Введение
Многие организации вынуждены бороться с несопоставимостью и распределенным характером информации. Зачастую пользователи тратят очень много времени на поиск и сбор, сопоставление и коррекцию релевантной информации вручную, вместо того, чтобы использовать полученную информацию в своей непосредственной деятельности.
Эта широко известная проблема встречается и при реализации сервис-ориентированной архитектуры (Service-Oriented Architecture, SOA). Часто для работы основных сервисов необходима агрегированная, качественная информация из нескольких различных источников данных.
Указанные потребности в интеграции информации можно удовлетворить с помощью нескольких концепций и технологий. Одна из таких технологий - интеграция данных (data federation). Технология интеграции данных предназначена для эффективного объединения данных из нескольких разнотипных источников без перемещения данных - тем самым устраняется образование избыточных данных. Шаблон интеграции данных поддерживает операции с интегрированным и временным (виртуальным) представлением данных, хранящихся в нескольких различных источниках. Исходные данные остаются под контролем систем-источников и извлекаются по требованию для интегрированного доступа.
В этой статье особо подчеркивается значение принципа интеграции данных. После описания контекста применения интеграции данных, мы рассмотрим проблему, которую решает наш шаблон, а также само решение. Мы рассмотрим применимость данного шаблона, исходя из нефункциональных требований (см. раздел Что следует учитывать). Наш опыт в применении этого шаблона иллюстрируют несколько широко известных случаев его применения. В завершение мы рассмотрим области применения, области риска и ограничения этого шаблона.
Предположительная ценность принципа интеграции данных
Прозрачность базовой неоднородности информации для пользователя
Благодаря интеграции данных потребитель имеет дело с единым и единообразным интерфейсом. Прозрачность размещения информации означает, что приложению, потребляющему данную информацию, нет необходимости иметь представление о том, где хранятся данные. Благодаря прозрачности вызова оно может также не знать, какой язык или интерфейс программирования поддерживается исходной базой данных. Например, если используется SQL, то для приложения не имеет значения, какой из диалектов этого языка запросов используется. Приложению также необязательно знать физические условия хранения данных вследствие физической независимости данных, прозрачности фрагментации и репликации, или о том, какие используются сетевые протоколы (сетевая прозрачность).
Преимущество: от начала разработки до выхода на рынок
Приложение, являющееся потребителем сервера интеграции данных, может взаимодействовать с единым виртуальным источником данных. Если не использовать шаблон интеграции, то приложение должно взаимодействовать с несколькими источниками данных индивидуально через различные интерфейсы, с использованием разных протоколов. По данным исследований, шаблоны интеграции данных способствуют значительной экономии времени на разработку при необходимости интегрировать несколько источников.
Сокращение затрат на разработку и обслуживание
Многие потребители могут потенциально иметь одинаковые - или очень сходные - потребности в интегрированной информации. По одному из подходов к интеграции, каждый потребитель имеет собственную реализацию для агрегации информации из разнородных источников. Альтернативно, интегрированное представление разрабатывается однажды и после этого используется несколько раз и обслуживается централизованно, таким образом формируется единая точка изменения. Такой подход сокращает расходы на разработку и обслуживание.
Преимущество по производительности
Внедрение шаблона интеграции данных с ориентацией на конкретную передовую технологию обработки данных в большинстве случаев показывает более высокие показатели производительности по сравнению с кустарным подходом к агрегации информации. Благодаря использованию улучшенных функций обработки запросов сервер интеграции может оптимально распределить рабочую нагрузку между собственными ресурсами и различными источниками. Для оптимизации времени отклика он определяет, какие части рабочей нагрузки с наибольшей эффективностью будут выполнены различными серверами.
Преимущество многократности использования
После применения шаблона интеграции данных к конкретному сценарию интеграции результат этого обращения может быть предоставлен в виде сервиса для нескольких потребителей сервиса. Например, некоторый сценарий интеграции может требовать извлечения структурированных и неструктурированных данных по страховым искам от широкого круга источников. В этом примере шаблон интеграции данных может лечь в основу решения по интеграции данных по искам, которые впоследствии через корпоративный портал может изучить агент по искам. Эту же интегрированную выборку затем можно использовать в качестве сервиса для других потребителей, например, автоматизированных процессов стандартных приложений по обработке исков, или клиентов, работающих с Web-приложениями.
Улучшенное управление
Управление - это основа жизненного цикла SOA. При использовании шаблонов процесс управления становится более совершенным благодаря применению передовых методов с прогнозируемым выводом. Многократное использование хорошо зарекомендовавших себя динамичных шаблонов в разработке и создании систем может одновременно улучшить целостность и качество, а также сократить затраты на обслуживание благодаря необходимости изменения информации в едином источнике данных.
