someUser: IBM\'s Watson Has An Answer
About The Future of Health Care / http://someURL.co/ZZ1XX via #mynews"
},
. . .
{
"created_at": "Mon, 30 Apr 2012 17:24:43 +0000",
"geo": null,
"id": "77777777",
"iso_language_code": "en",
"text": "Great news! \"RT @SomePlace:
Can Watson, IBM\'s Supercomputer, Cure Cancer? http://someURL.co/DDk1a \""
}
]Поскольку переменная tweetsHDFS содержит массив записей JSON, используйте для доступа к каждой записи этого массива выражение transform со специальной переменной в виде знака доллара. Кроме того, укажите, что вы хотите преобразовать каждую входную запись в новую запись JSON (выделено фигурными скобками). Каждая новая запись будет содержать пять нужных нам полей, представленных в виде пар имя/значение. Например, первым полем новой записи является поле created_at (произвольное имя), значение которого получено из поля входного массива $.created_at.
Кстати говоря, определяя новую запись JSON, которая должна генерироваться выражением transform, можно опустить имя поля, если вы хотите, чтобы Jaql ввел его из имени поля входного массива. Например, как показано выше в листинге 9, четыре из пяти полей, определенных в новой записи JSON, имеют те же имена, что и соответствующие поля входного массива. Так что можно не указывать имена этих полей в явной форме. Листинг 10 показывает подобную укороченную версию кода.
Листинг 10. Использование стандартных имен полей при определении структуры новой записи JSON
// укороченная версия предыдущего запроса
// если не указано иное, Jaql использует имена полей по умолчанию
tweetsHDFS -> transform {
$.created_at,
$.geo,
id: $.from_user_id_str,
$.iso_language_code,
$.text };Фильтрация данных
Еще одним общим требованием к запросу является фильтрация данных по указанным критериям. Например, представьте, что вы хотите извлечь сообщения на английском языке. листинг 11 показывает простой способ для достижения этой цели.
Листинг 11. Извлечение выбранных полей и фильтрация данных по одному логическому условию
// Запрос 1: преобразование данных, извлечение выбранных полей
tweetRecords = tweetsHDFS
-> transform {
created_at: $.created_at,
geo: $.geo,
id: $.from_user_id_str,
iso_language_code: $.iso_language_code,
text: $.text };
// Запрос 2: фильтрация данных, выделение записей на английском языке
tweetRecords -> filter $.iso_language_code == "en";
// Пример выходных данных Jaql
[
{
"created_at": "Mon, 30 Apr 2012 17:30:09 +0000",
"geo": null,
"id": "888888888",
"iso_language_code": "en",
"text": "#someUser: IBM\'s Watson Has An Answer
About The Future of Health Care / http://someURL.co/ZZ1XX via #mynews"
},
. . .
{
"created_at": "Mon, 30 Apr 2012 17:24:43 +0000",
"geo": null,
"id": "77777777",
"iso_language_code": "en",
"text": "Great news! \"RT @SomePlace:
Can Watson, IBM\'s Supercomputer, Cure Cancer? http://someURL.co/DDk1a \""
}
]Первый запрос практически идентичен запросу, показанному выше в листинге 9, за исключением того, что здесь определена переменная tweetRecords, в которую заносится запись JSON, содержащая интересующие нас поля каждого сообщения. Второй запрос передает эту переменную в качестве входа в выражение filter, которое исследует поле iso_language_code в поисках значения en - ISO-кода английского языка. Опять же, знак доллара представляет собой специальную переменную выражения filter, которая привязывает к нему каждый входной элемент. Затем можно с легкостью обратиться к отдельным полям, используя для этого символ точки, как показано в листинге. Записи, соответствующие критерию поиска, будут включены во входные данные, как показано в конце листинга.
Если вы хотите отфильтровать результаты запроса по нескольким условиям, просто используйте синтаксис AND/OR. Например, запрос в листинге 12 возвращает сообщения на английском языке, для которых не указано географическое положение. Такие записи будут иметь нулевое значение в поле geo. Для проверки нулевых значений Jaql предлагает выражения isnull и not isnull.
Листинг 12. Применение нескольких логических условий (условий фильтрации)
tweetRecords -> filter $.iso_language_code == "en" and isnull $.geo;
Сортировка данных
Еще одним типичным требованием к запросу является сортировка данных, которая с легкостью выполняется в Jaql. Допустим, мы хотим отсортировать сообщения по идентификатору пользователя в восходящем порядке. Соответствующий синтаксис показан в листинге 13.
