В большинстве случаев для SQL Server применяются незамысловатые модели управления глубиной очередей ввода-вывода. Ниже представлены основанные на практике рекомендации по оптимизации очереди ввода-вывода, при использовании более развитых моделей дисковых подсистем, SSD - дисков и высокопроизводительных систем хранения.
Автор, наконец, нашёл время для тестирования массива твердотельных дисков (SSD), собирая в массивы от нескольких до 20 устройств, управляемых двумя контроллерами с 4x4 портами Serial Attached SCSI (SAS). Во время предварительных тестов, когда глубина очереди обращения к дискам была очень высокой, он наблюдал большую задержку обращения к дискам, которая во время проведения ряда операций для чтения превышала 100ms и достигала более 400ms для операций записи.
Таким образом, возникают следующие вопросы:
- Так ли уж хорошо сказывается на производительности большая глубина очереди и длительные задержки?
- Способна ли большая глубина очереди породить проблемы со временем отклика других операций?
- Можно ли избежать этих проблем, не теряя в производительности?
Давайте начнём искать ответы на эти вопросы, исследуя принципы использования одиночного диска, после чего необходимо будет проделать все тесты с дисковым массивом под управлением кэширующего RAID контроллера, а затем, уже в конце мы поработаем с полномасштабной системой хранения, подключённой через сеть хранения данных (SAN) и адаптированной для использования SSD дисков. Если обратиться к распространённым рекомендациям по настройке систем хранения, можно увидеть, что они зачастую цитируются без ссылок на соответствующие исследования или явного указания контекста их применимости. Мы же попытаемся проникнуть в самую суть вещей, и понять, почему упрощённая модель организации глубины очереди ввода-вывода, используемая SQL Server для доступа к листовому уровню таблиц, может быть улучшена за счёт более развитых моделей работы с дисками, а также за счёт использования SSD дисков и высокопроизводительных систем хранения данных (СХД).
Теория жёстких дисков (что такое IOPS)
Стандартная теория ввода-вывода подразумевает, что при случайном типе доступа к диску среднее время доступа к данным равно сумме задержек следующих операций:
Позиционирование головки диска над искомой дорожкой (rotational latency);
Среднее время поиска (seek time);
Время передачи данных (transfer time);
Издержки на обработку команд (command overhead);
Задержки при доставке данных инициатору запроса (propagation delays).
Для запросов ввода-вывода с маленькими величинами блоков данных существенны только два первых слагаемых. Для дисков с 15000 оборотами на шпинделе (15K) среднее значение "rotational latency" составляет 2 ms, а для типичного 3,5 дюймового диска с 15K среднее число "seek time" около 3,4 ms. Включая эти два наиболее весомых значения и другие, менее значимые составляющие, общее время доступа может достигать в среднем до 5,5 ms. В результате чего можно выделить два ключевых признака:
При произвольном доступе к данным, они считаются распределёнными по всему диску.
При глубине очереди 1, выполняется один запрос на ввод-вывод; следующий запрос выполняется после завершения предыдущего. Для 15K диска можно получить до 180 операций ввода-вывода в секунду (IOPS) с глубиной очереди 1 и при произвольном доступе к данным, которые рассредоточены по всему диску.
А очень часто просто забывают упомянуть про эти два ключевых фактора!
В случае если доступ осуществляется к данным, хранящимся на относительно небольшой группе сопредельных цилиндров диска, среднее время поиска будет меньше, а при глубине очереди равной 1 производительность в IOPS-ах окажется выше.
Случайное чтения с жёсткого диска и варьирование глубины очереди - сравнение в IOPS-сах
Давайте теперь обратимся к смыслу второго из упомянутых выше факторов, и попытаемся сопоставить в IOPS-ах случайное чтение и чтение при разной глубине очереди. При более глубокой очереди можно наблюдать множество запросов ввода-вывода к диску, которые обслуживаются вместе, или возможно обслуживание более поздних запросов ввода-вывода до завершения более ранних. Дисковый контроллер может переупорядочить ввод-вывод, стараясь сократить время между отдельными порциями ввода-вывода, что позволяет увеличить IOPS-ы и при этом получить более высокие значения задержек для каждого отдельного запроса ввода-вывода.
