Оглавление
- Резюме
- Введение
- Среда тестирования
- Сортировка в оперативной памяти
- Хэш-агрегирование
- Секционированные таблицы
- Создание контрольных точек для объектов
- Встроенные SQL-функции Apply для "добычи данных"
- Усовершенствования в алгоритме метода опорных векторов
- Заключение
РЕЗЮМЕ
Сегодня в качестве основной опоры для хранилищ данных требуются системы управления базами данных высокой производительности. В Oracle Database 10g R2 предлагаются новые опции и усовершенствования, обеспечивающие существенное повышение производительности для удовлетворения растущих требований, возникающих при работе с хранилищами данных. Повышение производительности имеет место автоматически после проведения обновления до уровня Oracle Database 10g R2 без каких-либо изменений в коде приложений или дополнительных расходов на развертывание. В предлагаемом техническом документе описываются эти новые опции и усовершенствования, а также демонстрируется обеспечиваемое ими повышение показателей производительности.
ВВЕДЕНИЕ
Каждый день организации накапливают миллиарды байтов данных о своем бизнесе, миллионы индивидуальных фактов о своих заказчиках, операциях, продуктах и служащих. Самый большой успех достанется на долю тех организаций, которые смогут эффективно использовать свои данные для улучшения ежедневного процесса операционного управления, строить сильные отношения с акционерами и, что наиболее важно, удовлетворять требования своих заказчиков. Хранилища данных и системы анализа бизнес-информации стали краеугольным камнем для многих успешных предприятий.
Так как компании ищут способ добиться конкурентного преимущества, стремясь получить все больше от своих систем анализа бизнес-информации, их хранилища данных постоянно увеличиваются в размерах. Взрывной рост объемов хранилищ данных и их увеличивающаяся сложность до предела напрягают функциональные возможности систем управления базами данных. Упор делается на то, чтобы обеспечить более быстрое получение более хорошей информации и быстро реагировать на изменение деловых потребностей.
Версия Oracle Database 10g R2 принимает вызов, предлагая высокопроизводительную систему для соответствия сегодняшним быстро растущим требованиям, связанным с работой с хранилищами данных. Появившиеся в этом выпуске новые возможности и усовершенствования позволяют достичь повышения производственных показателей при работе с хранилищами данных и системами анализа бизнес-информации. После проведения обновления до Oracle Database 10g R2 эти новые возможности и усовершенствования органично интегрируются с существующими приложениями для хранилищ данных без какой-либо новой реализации или вмешательства со стороны команды, занимающейся обслуживанием хранилищ данных.
В предлагаемой статье описываются все эти новые возможности и усовершенствования. Повышение производственных показателей демонстрируется посредством конкретного сравнения производительности запросов в средах Oracle Database 10g R1 и Oracle Database 10g R2. В последующих разделах сначала описывается среда тестирования, после чего следует описание тестов, характеризующих предлагаемое новыми опциями повышение производственных показателей, включая новый алгоритм сортировки в оперативной памяти, опцию хэш-агрегирования, опцию создания контрольных точек для объектов и усовершенствования для секционированных таблиц. Затем будет приведено объяснение двух опций "добычи данных" и продемонстрированы повышения производительности. И, наконец, следует заключение статьи.
СРЕДА ТЕСТИРОВАНИЯ
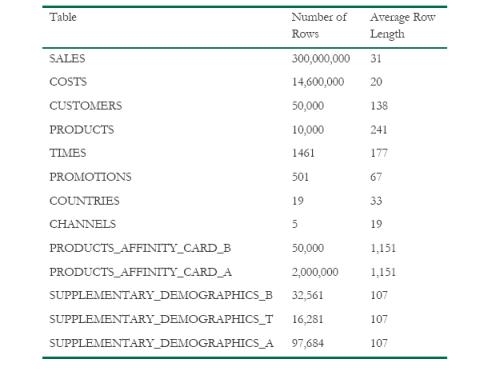
Для проведения приведенных в этой Белой книге тестов использовалась система с двумя процессорами Intel Xeon с частотой 2.8 ГГц, выполненными по технологии "сверхмногопотоковости" (Hyper-Threading). Базы данных были созданы в файловой системе OCFS (Oracle Cluster File System) и разнесены по 10 дискам единого массива дисков. Схема базы данных, изображенная на Рис. 1, включает схему предыстории продаж (Sales History) из набора стандартных примеров Oracle (Oracle Sample Schema) и некоторое число других независимых таблиц, которые были добавлены как результат "добычи данных" (data mining).
Таблица SALES заполнена коммерческой информацией за 7 лет (данные с января 1995 до декабря 2001 года), объем которой составляет около 10 Гбайт. И таблица SALES, и таблица COSTS компрессированы и секционированы по диапазону ключей (столбец time_id), а общее число разделов равно 20. В приводимой ниже таблице приводится статистика числа строк и средней длины строки для каждой таблицы.
В каждой из последующих секций рассматривается какая-либо из новых возможностей Oracle Database 10g R2 с демонстрацией тестов на заявленной схеме.
Рис1. Схема базы данных
СОРТИРОВКА В ОПЕРАТИВНОЙ ПАМЯТИ
В Oracle Database 10g R2 вводится новый алгоритм сортировки в оперативной памяти, который сортирует быстрее и имеет лучшую локальность (locality) системы памяти, чем существующий алгоритм сортировки для Oracle Database 10g R1.
