Сегодня предприятиям требуется своевременная информация. Пользователей перестала удовлетворять ситуация, когда они получают отчеты один раз в день, теперь некоторым требуется получать отчеты ежечасно (или даже каждые несколько минут). Для того чтобы обеспечить требования бизнеса при анализе постоянно растущего набора бизнес-данных, требуется уметь своевременно выполнять любой анализ. Это становится все большей и большей проблемой, особенно в тех случаях, когда анализ проводится по огромным объемам данных и в нем могут быть задействованы трудоёмкие операции типа соединений и агрегирования, а также выполняться различные аналитические функции и сравнения. Если у вас имеется возможность выполнить такие операции предварительно, это может помочь обеспечить быстрое время ответа на запросы и более быстрое выполнение анализа.
В предлагаемой вашему вниманию статье обсуждаются два доступные в Oracle Database 11g подхода для предварительного вычисления этих операций запросов и сокращения времени ответа на запросы: материализованные представления с переписыванием запросов и кубы в аналитических рабочих областях.
БЫСТРАЯ ОТЧЕТНОСТЬ - СРАВНЕНИЕ ПОДХОДОВ
Сегодня перестали кого-либо удивлять базы данных размером в несколько терабайтов. В тех случаях, когда не используется ни одна из описанных в этой Белой книге методик, запросы будут получить доступ к этим данным в базе данных непосредственно во время выполнения запроса, что может привести к значительной задержке перед возвращением результатов пользователю. Следовательно, чтобы быть в состоянии повысить производительность запросов, некоторые части операций запроса должны быть выполнены заранее. Это может быть сделано с использованием материализованных представлений, которые содержат предварительно вычисленные результаты, и переписывания запросов, при котором происходит прозрачное переписывание SQL-запросов таким образом, чтобы они обращались к материализованным представлениям, или это может быть выполнено с использованием аналитических рабочих областей и кубов. Хотя в Oracle Database 11g у аналитических рабочих областей теперь также появилась возможность использовать материализованные представления и переписывание запросов.
Сначала мы должны более детально оценить эти две возможности внутри базы данных. В этой Белой книге везде предполагается, что читатель знаком с основными принципами организации хранилищ данных, например, с таблицами фактов, измерениями и иерархиями, и с тем, как они используются и реализуются в Oracle Database.
Краткий обзор материализованных представлений
Материализованные представления и переписывание запросов являются частью возможности, известной, как управление итогами (Summary Management), которая была включена в базу данных, начиная с Oracle8i. В материализованных представлениях предварительно вычисляются и сохраняются результаты запроса к базе данных, в котором при желании могут быть использованы соединения, агрегирования или и те, и другие. Подобно индексу, для хранения материализованного представления требуется пространство на диске (в дополнение к тому пространству, которое требуется для хранения самих таблиц). С точки зрения приносимой ими при решении проблемы производительности запросов пользы, все дело в том, что трудоёмкие операции соединения и агрегирования были выполнены при создании материализованные представления, еще до того, как они должны были быть использованы для ответа на запрос пользователя.
Реальная мощь, скрывающаяся за материализованными представлениями и переписыванием запросов, заключается в том, что их использование является прозрачным для пользователя. Точно так же, как пользователь не обязан знать об индексах для таблицы и, тем не менее, использовать их, так и пользователь не обязан знать о наличии, структуре и контенте (информационном наполнении) материализованного представления. Переписывание запросов допускает такое прозрачное использование материализованных представлений и такой механизм оптимизации запросов, в результате которых первоначальный SQL-запрос, который был написан к базовым таблицам, автоматически переписывается оптимизатором таким образом, чтобы он обращался к соответствующим материализованным представлениям.
Краткий обзор аналитических рабочих областей
Альтернативный подход состоит в использовании Oracle OLAP. Это была дополнительная опция Oracle Database Enterprise Edition, начиная с Oracle 9i. Oracle OLAP, используя кубы и измерения, позволяет сохранять данные в базе данных в специальном формате, который обеспечивает быстрый анализ и составление отчетов по запросам.
Традиционно запросы к хранилищам данных создавались для ответа на вопросы, типа "Какова прибыль, полученная каждым региональный подразделением?". Но организации быстро поняли, что огромное количество данных, содержащихся в их хранилищах, дает возможность получать намного более интересные и сложные отчеты и выполнять гораздо более сложный анализ этих данных. Теперь типичный запрос имеет вид: "Каково изменение процента объемов продаж электронных продуктов, проданных заказчикам в США, за два календарных кварталов этого года по сравнению с аналогичными кварталами прошлого года" .
Подобный тип запроса часто называют многомерным запросом, и бизнес-аналитики создают эти запросы в онлайновом режиме, а также создают и уточняют "продольную и поперечную нарезку" (slice and dice) представления полученных данных, чтобы раскрыть и выделить основные тенденции. Именно это и послужило причиной рождения термина online analytical processing (онлайновая аналитическая обработка) , или OLAP. Многомерный запрос выражает бизнес-вопрос в терминах нескольких измерений, описывающих данные. В приведенном выше примере данные - это данные о продажах (Sales), а измерениями являются Время (Time), Продукты (Products) и Заказчики (Customers). В этом случае - то географическое местоположение в США, где проживают Заказчики. Запросы подобного типа может оказаться довольно трудно выразить в реляционном виде с использованием SQL, но их можно весьма просто описать в многомерном виде, используя опцию Oracle OLAP.
При аналитической обработке все еще требуется хранить данные, к которым производится обращение, в специализированном формате внутри базы данных Oracle, и она является неотъемлемой частью реализации Oracle OLAP: данные состоят из кубов, содержащих показатели (данные), 'гранями' которых являются измерения, определяющие их уровни и иерархии. На приведенной ниже диаграмме показан один куб, который определяется тремя измерениями,Time, Product и Customer, а ячейками куба являются значения (которые также известны как показатели ). На Рис. 1 измерения упрощены, и в них отображены только самые нижние уровни, например, месяцы для измерения Time. Но в измерения также включаются иерархии, определяющие группирование данных. Так, например, месяцы (Months) сворачиваются в кварталы (Quarters), которые, в свою очередь, сворачиваются в годы (Years).
Опция OLAP в Oracle Database 11g обеспечивает специализированное хранение многомерных данных с помощью аналитических рабочих областей и их обработку с использованием механизма многомерных вычислений (Multidimensional Calculation Engine).
Рис. 1. Куб аналитической рабочей области
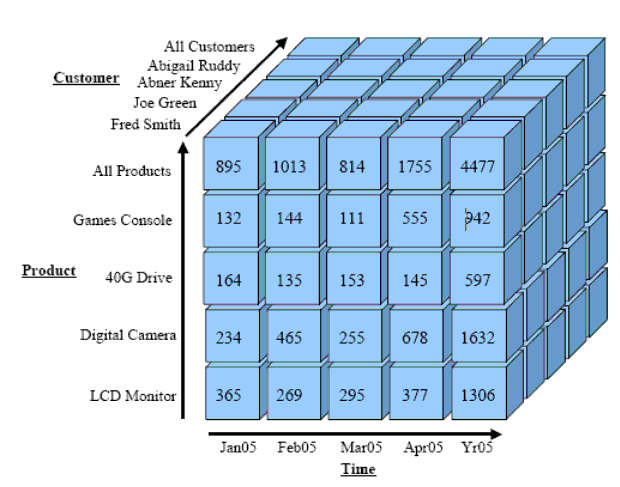
Аналитическая рабочая область (Analytic Workspace - AW) используется для хранения многомерных типов данных, например, измерений, показателей и кубов. Схема базы данных Oracle в дополнение к обычным реляционным объектам: таблицам, индексам и материализованным представлениям, может содержать одну или несколько аналитических рабочих областей.