Контекст
При слиянии и присоединении компаний и организаций у архитекторов данных и приложений часто возникает необходимость в интеграции несопоставимых источников данных в унифицированное представление данных. Потребители этой интегрированной информации - это традиционные приложения, которые взаимодействуют непосредственно с базами данных и нуждаются в доступе к расширенному набору источников данных. Решение о наилучшем способе создания этого унифицированного представления часто выбирается с учетом доступности инструментария, опыта, квалификации и уровня информационной культуры организации. При использовании традиционных архитектур время, усилия и затраты, связанные с интеграцией, могут свести на нет ее преимущество для бизнеса. При реализации в сервис-ориентированной среде подход, основанный на использовании информационных сервисов на основе шаблонов, может с течением времени улучшить характеристики повторного использования.
Информационные сервисы - компонент главного направления SOA. Эти информационные сервисы обеспечивают доступ к информации домена с правами на "создание, чтение, обновление, удаление" (Create-Read-Update-Delete, CRUD). Они также демонстрируют возможности обработки информации, такие как результаты аналитических и оценочных алгоритмов, правила очистки данных и т. п. В этой статье мы сконцентрируемся на сервисах интеграции информации, которые предоставляют унифицированное представление данных, что часто связано с интеграцией умопомрачительного массива разнородных источников на стороне сервера и сервисов.
Применяя шаблон интеграции данных, необходимо различать два контекста: традиционный, не-SOA контекст, к которому адресуются многие ранее созданные приложения, и SOA-контекст, о котором и пойдет речь в данной статье. Важно иметь в виду, что SOA - это архитектурный принцип, позволяющий получить многократно используемые сервисы, которые во многих случаях расширяют возможности существующих реализаций без использования SOA.
Традиционный контекст
В традиционном контексте приложению для создания отчетов в банке может потребоваться анализ транзакций по кредитным картам. Учитывая объем этих данных - в день совершается не один миллион транзакций - нельзя назвать эффективным хранение всей этой информации в аналитическом хранилище. К более старым данным обращаются крайне редко, как и к некоторой контекстной информации вроде маршрута полета. Хранение всей информации о транзакциях - текущей и устаревшей, основной и второстепенной - в хранилище отрицательно сказывается на производительности. Есть решение лучше - разделить эти данные на два типа: часто используемые самые последние транзакции по кредитным картам хранятся в хранилище, тогда как более старая информация хранится, например, на лентах с резервными копиями. Однако приложению для создания отчетов не нужно знать о таком распределении данных; это можно обеспечить благодаря принципу интеграции.
Рисунок 1. Шаблон интеграции традиционных данных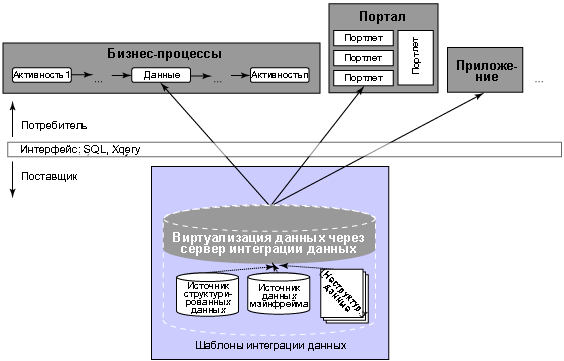
В этом традиционном контексте приложения для диалога с сервером интеграции обычно используют стандартные реляционные интерфейсы и протоколы, например, SQL и JDBC/ODBC. В свою очередь, сервер интеграции через различные адаптеры или оболочки подключается к таким различным источникам данных, как реляционные базы данных, XML-документы, пакеты приложений и системы управления контентом и совместной работой. Сервер интеграции - это виртуальная база данных со всеми функциями реляционной базы данных. Приложение или пользователь может выполнить любые запросы в рамках предоставленных ему полномочий доступа. По выполнении запроса возвращается результирующий набор, содержащий все записи, которые отвечают критериям выбора. Это показано на рисунке 1. Рисунок иллюстрирует тот факт, что традиционная реализация может быть построена на реляционном интерфейсе прикладного программирования (API) с использованием SQL (JDBC/ODBC) или XQuery.
SOA-контекст
В контексте SOA у сервиса getCustomerCreditCardData может возникнуть необходимость извлечь комплексную информацию о клиенте и последних транзакциях по его кредитной карте. Эта информация может храниться не в одной системе. Информация о клиенте может храниться в главной системе управления сведений о клиентах, а информация о транзакциях по кредитной карте - в другом источнике данных. Интеграция данных объединяет информацию из нескольких источников таким образом, чтобы ее можно было показать клиенту в виде сервиса.