Ситуация становится незначительно лучше, если увеличить глубину очереди до 2-х. Можно получить до 200 IOPS, против упомянутых выше 180-ти. Ещё лучше результаты получаются при глубине очереди равной 4 - 240 IOPS. Если продолжить удваивать глубину очереди вплоть до 32-х, можно получить ещё небольшой прирост на каждое приращение, порядка 40-50 IOPS каждое. После этого, до глубины очереди равной 64 увеличение будет совсем незначительное. К слову, диски, выпущенные до 2005 года, могли обслуживать очереди до 64 задач. Современным дискам по плечу очередь глубиной 128. При каждом удвоении глубины очереди также происходит практически удвоение задержки.
На рисунке №1 показано какой эффект оказывает увеличение глубины очереди на производительность в IOPS. На рисунке видно, что при глубине очереди запросов ввода-вывода равной 64-м, когда данные распределены по всему диску, удавалось получить до 400 IOPS. Другой, граничный случай, когда данные занимали 2,8% диска, примечателен повышением производительности относительно других измерений, с меньшими глубинами очереди. Так, например, для глубины очереди 1, удалось достичь почти 300 IOPS.
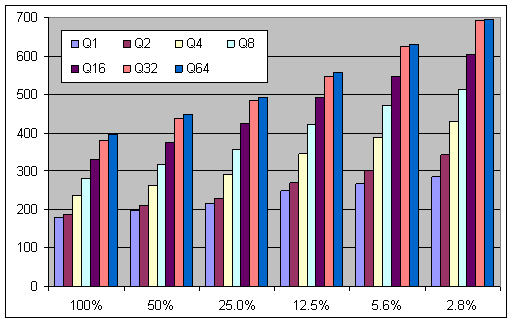
Рисунок 1: Зависимость производительности в IOPS от глубины очереди при разном объёме данных не диске.
Если грамотно учесть оба фактора, можно поднять производительность до 600 IOPS на диск.
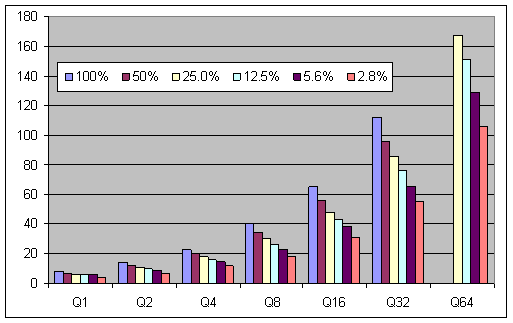
Рисунок 2: Зависимость задержки от глубины очереди при разном объёме данных не диске.
На рисунке №2 показано, как зависит величина задержки доступа от глубины очереди при разном проценте заполнения диска данными. При большой глубине очереди и когда данные занимают весь диск, величины задержек достигают самых больших значений.
Если процент запрашиваемых данных невелик, то потери от задержек будут заметно меньше, даже если глубина очереди велика. Снижение глубины очереди или процента запрашиваемых с диска данных положительно сказывается на производительности жёсткого диска, но когда оба фактора задействованы одновременно, выигрыш поистине впечатляющий. Для характерных OLTP нагрузок время отклика (а, следовательно, и задержка ввода-вывода диска) имеет такое же большое значение, как и такой показатель производительности, как пропускная способность. Именно поэтому, такое большое распространения получило правило поддерживать для OLTP среднюю глубину очереди, которая не превышает двух запросов на диск (шпиндель). Это правило было популярно в то время, когда наибольшее распространение имели диски со скоростью вращение шпинделя 7200 и 5400 об/мин.
При пакетной обработке данных, когда нет пользователей, ожидающих завершения каждой транзакции, правило управления глубиной очереди сводится к увеличению глубины, что может положительно сказаться на производительности и пропускной способности. Однако, при работе с хранилищами данных систем поддержки принятия решений (DSS), принято руководствоваться правилом, которое гласит, что можно задействовать ту часть пропускной способности, которая в данный момент не используется.
Стоит особо подчеркнуть важность перечисленных ключевых факторов, поскольку до сих пор принято было опираться на правило, которое гласит: "глубина очереди одного диска должна быть не выше 2".
RAID - контроллеры и дисковые массивы
В былые времена мы оперировали в основном группами дисков (JBOD). Популярные РСУБД учитывали этот подход, обеспечивая поддержку для баз данных множества файлов и файловых групп. Затем появились light-RAID (не путать с названием книги) и RAID- контроллеры. Все увидели, что RAID позволяет значительно сократить количество "дисков", которыми приходится управлять на уровнях базы данных и операционной системы. Дисковый массив представляется в последней как один логический диск, а счётчики производительности, обычно, используются те, что предоставляет она, а не система хранения данных (СХД).