Новый алгоритм сортировки в оперативной памяти повышает производительность широкого спектра запросов. Он используется в следующих случаях:
- запросы с фразой "order-by"
- запросы, использующие "соединение методом сортировки-слияния" (sort merge join)
- запросы, использующие "внешнее соединение разделов" (partition outer join)
- создание индекса
Новый алгоритм сортировки в оперативной памяти не поддерживает столбцы, для которых ведется сборка мусора (garbage collection), имеются сегментированные потоки или которые имеют размер более 30 000 байт, даже если они не являются ключевыми столбцами. Из ключевых столбцов новая сортировка в оперативной памяти не поддерживает столбцы, требующие семантических сравнений, типа логических rowid и времени с часовым поясом.
При некоторых обстоятельствах производительность старого алгоритма сортировки ухудшается по мере увеличения размера доступной памяти и достигает некоторого порога. Новый алгоритм сортировки в оперативной памяти разрешает эту проблему, благодаря хорошей локальности системы памяти.
В первой группе тестов показано повышение производительности для нескольких типичных запросов, для которых оказывается полезна новая сортировка в оперативной памяти. При выполнении этих тестов параметр workarea_size_policy был установлен на AUTO. Во второй группе тестов демонстрируется локальность системы памяти нового алгоритма сортировки в оперативной памяти путем установки параметра workarea_size_policy на MANUAL. Тесты выполнялись с изменяющимися значениями параметра sort_area_size, причем каждый раз измерялось общее затраченное время для одного запроса.
Для оценки производительности использовались следующие запросы.
create index sales_cust_id on sales (cust_id) parallel
compute statistics nologging;
Мы обозначим этот запрос как " INDEX ".
Для оператора select был рассмотрен следующий запрос:
select prod_id, time_id, unit_cost from costs order by unit_cost;
Чтобы избежать вывода на экран 14 600 000 строк, фактически выполнялся запрос:
select count(*) from (select /*+ no_merge */ prod_id,
time_id, unit_cost from costs order by unit_cost);
Подсказка NO_MERGE в тексте запроса не позволяет Oracle слить встроенное представление с потенциально размещенным в другом объекте SQL-оператором, так что фактически выполняется фраза "order_by unit_cost".
Мы обозначим этот запрос как " SELECT ".
Каждый из вышеупомянутых запросов выполнялся как в Oracle Database 10 g R1, так и вOracle Database 10 g R2, а статистики выполнения их сравнивались. План выполнения в Oracle Database 10 g R2 является тем же самым, что и в Oracle Database 10 g R1, хотя лежащие в их основе реализации сортировки в оперативной памяти будут разными.
План выполнения для запроса INDEX выглядит следующим образом:
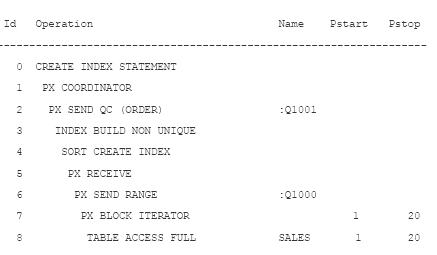
В следующей таблице приводится сравнение производительности запроса INDEX :
|
Общее |
Процент использования ЦП | |
|
Oracle Databasel0g R1 |
1432 |
88.54 |
Благодаря новому алгоритму сортировки, запрос INDEX в Oracle Database 10 g R2 выполняется вдвое быстрее, чем в Oracle Database 10 g R1. Более того, процент занятости центрального процессора при выполнении запроса INDEX в Oracle Database 10 g R2 (55.98 %) намного меньше, чем процент занятости центрального процессора при выполнении запроса INDEX в Oracle Database 10 g R1 (88.54 %), благодаря чему появляется возможность выполнять больше параллельных запросов.
План выполнения для запроса SELECT имеет следующий вид:
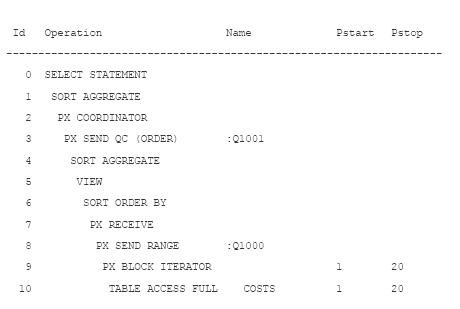
В следующей ниже таблице приводится сравнение производительности запросов SELECT .
|
Общее |
Процент использования ЦП | |
|
Oracle Databasel0g R1 |
19 |
83.21 |
Запрос SELECT с фразой order-by выполняется почти вдвое (на 47%) быстрее и потребляет меньше процессорного времени, чем эквивалентный запрос вOracle Database 10 g R1.
В отличие от алгоритма сортировки вOracle Database 10 g R1 новый алгоритм сортировки вOracle Database 10 g R2 имеет хорошую локальность системы памяти. Он генерирует меньше "непопаданий" в кэш и TLB, чем алгоритм сортировки в Oracle Database 10 g R1. По мере роста размера доступной для сортировки памяти производительность запросов с использованием нового алгоритма сортировки повышается.