В контексте SOA сервер интеграции может действовать как поставщик сервиса и/или потребитель сервиса, использующий интерфейсы, соответствующие требованиям SOA. Обратите внимание на то, что это не мешает серверу предоставлять поддержку для традиционных, реляционных интерфейсов. Решение с поддержкой обоих типов интерфейса в данной статье не рассматривается. Если сервер интеграции как поставщик сервиса предоставляет интегрированную информацию, потребитель сервиса может обращаться к интегрированной информации через интерфейс сервиса, например, WSDL и HTTP/SOAP или другой интерфейс, выбранный для привязки. Сервер интеграции может потреблять - с целью интеграции - сервисы, предоставляемые несколькими источниками информации.
Идея, лежащая в основе использования шаблона интеграции данных в контексте SOA - это повышение отдачи от информации и ее многократное использование, то есть создание расширяемых сервисов интеграции информации для различных потребителей. Моделирование и определение сервисов - ключевой аспект SOA. Общепринятой практикой является разработка сервисов, допускающих многократное использование и/или межкорпоративную функциональную совместимость и/или включение информации или функции в бизнес-процесс. Многие из наиболее успешных проектов SOA концентрируются, в первую очередь, на самых важных, наиболее широко используемых бизнес-функциях, которые предлагаются в форме сервисов. Вследствие того, что такие сервисы играют ключевую роль, они часто объединяют несколько серверных систем. Поэтому сбор информации от нескольких разнородных источников - одно из самых важных требований и одновременно функция, от которой зависит архитектура SOA. Сервис - это не запрос в традиционном смысле обращения к данным, скорее, это извлечение некоторой бизнес-сущности (или сущностей), которое может быть выполнено сервисом интеграции через серию запросов и других сервисов.
Рисунок 2. Шаблон интеграции данных в контексте SOA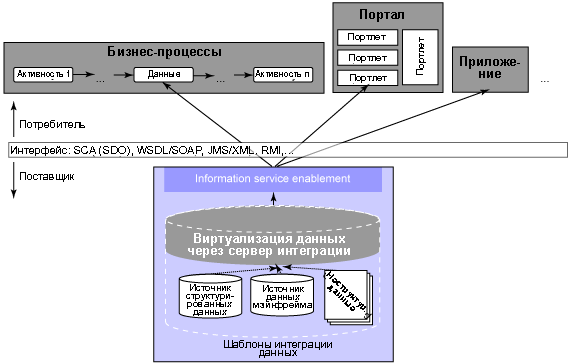
Включение в SOA сервисов интеграции информации требует дополнительных функций для инкапсуляции интегрированной выборки в сервис-ориентированный интерфейс. Это достигается через компонент Information Service Enablement . Цель этого компонента - показ отдельных интегрированных запросов в сервис-ориентированном интерфейсе. Например, интегрированный запрос может быть написан на SQL и определять доступ к информации о продукте. Через компонент Information Service Enablement этот интегрированный запрос может затем быть представлен в виде сервиса, например, с помощью SCA или WDSL. Этот сервис, реализующий выборку данных о продукте, может затем совместно использоваться сотрудниками данной корпорации и за ее пределами.
Решения, в которых используется шаблон интеграции данных в традиционном контексте, используют преимущества декларативного и динамичного характера SQL. Имея соответствующие учетные данные системы безопасности, потребитель может осуществить выборку любых данных из источника через почти неограниченное количество различных запросов SQL. Потребитель имеет достаточно свободы в выборе информации, к которой он обращается, и формата, в котором будут возвращены результаты. Хотя такая гибкость во многих ситуациях является преимуществом, она создает дополнительные сложности для потребителей. Потребитель должен иметь представление о модели источника данных и способе создания результата с использованием этой базовой модели. Чем сложнее модель источника данных, тем более сложной может оказаться эта задача.
Подход SOA концентрируется, в первую очередь, на определении и совестном использовании в форме сервисов относительно ограниченного количества самых важных бизнес-функций в корпорации. Следовательно, сервис-ориентированные интерфейсы в довольно большой степени строятся на ограниченном количестве запросов на необходимую информацию, которую нужно представить потребителю. Такая ясная и ограниченная задача - это преимущество для разработчиков, поскольку им требуется меньше времени для разработки запросов на информацию. Они могут просто выбрать соответствующий сервис из ограниченного количества возможных вариантов.
Постановка задачи
В современной производственной среде, основанной на использовании информации, архитекторы и разработчики часто реализуют решения интеграции данных. Проблемы, с которыми они сталкиваются, обычно вызываются некоторыми архитектурными решениями, которые могут диктоваться ограничениями технического, делового или договорного характера. В следующем сценарии присутствуют несколько из этих распространенных ограничений. Во-первых, данные, необходимые для поддержки условия выборки информации проекта, размещаются в нескольких источниках; их необходимо интегрировать и представить потребителю в виде единого результата. Далее, целевые источники данных, чтобы удовлетворять условиям доступа, не могут быть реплицированы или скопированы. И наконец, решение необходимо интегрировать в существующую структуру SOA, но при этом необходимо обеспечить поддержку традиционных (не-SOA) приложений, как показано на рисунке 3.