Правило, по которому глубина очереди не должна для одного диска превышать 2 (и другие сопутствующие признаки) не соотносятся напрямую с глубиной очереди, определённой по счётчикам производительности операционной системы. Таким образом, получило распространение несколько иное правило, гласящие, что задержки при обращении к диску не должны превышать примерно 10 - 20 ms, что было вычислено из прежнего правила глубины очереди 2 на диск (вероятно, для дисков с 7200/10000 об/мин), причём, без учёта описанных выше дополнительных признаков.
В большинстве случаев задержка доступа к данным ниже 10 ms говорит о том, что время отклика транзакции считается очень хорошим. Задержки в диапазоне 10 - 20 ms говорят о приемлемом времени отклика транзакции. Задержки больше 20 ms говорят о большой загруженности дисковой подсистемы. Важно понимать, что появление кратковременных скачков ввода-вывода может привести к тому, что рассчитанная по задержкам глубина очереди может оказаться высокой, в то время как время отклика будет характеризоваться картиной с острыми пиками значений. Т.е. несмотря на то, что среднее время отклика транзакции можно считать приемлемым, может существовать большое число запросов с очень плохим временем отклика.
Что происходит с глубиной очереди для RAID массива при случайном чтении
Как повлияет на характеристики ввода-вывода использование нескольких дисков, собранных в один RAID - массив? Если происходит чтение с такого логического диска, то это равносильно тому, что ввод-вывод будет направлен только на один диск массива (то есть, глубина очереди = 1), и всего один из дисков обслужит ввод-вывод. Остальные диски будут практически невостребованны, пока активность из расчёта на один диск не превысит 180 IOPS, направленных на эту группу дисков в RAID - массиве. При глубине очереди 2, вероятно, что пара запросов ввода-вывода распределилась бы между разными дисками, таким образом, что два диска будут работать с глубиной очереди 1, а остальные диски останутся неактивными. Очередь к одному диску массива станет больше единицы только тогда, когда нагрузка на массив превысит возможности обслуживания без очередей запросов ко всем дискам, которые сегодня позволяют получать 180 IOPS при 15 K оборотов на шпинделе, и с небольшой корректировкой из-за вероятности неравномерного распределения нагрузки.
Глубина очереди всего массива будет поделена между несколькими очередями к его отдельным дискам и, в зависимости от производительности в IOPS-ах входящего в массив диска, будет определяться зависимость производительности от глубины очереди к RAID - массиву. Тут важным моментом является то, что при глубине очереди 1, запрос ввода-вывода попадёт на один из дисков со своими характеристиками по IOPS, которые будут отличаться от производительности в IOPS-ах всей дисковой группы RAID - массива.
Задержка записи в журнал
В те времена, когда диски подключались напрямую к серверу, распространённой рекомендацией было использовать для файла журнала отдельный массив RAID1, т.е. пара зеркальных дисков рекомендовалась для каждого журнала транзакций базы данных с высокой транзакционной нагрузкой. Об этом редко говорят, но наиболее характерным значением величины задержки для операций записи в журнал (которые имеют характер последовательного ввод-вывода и маленький размер блока запроса) была величина, сопоставимая с 0.3ms, что приблизительно соответствовало 3000-5000 IOPS.
Производители оборудования сетей SAN часто рекомендуют не беспокоиться о выделении отдельных физических дисков для каждого журнала транзакций высокотранзакционной базы. Подразумевается, что внешняя дисковая подсистема, настроенная по рекомендациям вендора, сама прекрасно справится с этой задачей. Однако, такие результаты с очень низкой задержкой записи в журнал, как у напрямую подключённых дисков (которые, к тому же, могут обслуживаться выделенным процессором) для сетей SAN всё ещё недостижимы. Поскольку системы хранения в сетях SAN получают всё большее распространение, Microsoft внёс изменения в ядро хранения SQL Server, чтобы обеспечить возможность многопоточной записи в журнал транзакций (SQL Server 2000 SP4 и 2005 RTM позволяли обслуживать 8 одновременных запросов ввода-вывода в журнал транзакций каждой базы данных). SQL Server 2005 SP1 позволяет одновременное обслуживание 8 запросов ввода-выводов для 32-разрядной редакции SQL Server и 32-х запросов ввода-вывода для 64-разрядной редакции сервера, с предельным размером запроса 480KB. В SQL Server 2008 предельный размер повышен до 3840KB.