Листинг 13. Сортировка результатов запроса
tweetRecords -> sort by [$.id asc]
В качестве входных данных в выражение sort by передается массив, представленный переменной tweetRecords. Этому выражению требуется хотя бы одно поле, по которому нужно выполнять сортировку. В выражение передается поле $.id (представляющее идентификатор пользователя), а восходящий порядок сортировки указывается значением asc. Для сортировки в нисходящем порядке укажите значение desc.
Можно также выполнять сортировку по нескольким критериям, как показано в листинге 14.
Листинг 14. Применение нескольких критериев сортировки
// Sort by id (ascending), then geo (descending) tweetRecords -> sort by [$.id asc, $.geo desc];
Агрегация данных
Некоторые приложения требуют, чтобы данные были сгруппированы, и чтобы для всех групп был рассчитан некоторый общий показатель. Jaql поддерживает общие функции агрегации, включая min (минимум), max (максимум), count (количество) и другие. Взгляните на следующий простой пример.
Представьте, что требуется подсчитать число сообщений на каждом языке. Соответствующий синтаксис показан в листинге 15.
Листинг 15. Агрегация данных
tweetRecords ->
group by key = $.iso_language_code
into { groupingKey: key, num: count($) };
// Пример выходных данных Jaql
[
{
"groupingKey": "de",
"num": 1
},
{
"groupingKey": "en",
"num": 12
},
{
"groupingKey": "fr",
"num": 2
}
]В этом примере сообщения передаются в выражение group by. Используйте в качестве критерия группировки $.iso_language_code и определите переменную key для указания значения, по которому выполняется группировка. И хотя этот пример выполняет группировку по одному полю, Jaql допускает группировку по записям, если вам нужно выполнить группировку по нескольким значениям.
Кроме того, вы можете указать, чтобы результаты записывались в новые записи JSON, каждая из которых будет содержать пары имя/значение. Переменная groupingKey будет содержать найденный в записи ISO-код языка, а переменная num - число появлений каждого значения. Оператор into вызывается для каждого уникального значения группировки и позволяет конструировать выходное значение для группы. В операторе into можно использовать указанное вами имя группы (ключ) для ссылки на текущее значение группы; переменная $ при этом будет представлять собой массив всех входящих в группу записей. В результате count($) будет содержать значение, определяющее количество всех записей.
Пример выходных данных, приведенный выше в листинге 15, содержит три записи JSON, включенные в возвращаемый массив. Как вы можете увидеть, одно сообщение было написано на немецком (ISO-код "de"), 12 на английском (ISO-код "en") и два на французском (ISO-код "fr") языках.
Разделение выходных данных запроса с помощью функции tee
Если вы знакомы с командами Unix, вы наверняка использовали команду tee для вывода результатов работы программы в два разных места, например, на терминал и в файл. Jaql предлагает аналогичную конструкцию, позволяющую разделять выход запроса в зависимости от результата вызова функции. Типичное применение включает запись выходных значений в два разных файла.
Как показано в листинге 16, функция tee языка Jaql используется с выражением filter для записи данных в два разных локальных файла, что может оказаться полезным для проведения диагностики или применительно к некоторым приложениям.
Листинг 16. Применение функции tee для разделения выходных данных на два файла
tweetRecords -> tee( -> filter $.iso_language_code == "en" ->
write(jsonTextFile("file:///home/hdpadmin/en.json"))
-> filter $.iso_language_code != "en" ->
write(jsonTextFile("file:///home/hdpadmin/non-en.json"))
);В данном случае использован простой метод - запись сообщений на английском языке в файл en.json и сохранение остальных сообщений в локальном файле non-en.json. Таким образом, если вы захотите применить функции анализа текста к сообщениям на английском языке, вам нужно выделить их в отдельный файл.
Обратите внимание, что в качестве схемы для пути URI используется "file:///", что указывает на локальную файловую систему (не HDFS).
Слияние данных
Подобно SQL и другим языкам запросов Jaql позволяет объединять данные из нескольких источников (нескольких массивов JSON). Выражение union в Jaql не удаляет дублирующиеся записи и поэтому работает подобно выражению UNION ALL в SQL.
В листинге 17 показан простой сценарий, использующий выражение union для чтения данных из двух SequenceFiles, сохраненных в HDFS.