Рисунок 3. Доступ через разнотипные интерфейсы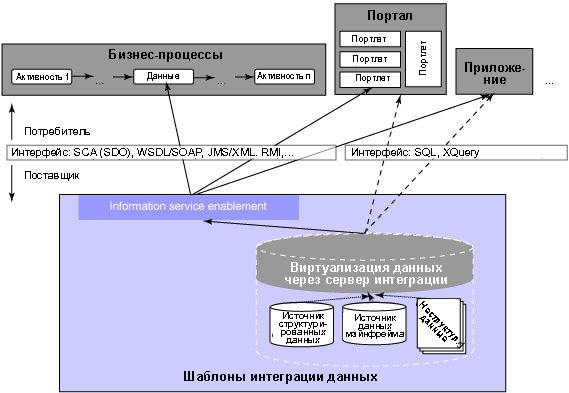
Задачи программного решения
Как описано в постановке задачи, цель этого подхода заключается именно в предотвращении избыточности данных при создании интегрированного представления данных на основе разнотипных источников. Сервер интеграции данных - то есть, компонент, который реализует шаблон интеграции данных - должен предоставить стандартный интерфейс запросов для нетрадиционного контекста SOA. Этим обеспечивается возможность потребления интегрированных данных широким кругом традиционных приложений баз данных. Кроме того, чтобы с большей эффективностью отвечать на запросы, сервер интеграции должен предоставить функции оптимизации запросов. Распределенный и неоднородный характер данных в этом контексте требует особого внимания к выбору наилучшего способа перевода выборки в интегрированное представление, к разделению и распределению рабочей нагрузки. При поддержке доступа для записи к интегрированному представлению, сервер интеграции должен синхронизировать манипуляции над данными в различных источниках в одну логическую единицу работы. Это обеспечит соответствие критериям ACID (атомарности, непротиворечивости, изолированности и долговечности) для транзакций и достижению относительной непротиворечивости данных.
В дополнение к описанным задачам, которые задаются традиционным контекстом, данный подход должен вписываться в структуру SOA. Это позволит широкому кругу потребителей в границах корпорации и за ее пределами эффективно и многократно использовать интегрированные представления. Потенциальные потребители интегрированной выборки в SOA - это приложения, порталы и деятельности в рамках бизнес-процесса, нуждающиеся в доступе к распределенной информации. Например, производитель может создать сервис, который получает информацию о товарном запасе в реальном времени из разнородных источников. Затем к этому сервису обращаются внутренние приложения, а также внешние бизнес-партнеры, которые используют непротиворечивую и наиболее эффективную реализацию этой интегрированной выборки.
Описание решения
И в традиционном контексте, и в контексте SOA сервер интеграции данных предоставляет решение для эффективного объединения и обработки информации из разнотипных источников. Этот шаблон обеспечивает синхронный интегрированный подход к распределенным данным в режиме реального времени. Сервер интеграции данных отвечает за получение запроса, адресованного интегрированному представлению различных источников. Он преобразует этот запрос с помощью сложных оптимизирующих алгоритмов, в результате чего запрос разбивается на серию операций (это называется секционированием и перезаписью запроса), применяет эти операции к соответствующим источникам, собирает результаты от всех источников, выполняет сборку интегрированных результатов и, наконец, возвращает интегрированные результаты инициатору запроса. Эта последовательность обработки данных осуществляется синхронно в реальном времени.
Особенности проектного этапа
Шаблон интеграции данных требует сопоставления элементов данных из различных источников, которые входят в интегрированное представление. Например, такая информация о клиенте, как имя и адрес держателя полиса из приведенного выше примера, может храниться в одной таблице в одной базе данных и в нескольких таблицах в другой базе данных. Чтобы построить интегрированное представление, такие различные типы представления данных необходимо привести к общему виду. Такое приведение может осуществляться исполнителем-человеком вручную или с помощью современных инструментов, использующих различные алгоритмы приведения, которые, кроме того, учитывают все необходимые требования к преобразованию данных. Это позволяет серверу интеграции данных получить запросы к интегрированному представлению и рассчитать оптимальное количество и тип необходимых подопераций.