Случайная запись на RAID маленькими блоками
В этой статье мы не станем рассматривать те издержки записи, которые происходят внутри RAID. Однако нужно отметить, что правила для RAID5 и RAID10 часто цитируются без учёта описанных выше признаков. Как правило, говорят о производительности операций записи RAID5 и только применительно к случайной записи маленькими блоками. На контроллере без кэширования можно получать производительность ввода-вывода для записи в IOPS близкую к аналогичным характеристикам для чтения. Стоит отдельно отметить, что результаты сравнения могут отличаться для разных уровней RAID, поскольку у них разные издержки, а также на это может влиять специфика выбранной модели контроллера.
Кэширующие RAID - контроллеры и запросы ввода-вывода на чтение
В других статьях блога автор уже объяснял, почему такое кэширование запросов на чтение непродуктивно. В основном это объясняется тем, что ядро базы данных само кэширует данные, и этот кэш намного ближе и менее затратен с точки зрения доступа, чем кэш контроллера СХД. Кроме того, если сервер сконфигурирован в соответствии с рекомендациями, ядро базы данных будет иметь буферный кэш существенно большего размера, чем кэш СХД. Вероятность того, что к данным в кэше СХД будет осуществляться повторный доступ, очень мала. К тому же, издержки на кэширование запросов чтения являются для них весьма существенными, и это важный фактор для тех СХД, которые настраиваются на получение высоких значений IOPS. Издержки кэширования чтения на контроллерах СХД будут потому, что блоки данных в кэше никогда не будут запрашиваться снова, это работа будет бесполезна. У систем, которые используются в эталонных тестах TPC, кэширование чтения обычно отключается, и делается это из соображений, которые были только что перечислены.
Один уважаемый источник утверждал, что использование маленького ~ 2MB (не GB!) кэша чтения для LUN, позволяющего включить упреждающее чтение, является наиболее удачной стратегией. Я же помню, когда-то говорили, что некоторая система с сервером, у которого было 48GB оперативной памяти, показала лучшую производительности ввода-вывода, когда кэш на SAN был увеличен с 80GB до 120GB. Всё это показывает, что подобные результаты можно рассматривать под разными углами.
Кэширующие RAID - контроллеры и запросы ввода-вывода на запись
А теперь давайте обратимся к показателям производительности запросов ввода-вывода для записи, носящих случайный характер и обсуживающихся кэширующим RAID - контроллером. До сих пор, мы только ходили вокруг запросов ввода-вывода на запись, но на это есть своя причина. На Рисунке 3 показана производительность в IOPS для случайных запросов на запись с маленьким блоком, которые обслуживает кэширующий RAID - контроллер. Когда SQL Server или операционная система посылают RAID - контроллеру один или более запросов ввода-вывода для записи, записываемые данные помещаются в кэш контроллера, а серверу отправляется сообщение о завершении операции записи. После этого, становится возможным отправка следующего запроса ввода-вывода. При этом каких либо заметных изменений в производительности СХД в IOPS не произойдёт, хотя глубина очереди будет расти. Будет наблюдаться очень низкая задержка операций записи, пока не будет преодолено наивысшее значение IOPS для возможностей кеширующего контроллера.
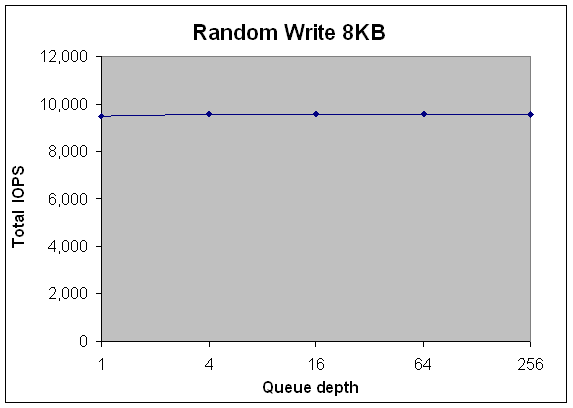
Рисунок 3: пример IOPS для случайных запросов записи с маленьким блоком и с кэширующим RAID - контроллером
После преодоления этого порога, когда кэш записи будет заполнен, величина задержки запроса станет высокой, пока сервер не вернётся в исходное состояние, с небольшим объёмом запросов ввода-вывода на запись.