Используя в качестве примера запрос INDEX , мы изменяли параметр sort_area_size и сравнивали производительность запроса в средах Oracle Database 10 g R1 иOracle Database 10 g R2. В следующей ниже таблице для запроса INDEX собраны данные об общем затраченном времени в секундах для различных значений параметра sort_area_size .
|
SORT_AREA_SIZE |
1 Мбайт |
10 Мбайт |
100 Мбайт |
|
Oracle Database 10g R1 |
1318 |
1389 |
1653 |
|
Oracle Database 10g R2 |
911 |
804 |
715 |
Создание индекса ни в одном из вышеупомянутых случаев не проходило полностью в памяти. Однако из-за хорошей локальности в оперативной памяти нового алгоритма сортировки скорость запроса INDEX вOracle Database 10 g R2 увеличивается по сравнению с Oracle Database 10 g R1 от 44% до 131% при увеличении значения sort_area_size с 1 до 100 Мбайт.
В заключение повторим: новый алгоритм сортировки в оперативной памяти, введенный вOracle Database 10 g R2, значительно повышает производительность запроса в единицах общего затраченного времени, потребляя меньше времени центрального процессора и позволяя выполнять большее число параллельных запросов. Из-за лучшей локальности системы памяти, обеспечиваемой новым алгоритмом сортировки в оперативной памяти, производительность запросов с использованием этого алгоритма повышается по мере роста объема доступной памяти.
ХЭШ-АГРЕГИРОВАНИЕ
Агрегирование данных - это часто встречающаяся в средах OLAP и хранилищ данных операция. Данные либо агрегируются "на лету", либо вычисляются предварительно и сохраняются как материализованные представления. В любом случае, агрегирование данных сводит вместе записи с одинаковыми значениями столбцов group-by (столбцы, по которым производится группирование) и агрегирует их.
При агрегировании данных в Oracle Database 10 g R1 используется подход на основе сортировок. В Oracle Database 10 g R2 применяется метод хэширования. Он работает путем построения хэш-таблицы по данным по значениям столбцов group-by и нахождения записей с теми же самыми значениями столбцов group-by при исследовании (probing) хэш-таблицы. Хэширование значительно повышает производительность агрегирования данных.
Повышение производительности при хэшировании иллюстрируется следующим запросом, в котором вычисляется вклад индивидуальных заказчиков в доход. Сначала перечисляются наиболее крупные вкладчики.
select c.cust_last_name last_name, s.revenue revenue
from customers c,
(select cust_id, sum(amount_sold) revenue
from sales
group by cust_id ) s
where s.cust_id = c.cust_id
order by s.revenue desc;
В запросе потребляется много ресурсов центрального процессора. Чтобы гарантировать честное сравнение, вOracle Database 10 g R2 была отключена новая опция сортировки в оперативной памяти. В следующей ниже таблице производится сравнение производительности запроса вOracle Database 10 g R1 и R2.
|
Общее затраченное время (с) | |
|
Oracle Database 10g R1 |
395 |
|
Oracle Database 10g R2 |
171 |
В случае использования хэширования для агрегирования данных запрос в Oracle Database10 g R2 выполняется на 57% быстрее, чем запрос в Oracle Database10 g R1.
Так как агрегирование данных является весьма часто выполняемой задачей в хранилищах данных и для анализа бизнес-информации, значительное повышение производительности в результате хэш-агрегирования вOracle Database 10 g R2 имеет огромное значение.
СЕКЦИОНИРОВАННЫЕ ТАБЛИЦЫ
В Oracle Database 10 g R2 появились два основных изменения в секционировании. Чтобы увеличить масштабируемость и гибкость, количество разделов таблицы было увеличено с 64 К до 1 миллиона. Второе изменение связано с реализацией более эффективных методик отсечения, гарантирующих, что мы обращаемся только к тем разделам, которые удовлетворяют каким-либо предикатам запроса. Мы проиллюстрируем методики отсечения в Oracle Database 10 g R2 с двух различных сторон - отсечение разделов для предикатов дизъюнктивного OR и отсечение разделов, используя доступ по индексу.
Чтобы продемонстрировать усовершенствование при отсечении разделов для предикатов дизъюнктивного OR, используется следующий запрос.
select p.promo_name promo_name,(s.profit - p.promo_cost) profit
from promotions p,
(select promo_id,sum(sales.QUANTITY_SOLD*(costs.UNIT_PRICE - сosts.UNIT_COST)) profitfrom sales, costs where
( (sales.time_id BETWEEN TO_DATE('Ol-JAN-1998','DD-MON-YYYY', 'NLS_DATE_LANGUAGE = American') and TO_DATE('01-JAN-1999','DD-MON-YYYY', 'NLS_DATE_LANGUAGE = American'))
OR
(sales.time_id BETWEEN TO_DATE('01-JAN-2001','DD-MON-YYYY', 'NLS_DATE_LANGUAGE = American') and TO_DATE('01-JAN-2002', 'DD-MON-YYYY', 'NLS_DATE_LANGUAGE = American')) )
AND sales.time id = costs.time id
AND sales.prod_id = costs.prod_id
group by promo_id ) s where
s.promo_id = p.promo_id order by profit desc;
В запросе выполняется соединение таблиц SALES и COSTS. Таблица SALES секционирована по диапазону ключей для столбца TIME_ID. Одним из условий запроса являются два предиката для TIME_ID, которые объединены операцией OR. В Oracle Database 10 g R1 запрос преобразуется (с использованием OR-расширения) в два подзапроса, объединенные конкатенацией. В каждом подзапросе соединяются таблицы SALES и COSTS, используя одну ветвь предиката OR. В результате к таблице COSTS, в дополнение к операции конкатенации, обращаются дважды. Это показано в следующем плане выполнения запроса. Части плана, которые имеют дело с дизъюнктивными предикатами OR, выделены.
|
|

В Oracle Database 10 g R2 предикат OR непосредственно используется для отсечения разделов таблицы SALES, а между таблицами SALES и COSTS выполняется единственное соединение, как показано в приведенном ниже плане выполнения запроса. Опция хэш-агрегирования в Oracle Database 10 g R2 была отключена, чтобы гарантировать честное сравнение. Части плана, имеющие дело с дизъюнктивными предикатами OR, снова выделены.