Механизм многомерных вычислений предлагает функциональность вычислений, которая дает пользователю возможность создавать эффективно выполняющиеся сложные аналитические запросы. Например, такие запросы, которые могут показывать тенденции в данных, сравнивая результаты с предыдущими периодами времени или с другими группировками данных, типа категорий продуктов или географических регионов. Механизм выполняет аналитические запросы, но помимо этого дает возможность конструировать прогнозы и модели тенденций, и выполнять другие типы экспертиз, например, "what if" ("что, если"), в которых обычно также выполняются аналитические операции.
Кроме того, имеется SQL-интерфейс, который дает инструментальным средствам возможность использовать обычный язык SQL для выполнения запросов к аналитической рабочей области. Текст SQL-запроса преобразуется базой данных таким образом, чтобы он работал с объектами аналитической рабочей области, а результаты посредством SQL-интерфейса возвращались (как строки и столбцы) назад в SQL-запрос.
И, наконец, имеется API OLAP. Это интерфейс программирования, дающий приложениям и инструментальным средствам возможность непосредственно обращаться к аналитической рабочей области и механизму вычислений.
Такие продукты Oracle, как Oracle Business Intelligence Discoverer 10g и Excel Spreadsheet Add-In для доступа к аналитическим рабочим областям используют API OLAP.
Совместная работа в Oracle Database
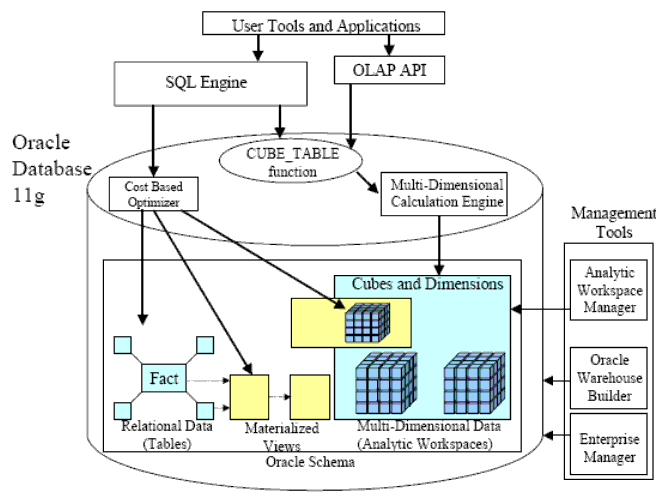
Рис. 2 служит иллюстрацией того, как в Oracle Database 11g и различных инструментальных средствах, используемых для администрирования, аналитические рабочие области сосуществуют с материализованными представлениями и реляционными данными. Материализованные представления используются для хранения предварительно вычисленных результатов, как для реляционных, так и для многомерных данных: стоимостной оптимизатор может теперь переписывать SQL-запросы к аналитической рабочей области, а материализованные представления могут быть определены на кубах.
Рис. 2. Реляционные и многомерные данные в Oracle Database 11g
ОБСУЖДЕНИЕ ДАННЫХ, ИСПОЛЬЗУЕМЫХ В ЭТОЙ БЕЛОЙ КНИГЕ
Перед тем, как начать сравнение, мы сначала обсудим используемые данные, а затем пройдем по шагам методологию, используемую для создания материализованных представлений и аналитических рабочих областей.
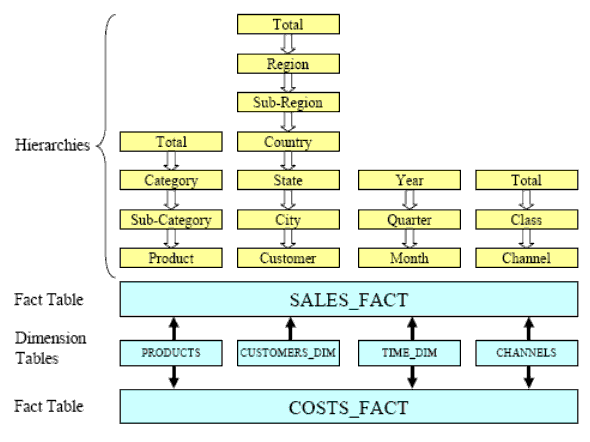
Данные получены из стандартного примера схемы SH (Sales History), предлагаемой на сопутствующем компакт-диске (Companion CD). Для таблицы фактов используются данные Sales; однако они были упрощены путем разагрегации (aggregate out) и удаления измерения Promotions, а также повышения агрегирования фактических данных измерения Time с ежедневного до ежемесячного уровня. Это значит, что теперь базовым уровнем для измерения Time служит месяц. Данные COST для продукта также используются для еще одной таблицы фактов, и они были изменены аналогичным образом, чтобы удалить измерение Promotions и сделать самым нижним уровнем измерения Time месяц. Следовательно, нашими измерениями являются Product, Channel, Customer и Time (Month).
На Рис. 3 показаны получающиеся в результате таблицы фактов и измерений с иерархиями, а также их уровни в каждом измерении.
Рис. 3. Данные запроса, таблицы, измерения и иерархии
Методология для проектирования и построения материализованных представлений
Имеются два метода, которые могут использоваться для определения материализованных представлений: их можно создавать вручную или генерировать по советам, выдаваемых SQL Access Advisor.
Создание материализованного представления вручную
Шаг 1. Понимание запросов
Отправной точкой для создания материализованных представлений является понимание типов соединений и агрегирований, которые используются в запросах пользователей. После этого они анализируются, чтобы определить, какой набор материализованных представлений необходим для их поддержания. Целью проектировщика базы данных является создание как можно меньшего, насколько это возможно, числа материализованных представлений, которые будут поддерживать максимально широкий диапазон запросов.
Шаг 2. Создание материализованного представления
Давайте рассмотрим пример запроса о затратах заказчика в разрезе географических областей и месяцев. Выполнению этого запроса может помочь материализованное представление, которое предварительно вычисляет соединение между таблицей фактов SALES_FACT и таблицами измерений TIME_DIM и CUSTOMERS_DIM, а также выполняет функции агрегирования. Текст SQL для создания материализованного представления показан ниже:
CREATE MATERIALIZED VIEW state_sales_mv
BUILD IMMEDIATE REFRESH FAST ENABLE QUERY REWRITE AS
SELECT c.cust_state_province, c.country_iso_code, m.month_desc,
min(amount_sold) min_amount, max(amount_sold) max_amount,
avg(amount_sold) avg_amount, count(amount_sold) cnt_amount,
count(*) count_all
FROM sales_fact s, time_dim m, customers_dim c
WHERE s.month_id = m.month_id AND s.cust_id = c.cust_id
GROUP BY c.cust_state_province,c.country_iso_code, m.month_desc
Для больших материализованных представлений к приведенному выше оператору может быть добавлена фраза о секционировании, которая приносит материализованным представлениям те же самые выгоды и преимущества, что и секционирование больших таблиц, а именно, повышение масштабируемости, облегчение сопровождения и повышение производительности запросов. Кроме того, применение секционирования базы данных также обеспечивает лучшие возможности обновления, благодаря использованию параллельного DML.
Шаг 3. Определение измерений
Некоторые запросы могут извлечь пользу из определения SQL-измерений, потому что они разрешают большее количество типов переписывания запросов. SQL-измерения - это объекты Oracle, которые определяют иерархические отношения "родитель - потомок". Их настоятельно рекомендуется использовать, потому что они обеспечивают дополнительную информацию для переписывания запросов и делают возможным принятие лучших решений по переписыванию.
Ниже показан оператор CREATE DIMENSION для измерения TIME, который иллюстрирует использование единой иерархии (CALENDAR), имеющей три уровня, и то, как связаны с каждым из этих уровней атрибуты значений данных.