При применении шаблона интеграции данных в контексте SOA необходимо, чтобы набор интегрированных запросов был включен и зарегистрирован в структуре SOA в виде сервисов. Например, интегрированное представление для извлечения важной структурированной и неструктурированной информации о держателе полиса, например, имени, состояния, исковой документации, оценки ущерба и риска, может быть запущено как сервис и совместно использоваться несколькими потребителями. Результат приведения (сопоставления) на проектном этапе - это, как правило, интегрированные представления, аналогичные представлениям реляционных баз данных, которые можно разместить или создать на сервере интеграции.
Рабочий цикл
Сервер интеграции данных получает запрос к интегрированному представлению. В соответствии с определением сопоставления, сервер интеграции разбивает интегрированный запрос на несколько подопераций. На этом шаге имеют значение несколько факторов:
- Где размещаются данные, необходимые для ответа на интегрированный запрос?
- Какие операции необходимы для преобразования разнотипных представлений источников, таких, например, как различные типы данных, нормализованные и ненормализованные модели, в единое интегрированное представление?
Сервер интеграции для разрешения этих вопросов использует информацию о сопоставлении. Существует несколько дополнительных влияющих на обработку интегрированного запроса факторов, которым, кроме спецификации сопоставления, необходима и другая информация:
- Какие операции поддерживаются системами, управляющими источниками данных, а какие из них требуют компенсации со стороны сервера интеграции?
- Как распределяется вклад в производительность выполнения набора операций между источниками и сервером интеграции? Какие операции сервер интеграции должен делегировать источникам для лучшего использования их возможностей и сокращения объема перемещаемых данных, а также оптимизации итоговой производительности?
Чтобы ответить на эти вопросы, необходимо иметь представление о системе источника и ее возможностях по обработке запросов. Для ответа на последний вопрос сервер интеграции должен также использовать определенную информацию об операционной среде, а также статистику базы данных источника.
После того, как сервер интеграции определит наилучшую стратегию выполнения всех подопераций, он устанавливает соединение с источниками данных - как структурированных, так и неструктурированных - чтобы получить релевантные данные; возможно, с использованием специфических для источника интерфейсов. Затем, в соответствии с общим планом выполнения запроса, подоперации выполняются в базах данных источников. Полученные результаты агрегируются в результаты интегрированного представления. Затем результаты возвращаются потребителю.
В контексте SOA потребитель передает запрос в заранее заданном формате запроса серверу интеграции. Сервер интеграции преобразует этот запрос в соответствующие запросы SQL, или определения представлений, для поддержки сервиса. Далее выполняются уже описанные выше шаги по разбиению, оптимизации и выполнению запроса. В контексте SOA отличается только заключительный этап. Сервер интеграции переводит результат традиционного подхода интеграции данных в ответ сервиса, а затем возвращает его потребителю сервиса через предварительно заданный интерфейс сервиса.
Рисунок 4. Диаграмма последовательности для интеграции данных
Функции шаблона интеграции данных могут быть реализованы либо с помощью технологий баз данных, например, оптимизатора запросов или компенсационной правки, либо самостоятельно написанных приложений. Из-за сложности оптимизации запросов для разнотипных источников, в отрасли принято использовать реализации интеграции данных, использующие технологию оптимизации запросов, предоставляемую большинством систем управления базами данных.
Что необходимо иметь в виду
Применяя шаблон интеграции данных, важно знать его особенности и то, как он взаимодействует с нефункциональными требованиями, о которых говорится ниже. Обратите внимание на то, что описываемые нами нефункциональные требования не учитывают шаблоны кэширования и репликации данных. Мы полагаем, что применение шаблонов лучше начинать с базовых шаблонов - например, с шаблона интеграции данных - которые впоследствии можно дополнить другими шаблонами для выполнения дополнительных нефункциональных требований и функций, необходимых для сервиса. Шаблоны кэширования и репликации могут использоваться для дополнения интеграции данных или при создании составного шаблона. Эти шаблоны и любые другие шаблоны, которые можно использовать в общей реализации, следует применять с осторожностью, поскольку они могут помешать выполнению некоторых нефункциональных требований, для которых первоначально и предназначался шаблон интеграции данных. Например, они могут увеличить скрытость данных и привести к созданию избыточности данных. Необходимо понимать компромиссные моменты между нефункциональными требованиями и архитектурными решениями.
Все характеристики нефункциональных требований применяются и в традиционном контексте, и в контексте SOA. Они включают следующие моменты:
Безопасность данных
Доступ к интегрированному представлению разрешается только пользователям и приложениям, имеющим соответствующие полномочия. Возможны дополнительные ограничения доступа. Одной из главных причин применения этого шаблона является использование существующих систем вместе с их данными и функциями. Как следствие, архитекторы часто стараются также использовать существующие механизмы обеспечения безопасности исходной системы, такие как аутентификация и авторизация. Вследствие разнотипного и распределенного характера этой среды могут возникнуть некоторые проблемы в отношении единого входа в систему и глобального управления доступом, которые не охватываются шаблоном интеграции данных. Чтобы решить эти проблемы, архитекторам придется комбинировать шаблон интеграции данных с другими шаблонами, имеющими отношение к системе обеспечения безопасности.