Большие СХД с большими наборами RAID
На протяжении нескольких лет СХД становились всё более мощными, их вычислительные возможности увеличивались на 40% ежегодно. В то же время производительность жёстких дисков в год растёт не так заметно, в среднем меньше чем на 10% (от 7,2K к 10K и к 15K, и это ничто по сравнению с SSD). Этот разрыв в росте вызвал необходимость создания СХД с очень большими количествами дисков. Именно в те времена получили распространение сети SAN, которые придумали специально для больших СХД.
Очень быстро стало понятно, что SAN не могут обеспечить ожидаемую производительность в IOPS, которую может суммарно выдать задействованное число дисков. Первая причина этого заключается в возможностях контроллера адаптера шины Fibre Channel (FC HBA), для которого глубина очереди по умолчанию составляла 32 (на адаптер, а не на порт СХД). Такое ограничение для значения очереди по умолчанию было введено из тех соображений, что доктриной SAN считается следующее: SAN - это поставщик совместно используемого дискового пространства. Ограничение призвано препятствовать тому, чтобы один узел создавал слишком большую нагрузку ввода-вывода. Для ограничения нагрузки, на HBA для глубины очереди устанавливали маленькое значение, в результате чего все узлы могли бы гарантировано получать свою долю от максимально возможного объёма ввода-вывода.
Если измерить зависимость IOPS от установки глубины очереди на HBA для внешнего LUN, состоявшего из большого числа дисков, станет видно, что производительность в IOPS увеличивается с увеличением глубины очереди от минимальных до максимальных значений. Это поведение похоже на то, о котором мы говорили выше, когда обсуждали зависимость производительности RAID массивов в IOPS от глубины очереди.
Если увеличивать глубину очереди с минимума до максимально возможных значений, можно достичь близкую к максимуму пропускную способность, но одновременно получить рост задержек.
Выбор глубины очереди для FC HBA
Важно помнить, что раньше глубина очереди устанавливалась ко всем портам HBA или для каждого оптического порт HBA в отдельности. У последних моделей Emulex FC HBA значением по умолчанию для глубины очереди устанавливается 32 на каждый LUN. Можно настроить глубину для LUN или для всего получателя (target). QLogic использует для этого термина "Execution Throttle" и глубина по умолчанию равна 256. Как то, в одном из отчётов к эталонному тесту TPC-C, в котором использовалась система с сетью хранения SAN, была дана ссылка на зависимость производительности от изменения глубины очереди HBA: глубина менялась от 32 до 254 и без каких-либо дополнительных разъяснений. В системах для TPC-C всегда используются очень большое количество дисковых массивов. Конечно же, для таких систем следует выбрать установку глубины очереди на HBA в максимальное значение. В упомянутом документе об этом было сказано в краткой форме, и рекомендовано изменить глубину очереди HBA с 32 до 254, что соответствует рекомендованным практикам, часто встречающимся в документах Microsoft. Те документы, которые я видел, не содержали в себе объяснения первопричины такого эффекта и в них отсутствовали рекомендации по поддержке данного варианта настроек.
Стоит поговорить о конфигурации SAN с небольшим числом дисковых массивов. Резонен вопрос, нужно ли менять стандартную установку глубины очереди на LUN, если каждый LUN состоит из четырёх дисков? Требуется ли в таком случае увеличивать глубину очереди до 254? Ответ будет зависеть от тех инструкций, которые были даны ранее при обсуждении зависимости производительности в IOPS и задержек от глубины очереди, с учётом поправок на число дисков, которые относятся к LUN. Необходимо взвесить все за и против, и в дальнейшем исходить из того, является ли вашей целью обеспечение высокой скорости отклика, присущей OLTP системам, или вы предпочитаете работать с чистой пакетной/DSS нагрузкой.
Последовательный ввод-вывод
Все разговоры о зависимости IOPS от глубины очереди до сих пор не касались варианта с последовательным дисковым вводом-выводом. Последовательного ввода-вывода с большими блоками и глубиной очереди 1 на каждый LUN может оказаться вполне достаточно, чтобы утилизировать максимальную пропускную способность ввода-вывода, при условии, что эта нагрузка достаточно большая, и её хватало бы для загрузки всех дисков, из которых состоит LUN. Автор склонен полагать, что, следуя теории, размер нагрузки ввода-вывода помноженный на глубину очереди должен быть больше чем число дисков в массиве, помноженное на размер блока RAID - массива (размер сегмента/чанка/блока страйпа). Эта уверенность основывается на том, что у каждого диска будет для обслуживания своя доля ввода-вывода, даже, несмотря на то, что у автора не было возможности проверить эту гипотезу практическими тестами.