CREATE DIMENSION SH.MONTH_DIM
LEVEL MONTH IS (MONTH_STAR.MONTH_ID)
LEVEL QUARTER IS (MONTH_STAR.QUARTER_ID)
LEVEL YEAR IS (MONTH_STAR.YEAR_ID)
HIERARCHY CALENDAR (MONTH CHILD OF QUARTER CHILD OF YEAR)
ATTRIBUTE MONTH DETERMINES (MONTH_STAR.MONTH_DESC,
MONTH_STAR.MONTH_ENDDATE, MONTH_STAR.MONTH_TIMESPAN)
ATTRIBUTE QUARTER DETERMINES (MONTH_STAR.QUARTER_DESC,
MONTH_STAR.QUARTER_ENDDATE, MONTH_STAR.QUARTER_TIMESPAN)
ATTRIBUTE YEAR DETERMINES (MONTH_STAR.YEAR_DESC,
MONTH_STAR.YEAR_ENDDATE, MONTH_STAR.YEAR_TIMESPAN)
Шаг 4. Построение индексов для материализованных представлений
Так же как индекс, построенный на таблице дает выигрыш запросам к таблице, индексы на материализованных представлениях могут использоваться для повышения производительности запросов, переписываемых с использованием материализованных представлений.
- При построении индексов на материализованных представлениях следует придерживаться тех же правил, что и при выборе индексов для таблиц:
- Индексируемыми столбцами в материализованном представлении должны быть все столбцы, являющиеся столбцами первичных ключей базовых таблиц (потому что для некоторых типов переписывания запросов материализованное представление может быть присоединено к базовой таблице) и
- Индексируемыми столбцами в материализованном представлении должны быть все столбцы, которые используются во фразах WHERE пользовательских запросов.
Помните, что поскольку поддержание индексов является частью процесса обновления материализованного представления, рекомендуется ограничить общее число разворачиваемых индексов, чтобы время обновления не стало чрезмерным.
Шаг 5. Заполнение материализованного представления
Материализованные представления предлагают механизмы заполнения и обновления и контролируют, когда и как они будут заполнены и обновлены. В созданном на шаге 2 представлении STATE_SALES_MV мы определили фразу BUILD IMMEDIATE, которая означает, что материализованное представление будет заполнено сразу после выполнения оператора создания представления. Альтернативно, при использовании фразы BUILD DEFERRED заполнение материализованного представления может быть отсрочено до подходящего момента при следующей операции обновления хранилища. Для материализованного представления должна быть собрана статистика оптимизатора.
Генерация рекомендаций с помощью SQL Access Advisor
Для больших и сложных баз данных определение вручную оптимального набора материализованных представлений и их индексов, поддерживающих запросы пользователей, может стать трудоёмкой задачей. Инструментальное средство SQL Access Advisor, являющееся частью пакета Tuning Pack и ставшее доступным с выходом Oracle Database 10g, значительно упрощает эту задачу и является неоценимым инструментом для этой цели. SQL Access Advisor можно использовать через Advisor Central, входящим в состав Oracle Enterprise Manager, или из командной строки, используя SQL*Plus для вызова одной из процедур пакета DBMS_ADVISOR. Используя на входе рабочую нагрузку SQL-операторов, советник (advisor) шаг за шагом проводит вас по всему процессу, чтобы отрекомендовать материализованные представления, их индексы и журналы материализованного представления, а также как их реализовать. Результаты этого процесса предоставляются как ряд рекомендаций, которые могут быть реализованы через SQL Access Advisor или вручную.
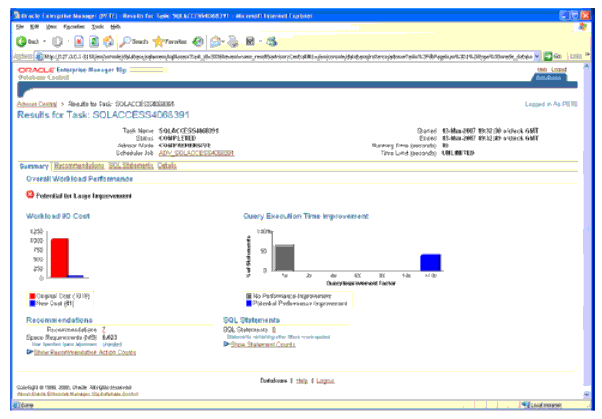
На Рис. 4 показан итоговый экран, получающийся после выполнения SQL Access Advisor с пользовательской рабочей нагрузкой, содержащей наши восемь сценариев запросов. Можно видеть, что советник сделал некоторые рекомендации, которые, по его предсказаниям, могут привести к существенному повышению производительности. После этого можно перейти к другим экранам, чтобы исследовать и модифицировать сгенерированные сценарии, например, изменить имена и табличные пространства для материализованного представления, а затем задача может быть спланирована для развертывания в базе данных хранилища данных.
Рис. 4. Итоговый экран SQL Access Advisor
Методология определения аналитической рабочей области
Процесс построения аналитической рабочей области совсем не похож на подход, который только что был представлен для материализованных представлений. Отсутствует какой-либо эквивалент SQL Access Advisor, который мог бы порекомендовать требующиеся кубы, однако, имеется диспетчер аналитического рабочего пространства (Analytic Workspace Manager - AWM), который является главным административным инструментом графического интерфейса пользователя для построения аналитических рабочих областей и управления ими. В Oracle Database 11g AWM был усилен и теперь предлагается на клиентском компакт-диске.
Рис. 5 служит иллюстрацией того, что AWM значительно упрощает процесс создания аналитической рабочей области и дает возможность любому пользователю - от администратора базы данных до бизнес-аналитика - проектировать модель данных OLAP с измерениями и иерархиями, отображать свои источники данных на измерения и кубы, а затем заполнять их.
Рис. 5. Диспетчер аналитического рабочего пространства
Шаг 1. Анализ для определения контента аналитической рабочей области
Точно также, как в случае создания материализованного представления, еще до формулирования определения аналитической рабочей области надо выполнить анализ того, какую информацию должна содержать эта область. При использовании Oracle Database 11g нужно также рассмотреть надобность применения ее новой опции MV OLAP. Этот вопрос обсуждается в одном из следующих разделов, посвященных доступу к аналитической рабочей области с использованием SQL.
Мы начинаем с изучения данных и типов тех запросов, которые выполняют наши бизнес-пользователи, а также с определения того, какие измерения нам понадобятся. В данном случае - измерения Time, Customers, Products и Channels и физические таблицы, в которых постоянно хранятся эти данные. Затем нужно определить, какие потребуются кубы и какие фактические данные мы должны хранить в этих кубах. В обсуждаемом примере это - итоги продаж и количества проданных продуктов, которые физически хранятся в таблице SALES_FACT, а также данные о стоимости единиц продуктов из таблицы COSTS_FACT.
Как правило, для хранения объектов, необходимых для ответов на запросы бизнес-пользователей, требуется всего одна аналитическая рабочая область (AW). Например, наша область будет состоять из четырех измерений и двух кубов, а в приводимой ниже таблице перечисляется, что именно должно быть создано и источник данных для каждого объекта.
|
Целевойобъект AW |
Типобъекта AW |
Исходная реляционная таблица |
|
PRODUCT |
DIMENSION |
PRODUCTS |
|
CHANNEL |
DIMENSION |
CHANNELS |
|
CUSTOMER |
DIMENSION |
CUSTOMERS_DIM |
|
TIME |
DIMENSION |
TIME_DIM |
|
SALES |
CUBE |
SALES_FACT |
|
COSTS |
CUBE |
COSTS_FACT |
Шаг 2. Создание аналитической рабочей области
На втором шаге необходимо создать аналитическую рабочую область, в которой будут постоянно храниться измерения и куб. Для создания аналитической рабочей области с использованием AWM просто требуется присвоить аналитической рабочей области имя и идентифицировать табличное пространство, где она будет размещена.
Шаг 3. Создание измерений
Реально аналитическая рабочая область состоит из множества различных типов объектов. Мы сосредоточим свое внимание лишь на некоторых из них:
- измерения, включая их иерархии, уровни и атрибуты, и
- кубы
Измерения используются для определения многомерных данных в кубе и должны быть созданы в первую очередь, чтобы их можно было использовать при создании куба. Измерения в аналитической рабочей области могут быть построены либо на базе уровней, точно так же, как "измерение" в реляционном объекте, либо на базе значений (что известно также, как иерархия "родитель-потомок").