Скрытые данные
Шаблон интеграции данных обеспечивает интегрированный доступ в режиме реального времени к источникам с наибольшим уровнем актуальности данных.
Изменчивость исходных данных
Вследствие доступа к данным источника в реальном времени, сразу по получении запроса к интегрированному представлению, интеграция данных всегда возвращает самую актуальную информацию источника. Поскольку шаблон интеграции данных не создает копий данных источника, изменения источника в этом подходе не копируются и не обрабатываются.
Непротиворечивость и качество данных
С возрастанием частоты выполнения необходимых операций очистки, стандартизации и преобразования сложных данных увеличивается вероятность отрицательного воздействия на итоговое время отклика. Это происходит потому, что шаблон интеграции данных отвечает на запросы в реальном времени, синхронно. Любое дополнительное преобразование означает дополнительную рабочую нагрузку в процессе ответа на интегрированный запрос. Необходимо минимизировать сложность и количество требуемых преобразований полей.
Доступность данных
Доступность интегрированных данных зависит от доступности сервера интеграции данных и серверов интегрированных источников на момент запроса. Если один из этих серверов или любое из соединений между сервером интеграции и сервером источника не работает, интегрированное представление недоступно.
Влияние изменений модели на интегрированную модель
Весьма существенным преимуществом шаблона интеграции данных является его способность к маскировке многих изменений модели, которые могут быть реализованы в системах источников. Возможность согласования изменений на сервере интеграции может уменьшить вероятность показа этих изменений инициатору или потребителю сервиса. Впоследствии изменения могут вноситься в интегрированное представление без необходимости передачи любых изменений модели для источников данных.
Частота выполнения транзакций
Запрос к серверу интеграции выполняется в синхронном режиме. Сразу после получения ответа запросчик может вызвать следующий запрос. Сервер интеграции должен поддерживать параллельные запросы, инициированные несколькими запросчиками. Последовательные запросы, выполняемые с высокой частотой, должны иметь такие же показатели производительности, как один запрос. Исключением может стать ситуация, когда источник - или коннектор между сервером интеграции и источником - имеет особые характеристики, которые могут привести к снижению производительности при частых обращениях. Способность сервера интеграции осуществлять транзакции с высокой частотой определяется частотой, с которой сервер интеграции может обращаться к системам-источникам и способностью этих систем к отклику.
Параллельность транзакций
Во многих случаях сервер интеграции данных имеет очень сходные характеристики с сервером или базой данных, на которых размещен контент. Способность эффективно управлять параллельным доступом определяется показателями производительности сервера интеграции данных, а также интегрированных серверов-источников.
Производительность и время отклика транзакции
Время отклика для транзакции определяется многими факторами, в том числе:
- Сложностью интегрированного запроса: сколько подопераций, например, фильтраций, соединений, сортировок и т. п., должен выполнить сервер интеграции для выполнения запроса;
- Функциями оптимизации и обработки сервера интеграции данных: достаточно ли функций у проекта сервера интеграции, чтобы принять интегрированный запрос, разбить его на вложенные операции и оптимизировать, например, сначала применив некоторые из подопераций, скажем, фильтрацию, для сокращения объема набора данных, а затем другие подоперации, например, сортировку;
- Объемом данных: чем больше объем данных, тем больше времени требуется для выполнения каждой подоперации и, следовательно, на выполнение всего запроса;
- Пропускной способностью сети: пропускная способность сетевого подключения между сервером интеграции и источником определяет, насколько быстро сервер интеграции сможет обратиться к источнику а, следовательно, и общее время отклика интегрированного запроса;
- Использованием ресурсов ЦПУ: различия в использовании ресурсов компьютеров, на которых выполняются сервер интеграции и источники данных, следует, по возможности, учитывать при распределении подопераций между сервером интеграции и серверами источников;
- Возможностями обработки запроса на серверах источников: некоторые серверы источников данных имеют особые параметры и ограничения в способе обработки и оптимизации запросов, которые влияют на общую производительность;
- Способностью сервера интеграции определить оптимальную стратегию выполнения запроса для каждого источника данных: если сервер интеграции владеет информацией о возможностях обработки запроса серверов источников, то он может рассчитать, какие из вложенных операций делегировать другим серверам, а какие выполнить на уровне сервера интеграции.