Увеличение глубины очереди от минимального значения в попытке достигнуть близкой к максимуму пропускной способности, приведёт только к увеличению задержек. В том случае, когда мы имеем дело со смешанной рабочей нагрузкой, когда обслуживается смесь из запросов с маленьким и большим блоком, можно попробовать более высокую глубину очереди. Для больших блоков это, в принципе, может поднять пропускную способность, но автор это тоже не проверял. Что касательно сетей SAN, то для них существуют некоторые предположения, согласно которым увеличение глубины очереди может помочь достичь максимальной пропускной способности при последовательной нагрузке, когда на одном RAID массиве создано несколько LUN. Сколько-нибудь подробных разъяснения на этот счёт автором найдено не было.
Характеристики ввода-вывода SQL Server
Есть несколько документов Microsoft, которые подробно описывают ввод-вывод SQL Server. Этот список включает:
Блог CSS SQL Server Engineers: How It Works: Bob Dorr's SQL Server I/O Presentation
Презентация Microsoft SQL Server I/O Internals
Статья базы знаний (917047) Требования к подсистеме ввода/вывода для Microsoft SQL Server для базы данных tempdb
Техническая статья об SQL Server, написанная Emily Wilson, Mike Ruthruff и Thomas Kejser: Analyzing I/O Characteristics and Sizing Storage Systems for SQL Server Database Applications
Статься Craig Freedman: Random Prefetching
В комплекте электронной документации SQL Server 2008 R2 Books Online в главе "Управление буферами/Считывание страниц" сказано следующее: "Механизм упреждающего чтения позволяет компоненту Database Engine считывать из одного файла до 64 последовательных страниц (512 КБ). Эта операция выполняется как единая последовательность разборки-сборки для соответствующего числа буферов в буферном кэше (возможно, расположенных не последовательно)". Автор также приводит информацию, что при сканировании таблиц ввод-вывод SQL Server организован таким образом, чтобы попытаться склеить упреждающим чтением 1024 страницы для редакции Enterprise Edition, или 128 страниц упреждающего чтения для редакции Standard Edition.
Синхронный и асинхронный ввод-вывод SQL Server
При случайном доступе с размером запроса 8KB (что характерно для таких операторов Плана исполнения запроса, как Поиск Закладок и LOOP JOIN) SQL Server может переключиться с синхронного ввода-вывода на асинхронный. В этом случае он будет использовать порции приблизительно по 25 строк.
Рассмотрите ситуацию, обычную для транзакционных систем, которые также обслуживают задачи отчётности. Транзакции состоят из нескольких последовательно обслуживаемых запросов ввода-вывода с глубиной очереди 1. Отчёт - это запрос, который может генерировать несколько сотен запросов ввода-вывода, обслуживаемых асинхронно с большой глубиной очереди. Предположим, что для транзакций, которые будут присутствовать в данном случае, средняя глубина очереди на один диск составит 1, а средняя задержка доступа составит 5ms. Допустим, что для транзакции нужно 20 синхронных запросов ввода-вывода, которые по нашим выкладкам завершаться за 100 ms, что является разумным временем отклика. Теперь выполним сценарий отчёта, который генерирует асинхронный ввод-вывод и он достигает значений глубины очереди к диску порядка 8, с задержками около 30 ms. Отчёт выполнится быстро, потому что СХД обеспечивает 350 IOPS на диск. Но зато транзакция с 20 последовательными запросами ввода-вывода теперь отработает за 600ms. Хотя со стороны может показаться, что отчёты имеют более высокий приоритет, чем обслуживание коротких транзакций.
Замечания относительно Tempdb
Часто ввод-вывод SQL Server в системную базу данных tempdb характеризуется большой глубиной очереди. Это происходит потому, что запросы к этой базе характеризуются большими операциями с хэшами или сортировками. Если бы для таких операций нужно было меньше ресурсов, то работа с ними выполнялись только в оперативной памяти. Таким образом, виновниками в нагрузке на tempdb часто становятся слишком большие для данной системы запросы, которые порождают запросы асинхронного ввода-вывода с большой глубиной очереди.