Информация, требующаяся для создания измерения в составе аналитической рабочей области, очень похожа на информацию для созданного ранее SQL-измерения. Для создания измерения сначала создается информация об уровнях, а затем иерархии, в которых уровни группируются в правильном порядке сверху донизу. Наконец, любые дополнительные атрибуты для уровней создаются и назначаются на правильных уровнях.
Шаг 4. Заполнение измерений
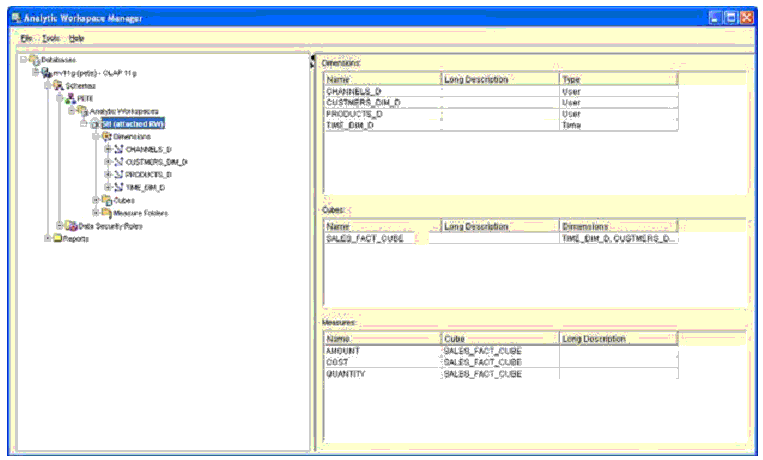
Для загрузки данных в измерение необходимо создать отображения, связывающие столбцы в таблицах, в которых хранятся исходные данные измерения, с атрибутами в измерениях. При использовании AWM это представляет собой простую задачу перетаскивания строк из исходного столбца таблицы в целевой атрибут измерения, как это показано на Рис. 6 для измерения Product. Здесь мы можем видеть столбцы таблицы PRODUCT (например, PROD_DESC), связанные с их атрибутами в измерении Product в аналитической рабочей области, например, длинные и короткие описания на самом нижнем уровне иерархии Product.
Рис. 6. Создание отображений в AWM
На последнем шаге создания измерения его необходимо заполнить, выполняя созданные ранее отображения. Для этого необходимо выбрать опцию Maintain из контекстного меню для измерения (вызывается щелчком по правой кнопке мыши). При этом выполняется процесс, перемещающий данные из исходного объекта в объект измерения в аналитической рабочей области и неявно подтверждающий достоверность данных в измерении. Сравните это с SQL-измерениями, которые являются метаданными о структуре измерения, хранящимися в реляционных таблицах: когда новые данные загружаются в таблицы, используемые для хранения измерений, не проводится их автоматическая проверка, которая могла бы гарантировать, что они соответствуют структуре измерения. Следовательно, SQL-измерения нуждаются в дополнительном шаге проверки достоверности их структуры путем вызова процедуры VALIDATE_DIMENSION из пакета DBMS_DIMENSION.
Шаг 5. Создание кубов
После создания измерений Customer, Channel и Month с такой же непринужденностью могут быть созданы и заполнены кубы. Для этого достаточно щелкнуть правой кнопкой мыши по поддереву Cube в навигационной панели окна и выбрать опцию "Create". Выбираются измерения, определяющие форму куба. В нашем примере, четыре измерения - Time, Products, Customers и Channel - определяют куб SALES, а измерения Time, Product и Channel используются для куба COSTS.
В тот момент, когда создается куб, можно определить множество важных опций, которые определяют структуру хранения кубов, и их выбор может значительно улучшить время, требующееся для построения кубов. Наиболее важными из них являются:
- Порядок и разреженность измерения . Определите порядок измерений для улучшения производительности построения и агрегирования, перечисляя сначала плотные измерения. Плотными измерениями называются такие, в которых значения фактических данных имеются для большей части значений измерения.
- Сжатие . Выберите опцию сжатия, если данные куба очень разрежены, то есть, когда отношение числа значений реальных данных к числу 'пустых' значений является чрезвычайно маленьким. В большинстве случаев эта опция бывает включена.
- Агрегирование . Определите метод агрегирования и операторы для использования. В Oracle Database 11g теперь имеются два метода: новый метод агрегирования по стоимости (Cost Based Aggregation) и предыдущий метод агрегирования по уровням.
- Секционирование . Определите, как должен быть секционирован куб, чтобы повысить производительность загрузки.
Новинкой Oracle Database 11g является метод агрегирования по стоимости, в котором механизм OLAP определяет самые дорогие ячейки для агрегирования и сохраняет агрегированные значения для этих ячеек. Может быть установлено значение от 0 до 100 - чем выше значение, тем больше будет набор предварительно вычисленных и сохраненных данных. Хорошим эмпирическим правилом считается использовать для метода значение 35. Метод агрегирования по уровням по-прежнему может использоваться там, где уровни определены в иерархиях, в которых должны быть физически сохранены агрегирования. Это обеспечивает больший контроль над уровнями, которые будут предварительно вычисляться, и хорошая стратегия состоит в том, чтобы определить агрегаты, которые должны быть вычислены на дополнительных уровнях иерархии.
Секционирование кубов не следует путать с опцией Database Partitioning (секционирование базы данных): для кубов она определяет, как куб должен храниться в составе аналитической рабочей области, как отдельные компоненты. Чтобы секционировать свой куб, выберите уровень в составе одной иерархии одного измерения: тогда для каждого значения данных на этом уровне будет использоваться отдельный раздел. Например, куб SALES использует измерение времени, для которого месяц является самым нижним уровнем, и таким образом определяется, что хорошей стратегией была бы стратегия секционирования куба либо по кварталам, либо на уровне года. Секционирование кубов приводит к выигрышу в производительности загрузки и агрегирования куба. Оно может также повысить производительность запроса, потому что запрос может быть ограничен единственной секцией.
Шаг 6. Создание показателей и отображений куба
Теперь, когда определены измерения куба и его структуры хранения, мы должны определить данные, которые он должен содержать ( показатели ), и отображения на исходные данные.
Определение показателей для куба - это, как фактические данные хранятся в каждой ячейке куба. Отображения куба определяются так же, как это делалось для измерений - путем перетаскивания строк из исходной реляционной таблицы в определение куба.
Шаг 7. Создание материализованных представлений куба в Oracle Database 11g
В Oracle Database 11g вводится возможность создавать материализованные представления куба по кубам аналитической рабочей области и измерениям и при переписывании запросов предоставляется возможность прозрачно переписать их в пользовательские SQL-запросы к базовым исходным таблицам.
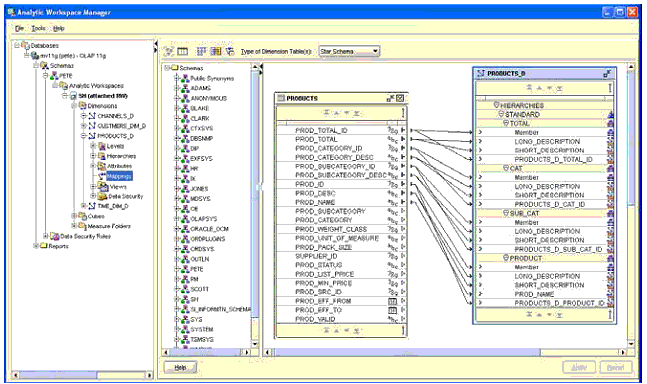
Новыми материализованными представлениями кубов можно управлять через AWM, используя для этого новую закладку Materialized View для куба, как показано на Рис. 8.
Рис. 8. Закладка Materialized View в AWM 11g
Если выбран флажок "Enable Materialized View Refresh of the Cube" (" Активировать обновление материализованного представления куба "), для куба и его измерений в процессе сопровождения куба будут созданы новые материализованные представления. В соответствии с соглашением об именах куба материализованного представления применяется имя куба с префиксом "CB$". Новые материализованные представления куба также способны получить для загрузки данных выигрыш от возможностей обновления, управление которыми также выполняется на этой закладке, и которые будут исследованы более подробно в одном из следующих разделов. Не забудьте выбрать опцию " Enable Query Rewrite " ( "Разрешить переписывание запроса" ), иначе материализованные представления куба нельзя будет использовать при переписывании запросов.
