
"Сейчас Hadoop как проект с открытым исходным кодом находится под управлением Apache Software Foundation, отсюда и полное название Apache Hadoop. Проект используется для распределенных вычислений, но может быть и хранилищем файлов, вмещающим огромные массивы данных. Технически Hadoop состоит из распределенной файловой системы HDFS, основной задачей которой является хранение данных, и системы MapReduce, предназначенной для вычислений и обработки данных на кластере.
HDFS или Hadoop File System, - система хранения данных, используемая приложениями Hadoop. Особенность её заключается в том, что она многократно копирует блоки данных и распределяет их по вычислительным узлам. Таким образом, платформа продолжает работать, даже если какой-то из серверов выходит из строя. HDFS заточена под потоковые считывания файлов, и они записываются в системе лишь однократно, так что внесение произвольных записей в файлы невозможно в принципе. При этом приложения Hadoop могут работать с файлами распределённой файловой системы через программный интерфейс Java".
Основное применение, которое Hadoop находит в корпоративном мире, - это обработка массивов "больших данных". Именно с большими данными наиболее плотно проассоциирована эта платформа распределённых вычислений. Они практически стали неразрывно связанными понятиями.
"Получив представление о работе двух основных компонентов платформы, перейдём к тому, как Hadoop взаимодействует с корпоративными системами. Для обработки входящих запросов и хранения данных в больших компаниях обычно используются системы управления реляционными базами данных - СУРБД. Работа, как правило, построена следующим образом: СУРБД обрабатывает запросы (из приложений или, например, с сайта), а затем данные извлекаются из реляционной базы данных и отправляются в хранилище для обработки и архивации. Проблема в том, что корпорации сегодня производят такое количество данных, что СУРБД не в состоянии вместить требуемые объёмы. Задача решается либо за счёт частичного копирования данных в СУРБД, либо удалением данных через некоторое время. И чтобы решить этот вопрос, в качестве прослойки между БД и хранилищем используется Hadoop. Это приводит к тому, что производительность обработки данных возрастает пропорционально увеличению объёма хранилища данных".
При всей этой довольно идиллической картинке, были у Hadoop и свои недостатки, недоработки, об исправлении которых просили ИТ-специалисты и разработчики. Но Apache довольно долго не выпускала обновлений системы, держа Open Source сообщество в напряжении: что же будет в следующей версии "желтого слона"?
И вот 15 октября сообщество Apache Foundation официально объявило о релизе Hadoop 2.2.0, которая является GA-релизом Hadoop 2.0, то есть стабильной, устойчивой и готовой к работе версии. И надо сказать, что в этой версии появились более чем интересные обновления, позволяющие говорить о том, что Hadoop сделала "большие данные" намного доступнее, то есть ближе к народу.
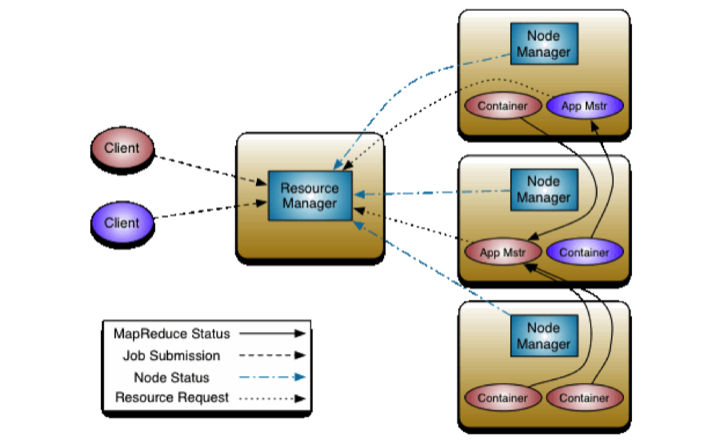
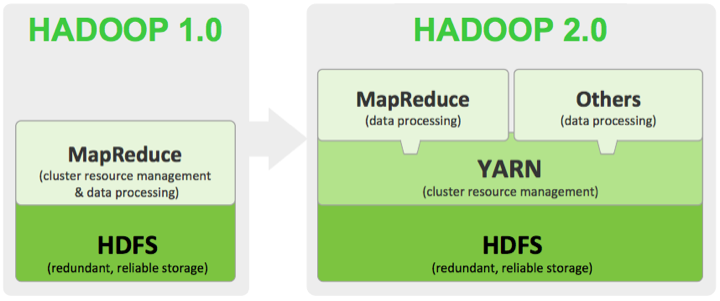
Одно из основных улучшений новой Hadoop - обновление Apache YARN, также известного как MapReduce 2.0. Это пакетный процессор, который выполняет поиск и отправляет полученные данные в распределённую файловую систему Hadoop, чтобы извлечь из массива данных полезную информацию. В предыдущей версии MR выполнялась лишь одна задача за промежуток времени в пакетном режиме из-за ограничений Java. А обновлённый MapReduce умеет обрабатывать сразу несколько операций поиска одновременно. Более того, YARN разделил функциональность MapReduce JobTracker на ResourceManager, который осуществляет управление ресурсами и выполняет мониторинг / планирование задач, и компонент ApplicationMaster, контролирующий работу фреймворка на уровне отдельных приложений. Такое разделение позволяет более эффективно управлять ресурсами кластера Hadoop: теперь MapReduce управляет ресурсами как операционная система, что снимает лимит однозадачности.