Листинг 17. Слияние данных из двух файлов
union(read(seq('/user/idcuser/sampleData/twitter/tweet1.seq')),
read(seq('/user/idcuser/sampleData/twitter/tweet2.seq'))
);Эти файлы созданы с использованием данных Twitter, извлеченных в разное время с помощью API на основе REST (см. листинг 2) и записанных в HDFS с помощью функции write() (см. листинг 6). Когда эти данные собраны, объединение файлов с легкостью осуществляется путем указания двух операций чтения в качестве параметра выражения union.
При желании вы можете записать результаты этого слияния в HDFS.
Объединение данных
Чтобы закончить знакомство с Jaql, нужно узнать, как объединять данные. Напомним, что переменная ibm, определенная ранее в листинге 3, содержит данные, извлеченные из реляционной СУБД и содержащие сведения о сотрудниках IBM, разместивших сообщения в социальной сети в рамках своей служебной деятельности. Представьте, что вам нужно объединить эти корпоративные данные с сообщениями, представленными переменной tweetRecords, определенной в запросе 1 листинга 11. Поля ibm.ID и tweetRecords.id выступают в роли ключа объединения, как показано в операторе where во второй строке листинга 18. Обратите внимание, что имена полей в Jaql чувствительны к регистру.
Листинг 18. Объединение данных, извлеченных с сайта социальной сети, с данными, извлеченными из реляционной СУБД
join tweetRecords, ibm
where tweetRecords.id == ibm.ID
into {
ibm.ID, ibm.NAME, ibm.TITLE, tweetRecords.text, tweetRecords.created_at
}
-> sort by [$.ID asc];
// Пример выходных данных
[
{
"ID": "159088234",
"NAME": "James Smith",
"TITLE": "Consultant",
"text": "Great news! \"RT @OwnPrivateCloud: Can Watson,
IBM\'s Supercomputer, Cure Cancer? http://sampleURL.co/dgttTra \"",
"created_at": "Mon, 30 Apr 2012 17:28:43 +0000"
},
{
"ID": "370988953",
"NAME": "John Taylor",
"TITLE": "IT Specialist",
"text": "http://someURL.co/45x044 Can Watson,
IBM\'s Supercomputer, Cure Cancer? - CIO",
"created_at": "Mon, 30 Apr 2012 17:11:58 +0000"
}
]Оператор into, вводимый в третьей строке листинга 18, определяет новую запись JSON для результатов запроса. В данном случае каждая запись будет содержать пять полей. Первые три поля содержат данные, извлеченные из реляционной СУБД, а оставшиеся два - данные социальной сети. Последним шагом является сортировка выходных данных.
Параллелизм и Jaql
Теперь, когда вы познакомились с основами Jaql, можно еще раз обратиться к представленной ранее теме - применению параллелизма в Jaql с помощью среды MapReduce. В то время как многие запросы можно распределить (выполнять параллельно) по нескольким узлам кластера BigInsights, некоторые запросы или, что чаще, определенные группы запросов Jaql не могут использовать параллелизм MapReduce. Чтобы Jaql мог создать план исполнения запроса с разделением работы по нескольким операциям Map и Reduce, должны соблюдаться два базовых условия:
- входные/выходные данные запроса должны быть пригодны для разделения. Обычно для разделения пригодны данные, находящиеся в некоторых типах распределенных систем хранения, таких как HDFS, HBase или даже СУБД. Примерами не пригодных к разделению данных являются данные, считанные из Web-сервиса; данные JSON, сохраненные в локальной файловой системе; и данные JSON, содержащие записи, которые занимают несколько строк;
- операторы, использованные в Jaql, должны быть пригодны для разделения, при этом Jaql должен иметь информацию о том, как распараллелить их через MapReduce. Этому критерию отвечают все операторы массивов Jaql, включая transform, expand, filter, sort, group by, join, tee и union. Тем не менее, некоторые функции могут не отвечать этому критерию.
Кроме того, Jaql хорошо приспособлен для обработки массивов JSON, содержащих множество мелких объектов. Структуры данных, содержащие малое число крупных объектов, не столь идеальны, поскольку один крупный объект нельзя разделить, чтобы воспользоваться преимуществами параллелизма MapReduce.
Пожалуй, лучшим способом исследования того, какие части запроса Jaql будут исполняться параллельно, а какие последовательно, является применение выражения explain для отображения плана выполнения запроса. Просто поставьте explain перед каждым запросом и дождитесь вывода операторов mapReduce и mrAggregate. Это покажет, использовалась ли операция MapReduce для выполнения нескольких или всех ваших запросов.