Шаг 8. Наполнение куба
На заключительном шаге определения аналитической рабочей области для Oracle Database 11g необходимо провести операции по обслуживанию и наполнению куба, после чего он станет доступным для запросов. На этой стадии данные загружаются из источника данных для куба, например, в нашем случае из реляционной таблицы SALES_FACT для куба SALES, и присоединяются к его значениям измерения и сохраняются в кубе. Кроме того, именно в этот момент выполняются и сохраняются все определенные для куба агрегирования.
Также для наших кубов и измерений создаются и обновляются организованные по кубам материализованные представления.
Сразу же после того как данные будут загружены, аналитическая рабочая область готова принимать запросы.
Шаг 9. Обновление материализованных представлений куба
Если мы при организации сопровождения куба не проставили соответствующих отметок в окошках закладки Materialized View, то наши новые материализованные представления куба будут построены, но отмечены как unusable (непригодные к использованию). В этом случае, прежде чем использовать представления, мы должны вручную гарантировать актуальность контента их данных и что для них сделана отметка fresh (новые) . Как показано ниже, для этого в SQL*Plus вызывается процедура REFRESH из пакета DBMS_MVIEW, чтобы выполнить полное обновление материализованного представления куба SALES_FACT_CUBE.
EXEC DBMS_MVIEW.REFRESH(list=>"CB$SALES_FACT_CUBE",method="C");
Альтернативно мы можем также использовать процедуру BUILD из нового пакета DBMS_CUBE, которая автоматически обновит любые устаревшие или ставшие непригодными к использованию материализованные представления для измерений аналитической рабочей области перед обновлением материализованного представления куба.
EXEC DBMS_CUBE.BUILD("SALES_FACT_CUBE");
На заключительном шаге перед тем, как материализованные представления куба станут пригодными для использования при переписывании запросов, необходимо собрать для них статистику, используя для этого новый пакет DBMS_AW_STATS:
EXEC DBMS_AW_STATS.ANALYZE("SALES_FACT_CUBE");
ИНСТРУМЕНТАЛЬНЫЕ СРЕДСТВА СОЗДАНИЯ ЗАПРОСОВ
Теперь, когда мы узнали, как следует строить материализованные представления и аналитические рабочие области и их кубы, посмотрим, как делать запросы к ним.
Oracle Database 11g получает существенное преимущество, благодаря использованию материализованных представлений и возможности переписывания запросов для извлечения данных из аналитической рабочей области. Дело в том, что пользователи и инструментальные средства составления отчетов, чтобы использовать в своих интересах все функциональные возможности, могут даже не знать о существовании или структуре аналитической рабочей области, ее кубов или измерений. Инструментальные средства создают SQL-запрос к реляционным таблицам базы данных, а переписывание запросов просто транслирует эти запросы таким образом, чтобы везде, где это возможно, использовались материализованные представления.
Конечно, и в Oracle Database 10g, и в Oracle Database 11g возможно определить реляционные представления кубов, и использовать немного по-другому структурированные запросы SQL, чтобы обратиться к этим представлениям и, следовательно, к AW. Для AWM в среде Oracle Database 10g этот процесс является ручным, но он полностью автоматизирован в Oracle Database 11g. Позже мы рассмотрим оба метода использования SQL.
Если хранилище данных использует для составления отчетов только аналитическую рабочую область, но не реляционные таблицы, использование правильного инструмента для получения доступа к аналитической рабочей области является первостепенным для получения максимальной ценности от ваших данных и инвестиций. Специалисты Oracle предлагают множество мощных графических инструментальных средств и интерфейсов специально для предоставления возможности легко создавать и выполнять запросы к аналитической рабочей области.
ОБНОВЛЕНИЕ ДАННЫХ
Другим важным соображением при попытке принять решение о том, что именно следует использовать - материализованные представления или аналитические рабочие области, является проверка механизмов обслуживания этих объектов, чтобы быть уверенным в том, что они всегда содержат самую свежую информацию. В этом разделе мы рассматриваем имеющиеся механизмы обновления и скорость выполнения обновления.
Обновление материализованных представлений
Одно из преимуществ использования материализованных представлений заключается в том, что в составе Oracle Database имеется множество доступных механизмов обновления материализованных представлений при любых изменениях данных в базовых таблицах:
- Полное обновление путем повторного выполнения определяющего запроса
- Быстрое обновление путем применения к данным инкрементальных изменений
- Обновление путем отслеживания изменений раздела (Partition Change Tracking - PCT)
Когда выполняется полное обновление, материализованное представление восстанавливается полностью посредством повторного запуска определяющего запроса. В зависимости от размера материализованного представления это может потенциально стать дорогостоящей операцией. Отслеживая изменения в базовых данных с использованием журналов материализованного представления, быстрое обновление дает возможность применить к материализованному представлению только сделанные изменения. Кроме того, быстрое обновление может быть выполнено путем прозрачного обнаружения ситуаций, когда происходят изменения данных в разделах базовых таблиц. А затем для обновления материализованного представления потребуется повторно вычислить только контент для изменившихся разделов. Точно так же во время выполнения операций загрузки в прямом режиме, например, с помощью SQL*Loader, база данных автоматически отслеживает новые данные, загруженные на уровне блоков. При использовании этих двух методик для быстрого обновления не требуются журналы материализованных представлений. Однако следует отметить, что не для всех материализованных представлений имеется возможность быстрого обновления, что может быть задано при использовании пакетированной процедуры DBMS_MVIEW.EXPLAIN_MVIEW.
Материализованные представления обновляются или по требованию (по запросу), или при выполнении операции commit. Ниже показано быстрое обновление по требованию с использованием пакета DBMS_MVIEW.
DBMS_MVIEW.REFRESH( list => "state_sales_mv, channels_count_mv", method => "F");
Обновление кубов аналитической рабочей области
Введение материализованных представлений кубов в Oracle Database 11g означает, что механизмы обновления, которые ранее использовали материализованные представления, теперь являются доступными и для аналитических рабочих областей. Наиболее значительные из них - это возможности использовать журналы материализованного представления и отслеживание изменений в разделах для выполнения быстрого обновления со значительным повышением производительности. В Oracle Database 11g введен новый механизм обновления, получивший название FAST_SOLVE, который доступен только для материализованных представлений кубов. Этот метод инкрементально повторно агрегирует кубы, обнаруживая изменения данных и не используя журналы материализованных представлений. Ранее в Oracle Database 10g не было возможности быстро обновить только измененные данные, и определение измененных данных в исходной таблице должно было быть встроено в отображения. Например, при использовании представления, базирующегося на исходной таблице, как на источнике данных, а не самой таблицы, определение представления может использовать для определения новых или обновленных строк фразу WHERE.
Использование секционированного куба значительно улучшает загрузку данных и время обновления по сравнению с несекционированным кубом, потому что дает базе данных возможность автоматически использовать процессы параллельной загрузки.