В Oracle Database 10 g R1 были обращения к большему количеству данных, что связано с менее эффективным отсечением. Кроме того, хэш-соединения сбрасывались на диск, тем самым еще более увеличивая число запросов на физическое считывание и увеличивая число запросов на физическую запись. ВOracle Database 10 g R2 в результате лучшего отсечения и уменьшения числа запросов на физический ввод/вывод производительность запросов значительно повышается. Скорость выполнения запроса повышается на 30%. Скорость в единицах использования пользователем процессорного времени (количество времени, расходуемое центральными процессорами на выполнение запроса, просуммированное по всем процессорам), повышается на 24%.
|
Общее затраченное время (с) |
Пользовательское процессорное время (с) |
Запросы на физическое считывание |
Запросы на физическую запись | |
|
Oracle Database 10g R1 |
417 |
1334 |
87668 |
20772 |
|
Oracle Database 10g R2 |
294 |
1021 |
17402 |
72 |
Oracle Database 10 g R2 делает более эффективным использование предикатов запроса, в которых для отсечения ненужных разделов, определяются несмежные диапазоны разделов. Мы проиллюстрируем это, рассмотрев следующий запрос, в котором вычисляется общее количество AMOUNT_SOLD для списка заказчиков в течение двух несмежных периодов времени. Ради иллюстрации мы создаем глобальный индекс SALES_GIDX по столбцу CUST_ID секционированной таблицы SALES. Предикат запроса, используя предикат OR, определяет два непересекающихся диапазона разделов. ВOracle Database 10 g R2 Oracle обращается только к строкам, которые принадлежат разделам, определенным предикатом OR. Для обеспечения такой возможности в Oracle заводится список допустимых разделов, специфицированных предикатами. ВOracle Database 10 g R1 вместо этого для всех потенциально допустимых разделов заводится единый диапазон, что приводит к менее эффективному отсечению.
select cust_id, sum (amount_sold)
from sales
where
(time_id BETWEEN TO_DATE('Ol-JAN-1997','DD-MON-YYYY','NLS_DATE_LANGUAGE = American') and TO_DATE('01-JAN-1998','DD-MON-YYYY','NLS_DATE_LANGUAGE = American'))
OR
(time_id BETWEEN TO_DATE('Ol-JAN-2001','DD-MON-YYYY', 1NLS_DATE_LANGUAGE = American') and TO_DATE('01-JAN-2002', 'DD-MON-YYYY', 'NLS_DATE_LANGUAGE = American'))
) AND
cust_id in (50, 60, 70, 80, 1000, 1100, 1590, 4500, 80000, 250000, 350000, 400100, 430000)
group by cust_id;
В следующей ниже таблице суммируются результаты производительности для запросов в средах Oracle Database 10 g R1 и Oracle Database 10 g R2.
|
Общее |
Запросы на физическое считывание | |
|
Oracle Databasel0g R1 |
31 |
75968 |
В Oracle Database 10 g R2 благодаря более эффективному отсечению количество запросов на физическое считывание значительно уменьшается, что приводит к 68%-ому повышению скорости.
Как показывают эти два приведенные выше примера, реализация более эффективных методик отсечения в Oracle Database 10 g R2 значительно повышает производительность запросов, в которых участвуют секционированные таблицы. Такие связанные с отсечениями усовершенствования разделов, а также увеличение предельного количества разделов для таблицы еще более повышают масштабируемость и гибкость, позволяя эффективно обрабатывать большие наборы данных с большим количеством разделов.
СОЗДАНИЕ КОНТРОЛЬНЫХ ТОЧЕК ДЛЯ ОБЪЕКТОВ
Чтобы обеспечить оптимальное использование ресурсов аппаратных средств, Oracle Parallel Query может использовать прямой режим чтения. Чтение в прямом режиме позволяет подчиненным процессам параллельного запроса обходить кэш данных для запросов на чтение и издавать запросы на считывание любого размера, вплоть до максимального размера, допускаемого операционной системой. Однако прежде чем к объекту можно будет обратиться в прямом режиме чтения, модифицированные буферы объекта должны быть записаны обратно на диск с помощью запроса на создание контрольной точки для объекта. В Oracle Database 10 g R1 запрос на создание контрольной точки для объекта обрабатывается путем издания команды создания контрольной точки табличного пространства для того табличного пространства, которому принадлежит объект. При этом выполняется перезапись (на диск) всех модифицированных буферов всего табличного пространства. Так как в том же самом табличном пространстве может резидентно размещаться большое количество объектов, подобная реализация может вызвать большое число ненужных операций записи на диск. Запрос на создание контрольной точки для целевого объекта может привести к тому, что в дополнение к модифицированным буферам целевого объекта обратно на диск будут записаны модифицированные буферы других объектов, резидентно размещенных в том же самом табличном пространстве.