Время отклика запроса к виртуальной базе данных, реализованной по шаблону интеграции данных - запрос данных из распределенных источников - может быть больше, чем того же запроса к одной физической базе данных с теми же возможностями обработки и оптимизации. Разница времен отклика будет определяться вышеперечисленными факторами. Как следствие, альтернативные шаблоны, представляющие интегрированный набор данных в одной физической базе данных, могут улучшить время отклика. Некоторые реализации шаблона интеграции данных способны передавать некоторые или все подоперации (подзапросы) системам интегрированных источников параллельно. Параллельная обработка подопераций может существенно уменьшить время отклика.
Профиль CRUD (Create-read-update-delete, создание, чтение, обновление, удаление)
Большая часть реализаций интеграции данных поддерживает различные уровни доступа для чтения и записи. Некоторые реализации координируют логическую единицу работы для операций записи; это называется двухфазной фиксацией. В большинстве случаев шаблон интеграции данных используется для доступа на чтение вследствие сложности доступа на запись. Если двухфазная фиксация не применяется, то за обеспечение непротиворечивости данных с источником при их обновлении отвечает запросчик. Поскольку для двухфазной фиксации обычно необходим диспетчер транзакций, уровень поддержки доступа для записи может быть различным в зависимости от наличия диспетчера транзакций в дополнение к функциональным возможностям сервера источника в отношении применения и фиксации изменений.
Объем данных на одну транзакцию
Время отклика зависит от объема данных, которые необходимо переместить из удаленного источника на сервер интеграции в течение одной транзакции: чем он больше, тем больше время отклика. Очень важно, чтобы сервер интеграции оптимизировал интегрированный запрос таким образом, чтобы между сервером интеграции и серверами источников передавался минимальный объем данных, особенно при значительном объеме интегрированных данных. Кроме того, важно знать возможности и пропускную способность, поддерживаемые сетевой инфраструктурой, и влияние, которое они могут оказывать на объем и частоту передаваемых данных.
Время поставки решения
Как сказано в постановке задачи, интеграция данных может существенно сократить время поставки при интеграции различных источников.
Квалификация и опыт разработчиков
Шаблон интеграции данных концентрируется на интеграции источников данных и предоставляет один образ системы через интерфейс, ориентированный на данные. При публикации интегрированной информации в виде сервиса разработчикам, кроме всего прочего, необходимо разбираться в понятиях, стандартах и технологиях SOA.
Многократность использования
Логическая схема определения обращения к данным и их агрегации может быть многократно использована в различных проектах.
Затраты на обслуживание нескольких источников данных
Интеграция данных не снижает затрат на обслуживание нескольких источников данных, но позволяет добиться существенного выигрыша благодаря интеграции и многократному использованию существующих источников данных.
Затраты на разработку
Они относительно невелики, если используются оптимальные механизмы интеграции при наличии инфраструктуры сервера интеграции
Тип целевых моделей
В этой статье описывается, главным образом, интеграция структурированных данных. Сегодня самой распространенной является реляционная модель, использующая стандарт SQL. Недавно появившиеся стандарты XML и XQuery все больше используются в сфере управления информацией. Реализации шаблона интеграции данных, как правило, поддерживают по меньшей мере одну из этих моделей, иногда обе. Большинство реализаций шаблона интеграции данных имеют относительно строгую направленность на одну или очень ограниченное число целевых моделей с целью наиболее эффективной обработки запросов.
Гарантия поставки и логическая единица работы
В ссылочной архитектуре SOA (IBM SOA Reference Architecture) основным компонентом инфраструктуры является сервисная шина корпорации (enterprise service bus, ESB). Одна из обязанностей ESB - обеспечение гарантии поставки. Вследствие сложности координации логической единицы работы, в частности, протокола двухфазной фиксации в интегрированной среде, не все реализации шаблона интеграции данных поддерживают эту функцию. При использовании поддерживающих ее серверов интеграции необходимо подвергать тщательному анализу стратегии блокировок баз данных во избежание отрицательного влияния на производительность систем источников.
Использование ресурсов
Сервер интеграции использует ресурсы только при обработке запроса, который он получает от потребителя. Уровень использования ресурсов на сервере интеграции определяется также сложностью запроса: чем сложнее запрос, тем сложнее задача нахождения оптимального плана разбиения этого интегрированного запроса на отдельные операции. Еще один фактор использования ресурсов - это процент подопераций по запросу, которые необходимо выполнить на сервере интеграции (например, чтобы компенсировать отсутствующие функции на системах источников) по отношению к числу подопераций, которые могут быть переданы на выполнение системам источников. Кроме того, на использование ресурсов влияет объем данных, получаемых из систем источников и проходящих через сервер интеграции.