ДРУГИЕ ПОДЛЕЖАЩИЕ УЧЕТУ ПРОБЛЕМЫ
Теперь, когда имеет место сближение функциональных возможностей материализованных представлений и аналитических рабочих областей для поддержки производительности запросов, какие другие факторы следует учесть при определении, какой их этих подходов является правильным для вашей организации? Приведенная ниже таблица иллюстрирует некоторые важные соображения, которые могут повлиять на решение.
|
Проблема |
Материализованные представления |
Аналитические рабочие области | |
|
Применение версии EE (Enterprise Edition) |
Да |
Да | |
|
Требуется опция OLAP |
N/A (неприменимо) |
Да | |
|
Генерация отчета при отсутствии данных в AW или MV |
Да |
Нет (10g) | |
|
Поддержка производительности соединений |
Да |
Да | |
|
Свертывание агрегатов |
Да |
Да | |
|
Полнота и разреженность данных |
Нет |
Да | |
|
Специальные аналитические функции |
Нет |
Да | |
|
Мастера и инструментальные средства для рекомендаций |
Да |
Нет (10g) | |
|
Быстрое обновление данных |
Да |
Нет (10g) |
|
|
Поддержка различных типов иерархии |
Да (частично) |
Да |
|
|
Использование SQL |
Да |
Да |
|
|
Прогнозирующие модели |
Нет |
Да |
|
|
Накладные расходы при запросах |
Никаких |
Да (10g) |
|
Наличие атрибутов при запросе
Что произойдет, если в запросе упоминается атрибут, который не присутствует в материализованном представлении или аналитической рабочей области? Реляционный запрос возвратит результаты, потому что механизм переписывания запросов, известный как обратное соединение (join back) может автоматически присоединить существующее материализованное представление назад к базовой таблице, чтобы обратиться к недостающему атрибуту данных. Даже если не будет доступно никакое жизнеспособное материализованное представление, оптимизатор позволит запросу возвратить результаты, работая с базовыми таблицами, где присутствуют все атрибуты и фактические данные.
В Oracle Database 11g использование переписывания запросов для обращения к аналитической рабочей области означает, что запросы могут теперь ориентироваться на механизм переписывания обратного соединения, так что, даже если атрибуты отсутствуют в аналитической рабочей области, их по-прежнему можно получить из базовых таблиц. Ранее, в Oracle Database 10g переписывание запросов не было доступно при обращении к аналитической рабочей области, и если атрибут не был загружен в измерение аналитической рабочей области, то не было даже возможности создать запрос, и таким образом, не могли быть возвращены никакие результаты. Чтобы разрешить эту проблему, необходимо перестроить измерение, чтобы добавить в него информацию недостающего атрибута.
Полнота и разреженность данных
В реляционных таблицах записи присутствуют только для существующих данных, тогда как в кубах аналитической рабочей области используются пустые значения там, где не существует никаких данных. В кубе хранятся значения реальных данных, и поскольку пустые значения легко адресуемы и доступны для запроса, в реальности они не сохраняются в кубе. Например, можно легко обратиться в запросе к значениям данных за прошлый месяц, даже если в этом месяце не имелось никаких данных, хотя пустые значение не сохраняются. Это выдвигает на первый план очень важную особенность кубов аналитической рабочей области, в соответствии с которой они работают, как будто для полноты спектра значений их измерений они полностью заполнены как фактическими, так и отсутствующими данными. Это может обернуться очень важной выгодой, потому что делает определяющие вычисления более простыми, поскольку можно предположить, что в кубе присутствуют все точки данных. Например, даже если нет никаких сведений ни о наличии, ни о складировании товара (Tents) в феврале 2002 года (Feb2002), может быть определена следующая формула:
nvl(sales('Feb2002','Tents'),0) - nvl(sales('Jan2002', 'Tents'), 0)
Для аналитических рабочих областей сделаны существенные усовершенствования загрузки данных, производительности агрегирования и производительности запросов, являющиеся результатом эффективной обработки разреженности, благодаря применению в Oracle Database 11g лучшей в отрасли технологии сжатия. Если по вашим требованиям к составлению отчетов должны быть обработаны строки с пустыми значениями, необходимо серьезно рассмотреть вопрос об использовании аналитических рабочих областей. Дело в том, что они могут справиться с этой информацией по умолчанию, вместо того чтобы писать более сложные SQL-предложения, генерирующие тот же самый результат.
Поддержка производительности операций соединения
Благодаря предварительному вычислению результатов соединения, материализованные представления превосходно зарекомендовали себя в улучшении производительности реляционных соединений между любыми реляционными таблицами базы данных. Напротив, в одиночном кубе аналитической рабочей области предварительно вычисляется и сохраняется только соединение между данными показателей этих кубов и их измерениями.
Несмотря на то, что аналитические рабочие области не соединяют предварительно кубы вместе, из-за структуры их внутренней памяти они очень эффективны при выполнении во время запроса операций типа соединения "на лету". Кроме того, возможность определения этого соединения значительно более проста и менее сложна для аналитической рабочей области, чем при ее реляционном определении. Мы более подробно рассмотрим эту операцию для аналитической рабочей области в разделе "Написание SQL-запросов к кубам аналитической рабочей области".
Свертывание агрегатов
Требуется время и ресурсы для поддержания таких агрегатов как, например, sum and average (сумма и среднее). Поэтому становится выгодно минимизировать число агрегатов, которые необходимо поддерживать. Если имеются агрегаты ежемесячного уровня, полезно иметь возможность использовать и свертывать их во время запроса до ежеквартального или ежегодного уровня вместо того, чтобы обеспечить явную поддержку ежеквартальных или ежегодных итогов непосредственно во время загрузки.
Свертывание агрегатов, как в аналитических рабочих областях, так и в том виде, как оно используется при переписывании запросов к материализованным представлениям, является одинаково мощным и эффективным в использовании метаданных в их определениях измерения для выполнения этой операции свертки. В обоих подходах для ответа на пользовательские запросы, требующие агрегатов на более высоких уровнях в иерархии измерения, могут использоваться предварительно вычисленные агрегаты нижних уровней.
Функции непосредственного (Adhoc) анализа данных
Многомерный механизм вычисления в Oracle OLAP, который работает в среде данных куба, предлагает очень богатый набор аналитических функциональных возможностей. Кроме того, из-за специализированных структур хранения кубов, добавление нового выведенного значения данных, известного как calculated measure (расчетный показатель), не требует перестройки куба. Чтобы достичь той же самой производительности при реляционном подходе, может потребоваться создание нового материализованного представления, на построение которого потребуется время, и тем самым будет отсрочено генерирование отчета и увеличено время, требующееся для поддержания материализованного представления. Наоборот, поскольку в аналитической рабочей области аналитическая функция уже присутствует, фактически нет никакого сокращения производительности по сравнению с доступом к самим значениям базовых данных куба.
Визарды (Wizards) и инструментальные средства для создания рекомендаций
Во вводном разделе мы видели, что и материализованные представления, и аналитические рабочие области требуют изрядного количества работы по анализу и установке, прежде чем их можно будет использовать. Поэтому всегда приветствуются любые инструментальные средства для облегчения этого процесса, особенно для новых пользователей этих функциональных возможностей. Как показано на Рис.4, хорошую поддержку материализованных представлений обеспечивает инструментарий SQL Access Advisor, который принимает набор SQL-операторов, рекомендует материализованные представления и предлагает сценарий для реализации собственных рекомендаций. Кроме того, предлагаются следующие PL/SQL-процедуры для анализа многих проблем с материализованными представлениями и переписыванием запросов:
- Процедура EXPLAIN_MVIEW в пакете DBMS_MVIEW для отчета о таких функциональных возможностях материализованного представления, как возможно ли в действительности быстрое обновление, и какие типы переписывания запросов поддерживаются.
- Процедура TUNE_MVIEW в пакете DBMS_ADVISOR для помощи в оптимизации материализованного представления, чтобы сделать его быстро обновляемым, если это возможно, и максимизировать возможности переписывания запросов.
- Процедура EXPLAIN_REWRITE в пакете DBMS_MVIEW, которая сообщает, почему при переписывании запросов использовалось (или не использовалось) материализованное представление.
Для аналитических рабочих областей отсутствует подобный советник (advisor ), который может рекомендовать правильные измерения и кубы, необходимые для поддержки пользовательских запросов. Однако существует множество советников для помощи в процессе разработки при создании аналитической рабочей области, которые позволяют убедиться, что кубы построены правильно.
Советник по разреженности
Советник по разреженности в AWM 10.2.0.3 проанализирует измерения для куба, чтобы определить, какие из них являются разреженными, а какие - плотными, чтобы рекомендовать порядок их использования при конструировании и сжатии куба и определить, действительно ли требуется секционирование куба. Правильно определение этого порядка может оказать существенное воздействие на время, которое требуется для загрузки и задания запроса к кубу.