Для устранения подобной неэффективности в Oracle Database 10 g R2 запрос на создание контрольной точки для целевого объекта выполнит перезапись на диск модифицированных буферов только для целевого объекта и не повлечет за собой никаких дополнительных операций записи для модифицированных буферов других объектов.
Чтобы проиллюстрировать преимущества в производительности, обеспечиваемые новой реализацией Oracle Database 10 g R2, мы предположим, что к таблице PRODUCTS_AFFINITY_CARD_A применен следующий оператор обновления:
update products_affinity_card_a set home_theater_package=0
where yrs_residence <2;
Оператор обновления изменяет 808 760 строк. Сразу же после его выполнения в буферном кэше содержится около 84 000 модифицированных страниц из таблицы PRODUCTS_AFFINITY_CARD_A.
Сразу же после того, как произошло обновление, выполняется следующий оператор параллельной выборки (select), чтобы вычислить максимальную среднюю стоимость продуктов.
select max(avg_costs)
from (select avg(unit_cost) avg_costs
from costs
group by prod_id);
Перед выполнением этого оператора Oracle Database 10 g R1 должен создать контрольную точку для модифицированных буферов таблицы PRODUCTS_AFFINITY_CARD_A, в то время как Oracle Database 10 g R2 в состоянии выполнить оператор select непосредственно, не записывая модифицированные страницы на диск.
Чтобы гарантировать честное сравнение, опции сортировки в оперативной памяти и хэш-агрегирования в Oracle Database 10g R2 были заблокированы, в результате чего и Oracle Database 10 g R1, и Oracle Database 10 g R2 при выполнении запроса select использовали следующий план выполнения:
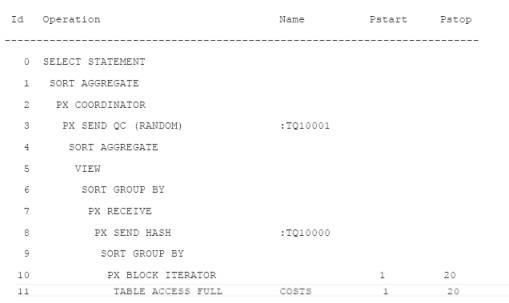
В среде Oracle Database 10 g R1 выполнение запроса на параллельный выбор (select) сразу же после обновления занимает 27 секунд, в то время как в среде Oracle Database 10 g R2 эта же операция занимает только 13 секунд. Это связано с тем, что оператор обновления обновил таблицу, существующую в том же самом табличном пространстве, что и объект, к которому обращается запрос select. В среде Oracle Database 10 g R1 перед выполнением запроса select дополнительное время расходуется на сбрасывание на диск модифицированных буферов таблицы PRODUCTS_AFFINITY_CARD_A.
В результате вOracle Database 10 g R2 значительно повышается производительность параллельного запроса, потому что режим прямого доступа к объекту не будет замедляться созданием контрольных точек для модифицированных буферов других объектов в том же самом табличном пространстве.
ВСТРОЕННЫЕ SQL-ФУНКЦИИ APPLY ДЛЯ "ДОБЫЧИ ДАННЫХ"
В процессе добычи данных (data mining) имеется этап построения модели с использованием на первом шаге обучающего набора данных. Затем эта модель применяется к новым наборам данных, чтобы генерировать предсказания. Так как существующая модель может быть применена ко многим различным новым наборам данных, операция APPLY часто вызывается заказчиками для исследования своих баз данных. В результате производительность и удобство и простота использования операции APPLY становятся очень важными.
В терминологии добычи данных функцию APPLY принято также называть SCORING, следовательно, входной набор данных (таблица) для операции APPLY можно назвать данными (таблицей) SCORING. APPLY в Oracle Database 10 g R1, используя API PL/SQL, служит "пакетной" процедурой оценки, которая на входе принимает таблицу и в качестве выходных данных также предлагает таблицу. APPLY, используя API JAVA, реализует для записей операцию применения (apply). Среди недостатков ее реализации в Oracle Database 10 g R1 можно назвать следующие:
- Производительность ограничена сложным соединением (ями) таблиц модели и таблиц оценки. Многократные материализации промежуточных результатов препятствуют прозрачной обработке SQL-запроса. Многие из отображений и преобразований могут быть настолько дорогими, что начинают доминировать над временем, необходимым для выполнения APPLY.
- Так как не допускается совместное использование модели при многократных вызовах одной и той же операции apply, она должна загружаться в память при каждом вызове APPLY.
- Более того, перед использованием APPLY новичок (или неопытный пользователь) должен быть знаком с JAVA и API PL/SQL.
В среде Oracle Database 10 g R2 функциональные возможности APPLY стандартизируются посредством наличия встроенной SQL-функции для оценки модели. Среди преимуществ реализации Oracle Database 10 g R2 можно назвать следующие:
- Производительность APPLY повышается из-за изменений в реализации, предоставляемых встроенными SQL-функциями. В некоторых случаях повышение производительности оказывается весьма существенным.
- Существующие функциональные возможности выполнения запроса, типа общих курсоров, для кэширования метаданных модели, позволяют совместное использование модели для различных вызовов APPLY.