И хотя подробное обсуждение функции explain языка Jaql выходит за рамки настоящей статьи, давайте рассмотрим небольшой пример. Приведенный ранее листинг 2 определил переменную tweets для размещения результатов чтения данных Twitter из Web-сервиса. Далее, после преобразования и записи подмножества этих данных в SequenceFile в HDFS, листинг 7 считал этот файл в переменную tweetHDFS.
Взгляните на два запроса Jaql, показанные в листинге 19, которые возвращают одинаковые результаты - массив значений id_str. (Изначально Twitter вернул это поле как часть массива результатов в составе более крупной записи JSON). Данные tweetsHDFS основаны на проекции массива результатов, поэтому запросу 2 не нужна ссылка на этот массив.
Листинг 19. Два требующих пояснения запроса
// Запрос 1: получает поле "id_str" из Web-источника
// и возвращает данные в виде "плоского" массива
tweets -> expand $.results.id_str;
// Запрос 2: получает поле "id_str" из файла HDFS
// Структура данных уже сделана "плоской" во время записи в HDFS
tweetsHDFS -> transform $.id_str;Как сказано выше, Jaql может параллельно выполнять операторы expand и transform (распределяя их работу). Следовательно, второй критерий, упомянутый в начале этого раздела, удовлетворяется для обоих запросов. А вот с первым критерий дела обстоят не столь гладко. SequenceFile в HDFS можно разделить и обработать с помощью MapReduce, однако потоковое подключение к Web-сервису не позволяет разделять данные. В результате запрос 2, показанный выше в листинге 19, может быть обработан с помощью нескольких задач MapReduce, поскольку для SequenceFile мы определили структуру, состоящую из большого числа малых объектов (много записей JSON). В то же время запрос 1 нельзя обрабатывать параллельно, поскольку его данные динамически извлекаются из сервиса на основе REST.
Исследование выходного значения explain позволяет увидеть два разных плана доступа для этих запросов. Листинг 20 демонстрирует план доступа к данным для запроса 1.
Листинг 20. Выполнение оператора explain для не использующего параллелизм запроса
// Выполнение оператора Explain для запроса 1
explain tweets -> expand $.results;
system::read(system::const({
"location": "http://search.twitter.com/search.json?q=IBM+Watson",
"inoptions": {
"adapter": "com.ibm.jaql.io.stream.StreamInputAdapter",
"format": "com.ibm.jaql.io.stream.converter.JsonTextInputStream",
"asArray": false
}
})) -> expand each $ ( ($).("results") )
;Как видите, операторы mapReduce и mrAggregate в этом плане отсутствуют. Это значит, что запрос будет считывать и обрабатывать данные в пределах одной виртуальной машины Java (JVM).
В отличие от этого, результат оператора explain для запроса 2, приведенный в листинге 21, показывает, что данные считываются и обрабатываются в виде задачи MapReduce, поскольку в начале выходных данных explain присутствует оператор mapReduce.
Листинг 21. Выполнение оператора explain для использующего параллелизм запроса
// Выполнение оператора Explain для запроса 2
explain tweetsHDFS -> transform $.id_str;
(
$fd_0 = system::mapReduce({ ("input"):(system::const({
"location": "/user/idcuser/sampleData/twitter/recentTweets.seq",
"inoptions": {
"adapter": "com.ibm.jaql.io.hadoop.DefaultHadoopInputAdapter",
"format": "org.apache.hadoop.mapred.SequenceFileInputFormat",
"configurator": "com.ibm.jaql.io.hadoop.FileInputConfigurator"
},
"outoptions": {
"adapter": "com.ibm.jaql.io.hadoop.DefaultHadoopOutputAdapter",
"format": "org.apache.hadoop.mapred.SequenceFileOutputFormat",
"configurator": "com.ibm.jaql.io.hadoop.FileOutputConfigurator"
}
})), ("map"):(fn(schema [ * ] $mapIn) ($mapIn
-> transform each $ (($).("id_str"))
-> transform each $fv ([null, $fv]))), ("schema"):(system::const({
"key": schema null,
"value": schema any
})), ("output"):(system::HadoopTemp()) }),
system::read($fd_0)
)
;Как видите, оператор Jaql вводит данные в задачи map, причем каждый распределитель выполняет необходимую операцию параллельно на своей части данных. Этот запрос генерирует операцию исключительно на основе Map, поэтому операция reduce в выходе оператора explain не упоминается.
Использование выходных данных запроса Jaql с BigSheets
До сих пор вы сохраняли выходные данные запросов в виде SequenceFile в HDFS. Такие файлы обычно удобны для программистов, однако бизнес-аналитики и другие нетехнические работники скорее предпочтут иные форматы файлов.