Советники в AWM 11g
В Oracle Database 11g советник по разреженности был заменен тремя новыми:
- Cube Partitioning Advisor (Советник по секционированию куба) дает рекомендации по секционированию куба на основании секционирования исходной таблицы и разреженности данных в его измерениях.
- Cube Storage Advisor (Советник по хранению куба) анализирует существующий куб и его измерения и дает рекомендации как можно оптимально перестроить куб. Например, советник исследует, какие измерения куба являются плотными или разреженными, чтобы определить их правильный порядок хранения в кубе и должно ли в действительности использоваться сжатие.
- Relational Schema Advisor (Советник реляционной схемы) генерирует SQL-сценарий для создания всех необходимых объектов базы данных и ограничений, требующихся для переписывания запросов, чтобы они работали с материализованными представлениями куба.
Расширенная отчетность с использованием измерений
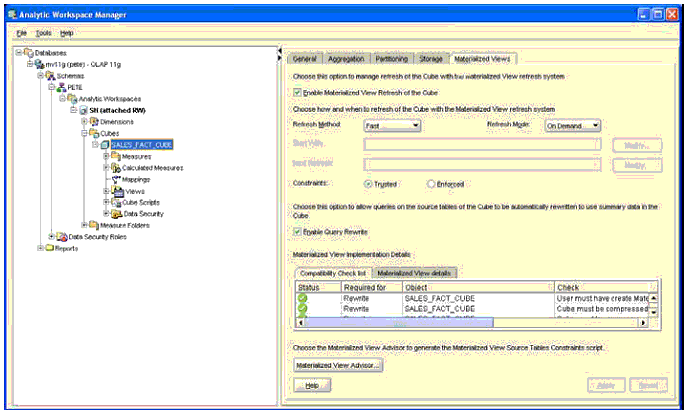
Поддержка различных типов иерархий в данных измерений и разрешение большей гибкости в определении иерархии может сделать возможным моделирование более широкого разнообразия бизнес-сценариев. Инструмент SQL Dimension, который используется материализованными представлениями, поддерживает только тип измерения на базе уровней, тогда как аналитические рабочие области могут использовать оба типа измерений: на базе значений и на базе уровней как показано на рис. 8.
Рис. 8. Типы измерений и иерархий
В составе измерений аналитической рабочей области могут также быть реализованы так называемые ragged (неравные ) иерархии, дающие возможность использовать различное число уровней, когда обход иерархии от корневого до самого нижнего уровня производится по различным путям. Использование неравных иерархий увеличивает гибкость при моделировании данных и может увеличить количество бизнес-сценариев, которые может моделировать измерение.
Прогнозирующие модели
Часто для предсказания будущих тенденций требуется анализ статистических данных. Это именно та область, в которой аналитические рабочие области чувствуют себя очень уверенно, потому что этого нельзя легко добиться реляционными методами.
В Oracle Database 10g предсказывающие (прогнозирующие) модели реализуются путем использования так называемых Calculation Plans (планов вычисления), определяемых с помощью визарда ( wizard ). Визард постепенно проводит пользователя по всему процессу определения прогнозирующей модели, которую предполагается использовать, и показывает, как работает модель для каждого измерения куба. Пользователю предлагается выбор из множества различных моделей. Может быть выбран и автоматический метод, в котором будет проведен анализ статистических данных, позволяющий принять решение о том, какой из методов обеспечивает наилучшее приближение при моделировании и, значит, должен быть использован. После определения плана вычислений его необходимо выполнить, чтобы сгенерировать данные прогноза. Определение функциональных возможностей прогноза станет доступно в будущей версии AWM 11g, но тем не менее оно может быть с легкостью выполнено и в текущей версии, если использовать OLAP DML - язык программирования для аналитической рабочей области.
Для сравнения, материализованные представления предварительно вычисляют соединения и агрегирования, используя фактические статистические данные, присутствующие в таблицах, и не имеют функциональной возможности для предсказания трендов. Реляционно это может быть выполнено с использованием фразы SQL Model, которая была введена в Oracle Database 10g, однако нет никаких визардов для определения и управления прогнозами таким же образом, как это делает AWM для аналитических рабочих областей.
Накладные расходы для запросов
Накладные расходы на присоединение аналитической рабочей области были значительно сокращены. В Oracle Database 11g они являются весьма незначительными. Однако в Oracle Database 10g накладные расходы составляли приблизительно 20 секунд при первом присоединении аналитической рабочей области к сеансу, т.е. когда был выполнен первый реляционный запрос к аналитической рабочей области. Кроме того, имеются накладные расходы, являющиеся частью первых операций агрегирования, поскольку аналитическая рабочая область кэширует результаты агрегирования. При последующих запросах к аналитической рабочей области эти накладные расходы не имеют места.
При выполнении реляционного запроса к таблицам и переписывании запросов для использования материализованных представлений отсутствуют какие-либо эквивалентные накладные расходы.
РЕЛЯЦИОННЫЙ ДОСТУП К АНАЛИТИЧЕСКОЙ РАБОЧЕЙ ОБЛАСТИ
В Oracle Database 11g доступ из SQL к аналитической рабочей области и кубам может быть выполнен двумя способами:
- путем использования интерфейса, известного как CUBE_TABLE
- с помощью переписывания запросов.
Использование CUBE_TABLE для SQL-доступа к аналитической рабочей области
Использование SQL для получения доступа к кубам и измерениям является существенной особенностью Oracle OLAP, потому что при этом становится возможным применение инструментальных средств составления отчетов, которые генерируют только SQL, при одновременном использовании всех мощных возможностей аналитической рабочей области. В Oracle Database 11g это достигается при помощи функции CUBE_TABLE, которая извлекает многомерные данные из куба в аналитической рабочей области и представляет их для реляционного механизма SQL в форме двумерных таблиц, то есть, в виде набора строк и столбцов. Это обеспечивает отображение между кубом в аналитической рабочей области и строками и столбцами, которые видит SQL.
CUBE_TABLE параметризуется именем измерения аналитической рабочей области или куба. Для измерения CUBE_TABLE возвращает данные измерения, как таблицу записей для всех членов измерения со столбцами для каждого из уровней иерархии. Параметр измерения может также называть определенную иерархию, что приводит к тому, что для родительских данных для уровней в иерархии становятся доступными дополнительные столбцы, обеспечивающие дополнительную гибкость при задании запросов и навигации по иерархии. Фраза иерархии (hierarchy) также ограничивает строки измерения только теми строками, которые входят в состав иерархии. Например, если определена иерархия Fiscal, вы не увидите в календарные кварталы. Однако, если иерархия не определена, то вы получите все члены измерения с учетом всех иерархий. Диспетчер AWM автоматически создает обычные представления, используя функцию CUBE_TABLE для каждого измерения аналитической рабочей области и куба, и к этим кубам можно делать SQL-запросы для обращения к объектам аналитической рабочей области. Есть два типа автоматически создаваемых представлений:
1. Dimension Views (представления измерения)
- Генеральное представление измерения именуется по имени измерения и суффикса "_VIEW".
- Представление иерархического измерения существует для каждой иерархии в измерении, оно имеет суффикс "<имя иерархии>_VIEW". Это представление содержит дополнительные столбцы "родительские-порожденные", чтобы обеспечить навигацию вверх и вниз по иерархии.