- Предоставление встроенных SQL-функций для APPLY существенно повышает удобство и простоту использования. Неопытный пользователь в состоянии быстро обучиться, как следует применять существующую модель к новому набору данных. Развертывание моделей в контексте существующих приложений становится прямым, так как существующие SQL-операторы могут легко быть расширены этими новыми функциями APPLY. Встроенная SQL-функция также допускает конвейерную обработку результатов, в числе которых могут быть предсказания розыска данных, обеспечивая возможность быстро возвратить небольшой объем результатов конечному пользователю.
Встроенные в Oracle Database 10 g R2 SQL-функции оценки могут применять модели, построенные на базе различных алгоритмов добычи данных. В этой статье для построения модели используется алгоритм адаптивных сетей Байеса (Adaptive Bayes Network - ABN). ABN является алгоритмом классификации. Модель классификации, построенная с помощью алгоритма ABN для обучающего набора данных, может использоваться для классификации каждой записи в применяющемся наборе данных (apply dataset), указывая, какому классу принадлежит запись. Например, нам надо выяснить, имеется ли у Заказчика так называемая affinity card (кредитная карточка для группы лиц, объединенных общими интересами - прим. переводчика ) на основании истории его покупок, типа того, сколько больших пакетов DVD-дисков купил Заказчик, сколько мониторов с плоским экраном у него имеется, сколько бухгалтерских приложений им куплено и т.д. Каждый заказчик может быть отнесен к одному из двух классов: имеющих и не имеющих групповые кредитные карты. Групповую карту ( скорее, ее наличие или отсутствие - прим. переводчика ) называют целью, а истории покупок заказчиков называют предсказателями (или прогнозаторами). Такие задачи классификации начинаются с обучающего набора данных, для которого мы заранее знаем, имеется ли у заказчика групповая карта. Отношения между предсказателями и целью в обучающих данных сохраняются в модели, которая может впоследствии быть применена к новым наборам данных для предсказания, например, имеется ли у заказчика групповая карта.
Для Oracle Database 10 g R2 и для Oracle Database 10 g R1 мы использовали один и тот же обучающий набор данных для построения модели ABN, которая затем была применена к тому же самому набору данных для оценки. Мы сравнили производительность APPLY для Oracle Database 10 g R2 и Oracle Database 10g R1.
В нашем обучающем наборе данных PRODUCTS_AFFINITY_CARD_B имеется 250 столбцов и 50 000 строк. Таблица содержит столбец идентификации (CUST_ID), цель (AFFINITY_CARD) и 248 предсказателей типа YRS_RESIDENCE, BULK_PACK_DVDS и FLAT_PANEL_MONITOR и т.д. Построение модели ABN с именем 'ABN_Clas' и в Oracle Database 10 g R1, и вOracle Database 10 g R2 занимает приблизительно 40 минут.
Когда модель 'ABN_Clas' построена, ее можно использовать, чтобы делать предсказания для рабочего набора данных. Рабочая таблица PRODUCTS_AFFINITY_CARD_A содержит 2 миллиона строк. И в Oracle Database 10 g R1, и в Oracle Database 10 g R2 для применения модели 'ABN_Clas' к рабочей таблице может использоваться следующая программа на PL/SQL, сохраняющая свои результаты в таблице APPLY_RESULT.
- Таблица APPLY (рабочая) должна быть загружена (binned) тем же образом, что и
обучающая таблица.
- abn_num - это bin-таблица, которую мы сгенерировали, когда загружали (binning) обучающую таблицу.
BEGIN
DBMS_DATA_MINING_TRANSFORM.XFORM_BIN_NUM (
bin_table_name => 'abn_num',
data_table_name => ' PRODUCTS_AFFINITY_CARD_A' ,
xform_view_name => ' abn_apply_prepared' ) ;
END;- материализуйте подготовленную рабочую таблицу для повышения производительности.
create table abn_apply_prepared_table as select * from abn_apply_prepared;
alter table abn_apply_prepared_table parallel;- ПРИМЕНИТЕ (APPLY) МОДЕЛЬ
BEGIN
DBMS_DATA_MINING. APPLY (
model_name => 'ABN_Clas',
data_table_name => ' abn_apply_prepared_table ' ,
case_id_column_name => 'CUST_ID',
result_table_name => ' APPLY_RESULT ' ) ;
END;
Хотя приведенный выше код может использоваться как в Oracle Database 10 g R1, так и в Oracle Database 10 g R2, лежащие в основе реализации для DBMS_DATA_MINING.APPLY отличаются. В Oracle Database 10 g R2 при вызове DBMS_DATA_MINING.APPLY вызывается встроенная SQL-функция PREDICTION_SET. Кроме того, эти встроенные SQL-функции, ставшие доступными в Oracle Database 10 g R2, могут быть вызваны в SQL-операторе, что делает функциональность APPLY очень удобной для использования. Так, например, следующий SQL-оператор
select cust_id, prediction(ABN_Clas using *) as my_pred from abn_apply_prepared_table;
для каждого заказчика, сохраненного в таблице abn_apply_prepared_table, предсказывает, имеется ли у него групповая карта, используя для этой цели предварительно подготовленную модель классификации ABN_Clas. Встроенная SQL-функция PREDICTION более проста, чем PREDICTION_SET. Она возвращает наилучшее предсказание для модели классификации при условии задания набора предсказателей, в то время как функция PREDICTION_SET возвращает массив VARRAY объектов, содержащий все классы и вероятность для каждого класса. Если в таблице abn_apply_prepared_table хранится информация о двух миллионах заказчиков, вышеупомянутый SQL-запрос возвращает 2 миллиона строк. Чтобы избежать необходимости измерять общее время, затраченное на вывод 2 миллионов строк, вышеупомянутый запрос был изменен следующим образом, чтобы облегчить измерение производительности:
select count(distinct prediction(ABN_Clas using *)) from abn_apply_prepared_table;
При применении модели заказчики Oracle Database 10 g R2 могут выбрать один из трех методов. В первом методе, как показано выше в упомянутом примере, используется PL/SQL-программа. Этот метод мы обозначим как Oracle Database 10 g R2 (PL/SQL). Во втором методе должен использоваться SQL-запрос, типа того, что показан выше. Этот метод мы обозначим как Oracle Database 10 g R2 (SQL). И, наконец, можно также использовать интерфейс API JAVA, который не участвовал в описанном в этой статье эталонном тестировании. Подобно API PL/SQL, API JAVA в Oracle Database 10 g R2 образует уровень поверх встроенных SQL-функций APPLY.