С помощью MapReduce 2.0 разработчики могут создавать приложения в рамках Hadoop, а не подключать их извне, как приходилось делать в Hadoop 1.0. Это должно зарекомендовать Hadoop 2.0 как платформу, на базе которой будут создаваться приложения, распоряжающиеся данными намного эффективнее, чем раньше. Именно это, по сути, делает "большие данные" корпоративным инструментом, который просто необходимо использовать, если компания планирует оставаться на гребне волны высоких технологий и распоряжаться имеющимися ресурсами с пользой. Те, кто активно применяет Hadoop и работает с большими объёмами данных, уже наверняка изучили релиз, обновляют платформу и, что называется, начинают снимать урожай. Остальным поясню, что прямая связь между платформой Hadoop и приложениями означает буквально следующее: "большие данные" наконец-то могут быть полезными любой компании на рынке. Поскольку информация, необходимая бизнесу и являющаяся продуктом переработки "больших данных", используется приложениями напрямую, а не опосредованно. Что, как вы понимаете, значительно сокращает дистанцию между простым наличием больших объёмов данных и применением результатов обработки этих данных.
Кроме собственно MapReduce, обновилась и файловая система HDFS. Один из пунктов релиза гласит, что HDFS обзавёлся high availability - методом, позволяющим достигать высокого уровня доступности и устойчивости системы. Для бизнеса это означает возможность создания избыточности в критически важных системах. В этом случае отказ одного из компонентов системы не повлечёт за собой сбой в работе бизнес-приложений, зависящих от поставляемых Hadoop данных. Добавлены также образы (HDFS Snapshots) - возможность создавать копии файловой системы Hadoop, необходимые при сбоях. Ещё одним нововведением стала поддержка файловой системы NFSv3 на тот случай, если потребуется прямой доступ к данным на уровне HDFS.
Хорошей новостью для Windows-сообщества стало то, что, начиная с версии 2.0, Hadoop поддерживает Microsoft Windows. Это определённо подогреет интерес к Hadoop со стороны компаний, работающих и создающих приложения только для Windows-платформ. Ранее работа с "большими данными" вообще и с Hadoop в частности была доступна исключительно для Linux-сообщества, что определённо тормозило развитие платформы в корпоративном мире, где присутствие Microsoft всё ещё намного сильнее, чем Linux.
Подытоживая этот долгожданный и значимый "апдейт" платформы распределённых вычислений стоит отметить, что изменения коснулись всех основных компонентов Hadoop, и в перспективе это сделает его ещё более популярным инструментом обработки данных. И так как компания с желтым слоном на логотипе прочно ассоциируется с "большими данными", Hadoop 2.0 обязательно станет большим шагом вперёд для всего рынка Big Data.
- Подробнее о решениях IBM для управления большими данными (IBM Big Data)
- Статьи по теме Big Data
- Новости по теме Big Data
- Услуги по внедрению решений для обработки больших объемов данных
- Заказать проведение презентации
- Консультация по выбору решений и технологий для обработки больших объемов данных (по ссылке открывается анкета):