- Cube Views (представления кубов) содержат показатели и внешние ключи для измерений кубов для присоединения к представлениям измерения и получают имена по имени куба и суффикса "_VIEW"
В Oracle Database 11g базирующееся на CUBE_TABLE обычное представление для каждого куба и каждого измерения создается автоматически с помощью AWM. Запросы к ним делаются путем объединения их вместе. Во многом это очень похоже, как если бы они образовывали реляционную схему типа звезды, то есть, как будто делается запрос к фактографической таблице и ее таблицам измерений. Это означает, что для получения доступа к этим представлениям и аналитической рабочей области может быть использован обычный SQL-запрос. Приведенный ниже пример запроса использует эти представления для обращения к аналитической рабочей области, чтобы ответить на запрос:
SELECT t.long_description time, f.amount amount
FROM time_dim_view t, products_dim_view p, customers_dim_view cu,
channels_dim_view ch, sales_fact_cube_view f
WHERE t.long_description IN ('2005', '2006')
AND t.level_name = 'YEAR' AND p.level_name = 'TOTAL'
AND cu.level_name = 'TOTAL' AND ch.level_name = 'TOTAL'
AND t.dim_key = f.time_dim AND p.dim_key = f.products_dim
AND cu.dim_key = f.customers_dim_d AND ch.dim_key = f.channels_dim;
При написании SQL-запроса к представлениям CUBE_TABLE важно включить фразы WHERE, чтобы полностью квалифицировать данные, требующиеся для каждого измерения. Это нужно, чтобы ограничить как число пластин куба, к которым делается запрос, так и объем данных, к которым производится обращение и которые затем возвращаются назад в SQL-оператор. Поскольку куб работает, как будто он полностью заполнен, то есть, в нем присутствуют все пустые значения данных, из-за его разреженности это может привести к очень большому объему значений данных, возвращаемых из куба через представление, если не ввести ограничение. Выгода заключается в том, что куб содержит все уровни агрегирования и очень просто написать запросы, которые возвращают данные из различных уровней агрегирования. Также отметим, что никакая фраза GROUP BY и никакие операторы агрегирования (например, SUM) не требуются. Дело в том, что куб представляет результаты, как уже агрегированные, и поэтому:
- Вы не хотите снова проводить агрегирование в SQL
- Вы хотите использовать бизнес-правила в агрегированиях как реализованные в составе аналитической рабочей области, например, агрегирование остатка на счете или общего количества персонала (headcount) в зависимости от времени проходит не так, как агрегирование по продуктам
- Вычисляемые показатели уже работают правильно в кубе, например, Year To Date (на данный год) и YTP Prior Year (YTP за предшествующий год), и не требуют добавочных вычислений.
Переписывание запросов для организованных по кубам материализованных представлений
Для задания запросов к реляционным таблицам или к аналитической рабочей области с помощью представления CUBE_TABLE требуется, чтобы наши разработчики отчетов и квалифицированные пользователи приняли решение, к какому типу данных они желают получить доступ. Так не было бы проще, если бы они могли всегда делать запросы только к одному типу данных и позволить базе данных решать, как следует обработать этот запрос - реляционным или многомерным образом?
Именно это мы можем теперь проделать в Oracle Database 11g, применяя возможности переписывания запросов для использования новых организованных по кубам материализованных представлений. Мы используем SQL, чтобы делать запросы к реляционным базовым таблицам, а оптимизатор прозрачно транслирует SQL, чтобы тот обращался или к материализованным представлениям таблицы, или к материализованным представлениям куба (и, следовательно, к кубам аналитической рабочей области и измерениям), в зависимости от того, какой из этих запросов обеспечивает лучшую производительность. Это позволяет легко сделать все преимущества аналитической рабочей области доступными для любого продукта, используя обычный SQL.
Аналитические рабочие области также очень хорошо зарекомендовали себя при объединении кубов. Хороший многомерный дизайн приводит к ситуации, когда данные из различных размерностей находятся в различных кубах. Когда необходимо объединить два куба вместе и образовать результирующий куб, доступный для SQL-запросов, лучше выполнять такую операцию в аналитической рабочей области, а не использовать для выполнения объединения SQL. Мы можем очень легко выполнить такое соединение в аналитической рабочей области, используя AWM для определения вычисляемых показателей.
Рассмотрим, например, соединение 3-мерных данных COSTS с измерениями (TIME, PRODUCT, CHANNEL) с 4-мерными данными SALES (TIME, PRODUCT, CHANNEL, CUSTOMERS). Для реляционного определения соединения между реляционными таблицами SALES_FACT и COSTS_FACT требуется, по крайней мере, соединение трех общих столбцов измерений и выполнение агрегирования, принимая при этом меры, чтобы не "удвоить счет" из-за недостающего измерения CUSTOMERS. Для того чтобы написать SQL для этого соединения, требуется детализированное знание структуры таблиц фактов и измерений и их первичных ключей.
Напротив, в аналитической рабочей области соединение может быть реализовано с использованием AWM путем простого шага по определению нового вычисляемого показателя для куба SALES, который ссылается на необходимый показатель в кубе COSTS. Новый столбец с вычисляемым показателем в кубе SALES затем становится доступным для SQL через интерфейс CUBE_TABLE, который мы уже обсудили. В нашем запросе SQL не должно встречаться никаких фраз WHERE для выполнения соединения, потому что мы обращаемся только к кубу SALES, который содержит вычисляемый показатель как ссылку на показатель в кубе COSTS. Даже притом, что COSTS - это 3-мерный куб, а SALES - 4-мерный куб, аналитическая рабочая область может разумно и автоматически учесть недостающее измерение CUSTOMERS, чтобы выполнить эту операцию соединения для кубов различной размерности. Поскольку это вычисляемый показатель, на построение не потребуется никакого другого времени, кроме непосредственного определения вычисляемого показателя: AWM автоматически перестраивает свои представления, чтобы в них был включен новый столбец.
ЗАКЛЮЧЕНИЕ
Любой из подходов является "лучшим в своем классе" в рамках своих полномочий, или же оба могут быть использованы в гибридном решении, чтобы обеспечить все лучшее из обоих подходов.
Размер баз данных быстро увеличивается, и все большее число областей бизнеса начинает понимать, насколько ценно всегда быть в состоянии быстро проанализировать данные, что приводит к возрастанию числа запросов к базе данных. Поэтому немедленное предоставление результатов запроса становится основным деловым требованием.
Оба подхода, как использующий материализованные представления, так и использующий аналитические рабочие области, предлагают мощные возможности для достижения этой цели. А с пришедшими в Oracle Database 11g новыми материализованными представлениями кубов и переписыванием запросов использование всех этих мощных возможностей становится легче, чем когда-либо ранее.
Управление итогами (Summary Management) повышает легкость развертывания и обслуживания материализованных представлений, их можно быстро загружать и обновлять, а благодаря переписыванию запросов их использование может быть сделано полностью прозрачным для конечных пользователей. Однако наличие среды сложной отчетности может привести к большому числу требуемых материализованных представлений, что, в свою очередь, может привести к необходимости большого объема администрирования. Для компенсации этого одним из преимуществ использования материализованных представлений является наличие советников (advisors) для помощи в их (материализованных представлений) построении и совершенствовании, которые могут быть неоценимыми, если в вашей организации недостаточен уровень компетентности сотрудников. Материализованные представления также сильно выигрывают, благодаря наличию механизмов быстрого обновления.
Имеется существенное различие между аналитическими рабочими областями в Oracle Database 10g и 11g. Ранее реляционный доступ был ограничен, и его было более трудно реализовать, но теперь в Oracle Database 11g реляционный доступ осуществляется через автоматически создаваемые представления базы данных и материализованные представления. Аналитические рабочие области могут теперь использовать функциональные возможности быстрого обновления материализованных представлений и переписывания запросов и обеспечивать быстрый доступ к сложным аналитическим возможностям. К ним можно также легко обратиться через реляционный SQL, чтобы сделать их возможности быстрой аналитики доступными более широкому спектру инструментальных средств и пользователей.
В этом документе сравниваются два подхода, и мы можем видеть, что до появления Oracle Database 11g с материализованными представлениями было значительно проще справиться, и для них имелись советники, которые могли порекомендовать для реализации лучший набор материализованных представлений.
С введением Oracle Database 11g уже аналитические рабочие области предлагают многие из возможностей управляемости материализованных представлений, хотя они все еще испытывают недостаток в сложных советниках, имеющихся для управления итогами.
В заключение: оба подхода предлагают мощные возможности для повышения производительности запросов к базе данных, и любой из подходов может удовлетворить ваши требования к составлению отчетов, но один из них может оказаться предпочтительнее, в зависимости от типа выполняемого анализа.