В приведенной ниже таблице суммируются результаты производительности для APPLY в среде Oracle Database 10 g R1 и APPLY в среде Oracle Database 10 g R2 с использованием описанных PL/SQL- и SQL- методов.
|
Общее затраченное время |
Временное пространство | |
|
Oracle Database 10 g R1 |
1 час 59 мин 36.56 сек |
10 Гбайт |
|
Oracle Database 10 g R2(PL/SQL) |
59.6 сек |
0 |
|
Oracle Database 10 g R2 (SQL) |
10.38 сек |
0 |
Встроенные SQL-функции оценки в значительной степени повышают производительность APPLY как в плане общего затраченного времени, так и использования временной дисковой памяти. Улучшение использования временной дисковой памяти означает существенную экономию требующейся памяти. Использование встроенных SQL-функций оценки непосредственно в SQL-операторе приводит даже к более быстрому функционированию APPLY и к появлению пользовательского интерфейса, который намного более доступен для понимания неопытными пользователями. Улучшенная производительность и расширенные удобство и простота использования для APPLY в Oracle Database 10 g R2 позволяет легко и эффективно обрабатывать большие наборы данных.
УСОВЕРШЕНСТВОВАНИЯ В АЛГОРИТМЕ МЕТОДА ОПОРНЫХ ВЕКТОРОВ
Введенный вOracle Database 10 g R1 метод опорных векторов (Support Vector Machines - SVM) является современным алгоритмом добычи данных, который поддерживает задачи регрессии и классификации. Задачи классификации предсказывают целевой класс, базируясь на ряде предсказателей. Например, мы можем предсказать, имеет ли или нет человек высокий уровень дохода, базируясь на предсказателях типа возраст заказчика, род его занятий и т.д. В этом случае человек принадлежит одному из двух целевых классов: группе с высоким или низким доходом. Вместо того, чтобы предсказывать целевой класс (дискретное или категорийное значение), задачи регрессии предсказывают числовые/непрерывные цели. Например, мы можем предсказать фактический размер дохода, базируясь на данных об образовании, роде занятий и т.д.
В SVM-терминологии логические строки, связанные с объектами анализа, например, с заказчиками, рассматриваются как шаблоны (patterns). Каждый шаблон является вектором, состоящим из значений предсказателей и целевого значения. SVM -алгоритм ищет прогнозирующие шаблоны (опорные векторы). Например, чтобы предсказать наличие высокого или низкого дохода, SVM-классификатор отделяет эти два целевых класса по границе решения. Такая граница решения представляет гиперплоскость в пространстве высокой размерности. В случае данных низкой размерности для преобразования входного пространства в пространство опций высокой размерности могут использоваться нелинейные ядерные функции (например, гауссовы ядра). Пространство опций высокой размерности дает SVM-моделям гибкость, требующуюся для точного соответствия произвольно сложным нелинейным поверхностям решения. Для данных высокой размерности нелинейное ядерное преобразование к пространству опций более высокой размерности обычно не является необходимым, и для них могут быть использованы линейные ядра.
Как и в случае с любым другим алгоритмом классификации или регрессии, процесс SVM-добычи данных связан с построением модели для обнаружения отношений между предсказателями и целью. После того, как модель построена, тестирование модели оценивает ее точность. В процессе тестирования модель применяется к независимому набору данных, для которого доступны целевые значения. Модель с удовлетворительной точностью может использоваться для генерации предсказаний для набора данных, где целевое значение неизвестно. Этот процесс называется APPLY.
Реализация SVM в Oracle Database 10 g R1 сопоставима с другими публично доступными инструментальными SVM-средствами (например, SVMLight, LIBSVM, SVMTorch и SVMFu) в терминах скорости и точности. Но стандартному SVM-подходу присущи некоторые ограничения. При росте числа записей данных время обучения для SVM-модели масштабируется квадратично или даже кубически. Кроме того, модели с нелинейными ядрами, а в некоторых случаях и с линейными ядрами, могут стать очень большими по размеру, что приводит к медленному построению модели и низкой производительности при ее применении.