Если руководствоваться только простым правилом что задержки ввода-вывода должны быть ниже 20 ms, то можно сделать вывод о перегрузке выделенных под tempdb дисков, потому что средние значения задержек будут очень большими. На самом же деле SQL Server просто старается держаться в рамках стратегии достижения максимальной производительности, используя для этого метрики, которые ориентированы на пропускную способность. Правильной метрикой в данном случае будет возможность дисков под tempdb обслужить достаточный для поддержания высокой производительности объем запросов ввода-вывода, и не факт, что при этом объём ввода-вывода с tempdb должен быть низким.
При сканировании таблиц ввод-вывод SQL Server организован таким образом, чтобы попытаться склеить упреждающим чтением 1024 страницы для редакции Enterprise Edition, или 128 страниц упреждающего чтения для редакции Standard Edition.
Большая глубина очереди для SQL Server + SSD
Автор наблюдал у запроса с полным сканированием таблицы, в котором не было подсказок оптимизатору уровня изоляции блокировок, глубину очереди запросов ввода-вывода на чтение порядка 1300. Размер запроса ввода-вывода составлял 8KB, а задержки для операций чтения были больше 200 ms, и это несмотря на то, что данные хранились на SSD дисках. Когда указывалась блокировка таблицы, число запросов ввода-вывода составляло приблизительно 500K (вероятно, основная масса в 512K разбавлялась небольшим вводом-выводом с маленьким размером блока), задержка дисковых операций получалась меньше 50 ms, а глубина очереди была приблизительно 40. Для поиска по ключу мы наблюдали ввод-вывод блоками 8 КB c глубиной очереди приблизительно 160, и с задержкой порядка 7 ms. Когда использовалось СХД с приблизительно 20 HDD дисками, глубина очереди была около 160, это приблизительно 8 на один диск, что было вполне приемлемо для производительности ввода-вывода, и результирующие задержки ещё не составляли проблемы.
Marc Bevand в блоге Zorinaq's указал, что число IOPS при глубине очереди 1 являются по существу мерой задержки. Предположим, что SSD имеет задержку 100 µs, и обеспечивает 30K IOPS для 8 KB IO (30K x 8KB = 240 MB). Получается, что при глубине очереди 1 в IOPS должно получатся 10K (1000000 µs/s/100µs). Таким образом, теория говорит нам о том, что глубина очереди 3 или больше может обеспечить производительность до 30K IOPS. Удержание глубины очереди, близкое к её минимальным значениям, необходимо, чтобы не пострадала максимальная производительность в IOPS для запросов, которые порождают огромные объёмы ввода-вывода, и для того, чтобы обеспечить хорошее время отклика для других, выполняющихся параллельно запросов.
Большая задержка записи при создании кластеризованных индексов
Команда CREATE CLUSTERED INDEX, как показывали наши наблюдения, сопровождалась очень высокой задержкой для записи. Глубина очереди достигала 500, задержка превышала 600 ms, а размер запроса ввода-вывода составлял в среднем 100 KB. Поскольку такие высокие значения задержек нежелательны во время работы пользователей, нужно стараться этого не допускать. В любом случае, принуждение СХД обслуживать такой большой ввод-вывод не имеет никакого смысла. И у кэширующих RAID - контроллеров и у SSD при записи предел пропускной способности ввода-вывода может достигаться даже при значительно меньшей глубине очереди. Увеличение объёма ввода-вывода до такой степени негативно повлияет на доступность системы для других запросов ввода-вывода, отправляемых на обслуживание тем же дискам, обслуживающим большой объём операций.
Влияние на статистику ожиданий асинхронных операций
Перед тем, как подвести черту под нашим обзором всего того, что связано с глубиной очереди ввода-вывода, автор хочет кратко коснуться темы зависимости статистики ожиданий от типа операций ввода-вывода. Сегодня можно часто слышать рекомендации по использованию в качестве базовой метрики оптимизации ввода-вывода данных исключительно о статистике ожиданий. Рассмотрим следующий пример: наша СХД состоит из 100 дисков, запрос генерирует 1 миллион операций ввода-вывода - если используется синхронный ввод-вывод с глубиной очереди 1 на каждый диск, или 100 ко всем дискам системы хранения, то мы получим 200 IOPS на один диск или 20000 IOPS для всей СХД. При этом задержка обращения к диску составит 5 ms. Тогда получается, что время исполнения запроса займёт 50 sec. Суммарное время ожиданий (total wait time) составит 5 ms для одного запроса ввода-вывода или 5000 sec для миллиона операций ввода-вывода.