Представьте, что мы хотим сохранить результаты одного или нескольких запросов Jaql в HDFS в формате, который можно легко отобразить в BigSheets - инструменте в стиле электронных таблиц, входящем в комплект поставки BigInsights. Поскольку BigInsights содержит несколько разных адаптеров ввода/вывода, можно легко настроить один из наших прежних запросов так, чтобы он сохранял результаты в виде файла с символом-разделителем (файл .del) в формате, понятном BigSheets. Кроме того, Jaql может распараллелить задачу ввода/вывода (если вам это интересно).
Листинг 22 показывает, как можно записать результаты запроса в виде файла с разделителями в HDFS. Обратите внимание, что для выходного файла определена схема, управляющая порядком, в котором указанные поля заносятся в файл.
Листинг 22. Обработка и сохранение данных в виде файла с разделителями
// Переменная tweets была определена ранее в листинге 2
sheetsData = tweets -> expand $.results
-> transform { created_at: $.created_at,
geo: $.geo,
id: $.from_user_id_str,
iso_language_code: $.iso_language_code,
text: $.text };
// записывает эти данные в виде файла с разделителями в распределенной файловой системе
sheetsData -> write(del('/user/idcuser/sampleData/twitter/tweetRecords.del',
schema = schema {created_at, geo, id, iso_language_code, text}));После записи файла в HDFS можно запустить Web-консоль BigInsights и, перейдя на вкладку Files (Файлы), увидеть результат, как показано на рисунке 2.
Рисунок 2. Определение коллекции BigSheets на основе результатов Jaql, записанных в HDFS
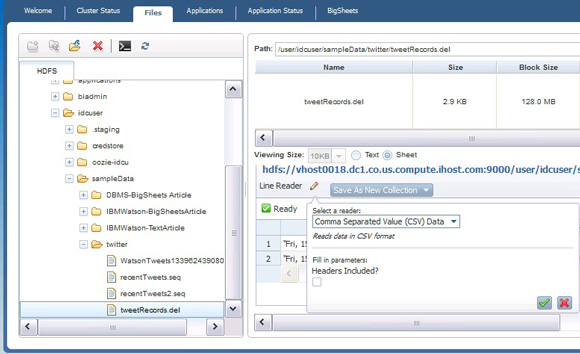
Придерживайтесь стандартного процесса для определения коллекции BigSheets для этих данных. В правой панели, показанной на рисунке 2, измените режим отображения файла с Text (Текст) на Sheets (Листы) и затем переключите тип чтения на разделенные запятыми значения без заголовков.
Кстати говоря, содержимое переменной tweetRecords, определенной ранее в листинге 11, также может быть записано в HDFS в виде файла с разделителями, как показано в листинге 23.
Листинг 23. Запись данных, представленных в переменной tweetRecords, в виде файла с разделителями
// Сохранение записей в виде файла с разделителями в распределенной файловой системе
tweetRecords -> write(del('/user/idcuser/sampleData/twitter/tweetRecords',
schema = schema {created_at, geo, id, iso_language_code, text}));В результате этой операции в HDFS вместо одиночного файла будет создана целая директория. Чтобы увидеть содержимое в BigSheets, в директории нужно создать новую коллекцию (вместо содержащегося в директории одиночного выходного файла).
Заключение
Эта статья познакомила вас с Jaql - языком запросов и сценариев, предназначенным для работы с большими объемами данных. В частности, в статье поясняется методика использования Jaql с InfoSphere BigInsights для чтения, записи, фильтрации и обработки структурированных данных и данных, полученных из социальных сетей, с помощью различных выражений и функций, предлагаемых этим языком. Кроме того, статья описывает, как Jaql использует параллельную обработку, наследуемую в среде MapReduce, и знакомит вас с функцией explain, которая позволяет определить способ доступа к файлам, используемый BigInsights при исполнении вашего запроса. Наконец, вы познакомились с одним из способов форматирования и сохранения результатов запросов Jaql в форме, легко доступной BigSheets - инструменту в стиле электронных таблиц для бизнес-аналитиков, входящему в комплект поставки BigInsights.
Вне всяких сомнений, данная вводная статья содержит лишь малую толику того, что вы можете узнать о языке Jaql. К примеру, Jaql поддерживает определенные пользователем функции и модули, а также многие конструкции SQL. Кроме того, он поддерживает анализ текста в BigInsights, позволяя программистам использовать экстракторы текста, поставляемые IBM и другими производителями ПО.