Для решения проблем, свойственных масштабируемости стандартного SVM-подхода, в Oracle Database 10 g R2 комбинируется активное обучение и стратифицированная выборка. Метод эффективно выбирает самые информативные примеры для сокращения числа опорных векторов. В результате время построения и применения имеющейся модели значительно сокращается. Метод активного обучения предлагает приближенные решения, но для большинства случаев точность этих приближенных решений сопоставима (всего лишь немногим хуже чем) с точностью стандартных SVM-моделей.
Для иллюстрации усовершенствований, достигнутых новым методом, мы сначала построим SVM-модель, используя обучающий набор данных как вOracle Database 10 g R1, так и в Oracle Database 10 g R2, и сравним время построения, использование временной дисковой памяти, размер модели, а также количество опорных векторов. Затем мы проверим обе модели, чтобы сравнить точность модели, используя тестовый набор данных. И, наконец, мы применим обе модели к рабочему набору данных и сравним общее затраченное время и использование временной дисковой памяти.
Наша задача классификации состоит в том, чтобы принять решение, имеет или нет человек высокий доход, базируясь на следующих предсказателях: AGE, WORKCLASS, FNLWGT, EDUCATION, EDUCATION_NUM, MARITAL_STATUS, OCCUPATION, RELATIONSHIP, RACE, SEX, CAPITAL_GAIN, CAPITAL_LOSS, HOURS_PER_WEEK и NATIVE_COUNTRY.
В обучающем наборе данных SUPPLEMENTARY_DEMOGRAPHICS_B содержится 32 561 строка. Мы строим SVM-модель с гауссовыми ядрами в средах Oracle Database 10 g R1 и R2. В приведенной ниже таблице показана производительность моделей, построенных для обеих версий.
|
Общее затраченное время |
Временная память (Мб) |
Размер модели (Мбайт) |
К-во опорных векторов | |
|
Oracle Database10gR1 |
10 мин 47.40 сек |
3 |
6 |
11,756 |
|
Oracle Database10gR2 |
9.82 сек |
1 |
.5625 |
300 |
На построение SVM-модели в Oracle Database 10 g R2 расходуется гораздо меньше времени, чем в Oracle Database 10 g R1. Кроме того, в Oracle Database 10 g R2 требуется намного меньший объем временного табличного пространства, что указывает на то, что новый метод сокращает потребность в памяти. Значительное сокращение общего затраченного времени и использования временной дисковой памяти в Oracle Database 10 g R2 стало результатом уменьшения размера модели.
Чтобы подтвердить уменьшение размера модели, мы протестировали обе модели, используя тестовые данные SUPPLEMENTARY_DEMOGRAPHICS_T с 16 281 строками, и сравнили точность моделей.
|
Точность, вычисленная по матрице неточностей |
Площадь под кривой ROC | |
|
Oracle Database 10g R1 |
.8469 |
.8935 |
|
Oracle Database 10g R2 |
.8227 |
.8673 |
Имеются различные показатели точности модели. Точность, вычисленная по матрице неточностей для Oracle Database 10 g R1, составляет 0.8469. Это означает, что число раз, когда модель SVM, построенная вOracle Database 10 g R1, правильно предсказывает целевой класс, равно 0.8469 * 16 281, где 16 281 - это полное число строк в тестовом наборе данных. Число случаев, когда класс целевого атрибута предсказан неправильно, равно (1-0.8469) * 16281.
Еще одним полезным показателем для оценки модели классификации является так называемая эксплуатационная характеристика приемника (Receiver Operating Characteristic - ROC). Площадь под кривой ROC (Area Under ROC - AUC) измеряет дискриминирующую способность двухуровневой модели классификации. Чем больше AUC, тем выше вероятность, что фактически положительному случаю (высокий доход) будет назначена более высокая вероятность наличия высокого дохода, чем фактически отрицательному случаю (низкий доход). Показатель AUC особенно полезен для наборов данных с несбалансированным распределением целей (то есть таких, где один целевой класс доминирует над другим).
Как мы можем видеть из вышеупомянутой таблицы, приблизительная модель приводит всего лишь к небольшой потере точности модели.
Наконец, чтобы сравнить производительность APPLY, мы используем набор данных SUPPLEMENTARY_DEMOGRAPHICS_A с 97 684 записями. В приведенной ниже таблице показаны результаты производительности APPLY в средах Oracle Database 10 g R1 и R2.
|
Общее затраченное время |
Временная память (Мбайт) | |
|
Oracle Database 10g R1 |
6 мин 6.29 сек |
7 |
|
Oracle Database 10g R2 |
36.51 сек |
0 |
В результате уменьшения размера модели производительность APPLY в Oracle Database 10 g R2 в десять раз превышает производительность в Oracle Database 10 g R1. Модель не только выполняется быстрее, но и требует меньшего количества памяти, на что указывает показатель использования временной дисковой памяти. Недавно введенные встроенные SQL-функции для APPLY вOracle Database 10 g R2, о которых шла речь в предыдущем разделе этой статьи, также вносят свой вклад в это повышение производительности.
Методология SVM в Oracle Database 10 g R2 значительно повышает производительность SVM-алгоритма и при построении, и при применении с малой потерей точности модели. Она также позволяет использовать SVM-модели для наборов данных больших размеров, которые не могли быть обработаны в Oracle Database 10 g R1.
ЗАКЛЮЧЕНИЕ