Теперь рассмотрим асинхронный ввод-вывод, при котором глубина очереди к диску будет 16, при 400 IOPS на диск и с задержкой на 40 ms. Запрос с миллионом операций ввода-вывода теперь завершится за 25 sec, но суммарное время ожиданий составит при этом 40000 sec. Этот пример показывает, что всегда важно опираться в своих оценках на правильные метрики и использовать для принятия решения о способах и методах оптимизации ввода-вывода не только статистику ожиданий, но и показания соответствующих счётчиков производительности.
Резюме обзора глубины очереди ввода-вывода
Мы постарались кратко рассмотреть, на какие ключевые компоненты может воздействовать стратегия выбора глубины очереди ввода-вывода. Можно выделить следующие важные моменты:
Результаты случайного чтения с дисков, измеренные в IOPS, могут выиграть от увеличения глубины очереди за счёт задержек.
Для последовательного ввода-вывода большая глубина очереди не нужна, ему достаточно, чтобы все диски были загружены обслуживанием запроса ввода-вывода. Использование упреждающего чтения более чем 1024 страниц, при обслуживании сканирования таблиц, кажется вполне логичным, если запрос ввода-вывода оперирует большими блоками. Но также вполне реалистичен сценарий, когда вместо этого мы будем иметь дело с массированным вводом-выводом, у которого размер блока всего 8KB и глубокая очередь. В последнем случае, нужно внести коррективы в стратегию организации ввода-вывода, учитывая реальный размер ввода-вывода, или, возможно, потребуется выяснить, почему ввод-вывод деградирует до 8KB, если таблица при этом не фрагментирована?
При использовании RAID-контроллера с кэшированием записи, носящие случайный характер операции записи не нуждаются в увеличении глубины очереди в целях повышения производительности таких операций.
При использовании системы хранения с SSD дисками тоже нет смысла путём повышения глубины очереди повышать производительность операций ввода-вывода.
По мнению автора статьи, SQL Server придерживается заранее установленной стратегии выбора глубины очереди запросов ввода-вывода, которая зависит только от редакции сервера (Standard или Enterprise). Число дисков, из которых собран любой LUN, стратегией не учитывается; характер нагрузки (OLTP или DW/DSS) не учитывается. Однако оптимизировать производительность операций ввода-вывода могут помочь несколько замечаний к той стратегии, которую вы будете реализовывать для своих приложений:
Последовательный ввод-вывод не должен использовать упреждающее чтение более 1024 страниц, если размер блока запроса ввода-вывода составляет 8 KB.
Примите в расчёт, что ввод-вывод операций записи, обслуживаемый контроллером с включённым кэшированием записи, должен иметь меньшие значения глубины очереди.
Важно скорректировать глубину очереди ввода-вывода для случайного чтения с учётом особенностей разных типов устройств хранения: HDD или SSD.
Полезно скорректировать ввод-вывод для случайного чтения (для обычных HDD) с учётом модели использования: OLTP или DW/DSS.
Полезно скорректировать ввод-вывод для случайного чтения (для обычных HDD), учитывая число дисков в LUN.
Некоторые представленные выше рекомендации вполне могут реализоваться автоматически. А другие могут потребовать внесения изменений в параметры глобальной конфигурации, которые меняются с помощью системной процедуры sp_configure. В качестве универсального совета можно выделить одно: вносите такие корректировки, которые позволят учесть особенности пользовательской нагрузки, благодаря чему значительно повысится удобство работы пользователей с SQL Server. Сегодня, существует большое количество возможностей загнать SQL Server в "ступор", заставив его обслуживать массированные дисковые операции и огромные очереди, и тогда не помогут даже хранилища с SSD дисками. Только очень большие, отлично сконфигурированные системы хранения могут быть неуязвимы для таких проблем.
По материалам статьи Джо Чанг (Joe Chang): I/O Queue Depth Strategy for Peak Performance (IO Queue Depth Strategy)
Перевод: Александр Гладченко
Технический редактор: Ирина Наумова
Литературный редактор: Мария Гладченко