Функции преобразования
Главная цель шаблона интеграции - оставить данные на своих местах и предоставить потребителю виртуальное интегрированное представление в режиме реального времени. Принцип решения в этом шаблоне не имеет никаких ограничений в смысле применения преобразований. Во многих реализациях используются базовые преобразования для приведения несопоставимых форматов источников в общее представление на уровне интеграции данных. Однако сложные преобразования оказывают отрицательное влияние на производительность шаблона интеграции, в результате чего возможно лишь ограниченное применение данного шаблона в таких сценариях. Поэтому большинство реализаций шаблона интеграции данных в меньшей степени используют сложные функции преобразования и в большей степени технологии оптимизации запросов.
Типы модели, интерфейсов, протоколов источника
Интеграция данных решает проблему объединения данных из разнородных исходных моделей и включает способы приведения таких различных исходных моделей к одной общей модели на уровне интеграции. Возможности реализаций шаблона интеграции данных по интеграции различных конкретных исходных моделей различны.
Объем и размер исходных моделей
Размер исходных моделей, количество и тип атрибутов может оказывать отрицательное влияние на задачу сопоставления данных во время выполнения при отображении основного источника на интегрированное представление. Чем подробнее модель, например, чем к большему количеству атрибутов необходимо обратиться, тем больше времени потребуется на идентификацию соответствующих элементов.
Влияние рабочей нагрузки (объема транзакции) сервера интеграции на источники
Для каждого полученного запроса сервер интеграции передает подоперации системам источников. Это отрицательно влияет на использование ресурсов в системе источников вследствие того, что они должны ответить на полученные от сервера интеграции подоперации. Чем больше запросов получает сервер интеграции, тем больше подопераций будет отправлено интегрированным источникам.
Заключение
Мы рассказали о шаблоне интеграции данных как о принципе работы с данными по отношению к интегрированному и временному (виртуальному) представлению, данные которого реально хранятся в нескольких различных источниках. В данной статье мы сконцентрировались, главным образом, на контексте SOA. В завершение мы обобщим ситуации, в которых следует и не следует использовать шаблон интеграции данных, и перечислим важные ограничения.
Основные области применения шаблона интеграции данных
- Когда одним из основных приоритетов разработки является время от начала разработки до выхода на рынок, интеграция данных предлагает быстрый доступ к источникам информации, не требуя длительного внесения изменений в инфраструктуру управления информацией;
- Интеграция данных поддерживает требования в отношении репликации и дублирования данных, делая возможным обращение к данным в том виде, в каком они находятся в источнике. Эти требования могут быть субъектами законодательных и прочих ограничений на перемещение и репликацию данных, например, данных о подписке и объединении личной информации из разных источников в различных странах;
- Доступ к распределенной информации как к информации из одного источника в реальном времени. Информация может включать как структурированные, так и неструктурированные данные;
- Гибкий и расширяемый подход к интеграции информации для динамически изменяющейся среды, в частности, при развитии схемы: из-за отсутствия избыточности данных изменения в схеме интеграции уменьшают влияние изменений в интегрированных системах;
- Преимущества интеграции используются наилучшим образом, если к ограниченному результирующему набору, составленному из данных от нескольких непротиворечивых, взаимодополняющих источников данных, выполняется ограниченное количество запросов.
Области риска в применении шаблона интеграции данных
- При этом подходе сценарии интеграции, требующие для построения интегрированного представления сложных преобразований, будут особенно отрицательно влиять на время отклика;
- На серверы источников может оказывать отрицательное влияние увеличение рабочей нагрузки из-за необходимости возврата данных в ответ на интегрированные запросы. Для обработки запроса к интегрированному представлению сервер интеграции отправляет подоперации интегрированным источникам. Чем сложнее эти подоперации и чем чаще они передаются источникам, тем большей рабочей нагрузкой приходится управлять серверам источников;
- Сценарии, в результате которых с целевого источника данных на сервер интеграции перемещаются крупные промежуточные результирующие наборы, могут существенно влиять на производительность;
- Ситуации, при которых приложениям необходима сравнительно высокая степень доступности интегрированных данных, не подходят для применения этого шаблона. Доступность интегрированных данных полностью зависит от доступности всех интегрированных серверов и серверов источников, участвующих в этом процессе, а также от доступности, пропускной способности и реактивности сети.
Ограничения применения шаблона интеграции данных
- Многие реализации шаблона интеграции данных имеют ограниченные функции манипуляции с данными. Многие из них используют в качестве языка программирования SQL и способны поддерживать только преобразования SQL;
- Производительность в значительной степени зависит от сложности реализации конкретного производителя в смысле возможностей кэширования, умения работать с различными источниками данных и формировать оптимальные интегрированные запросы и планы выполнения;
- Доступ для чтения-записи к различным источникам информации - в частности, при координировании логической единицы работы - ограничен поддержкой этих функций реализацией конкретного производителя.