Введение
XML позволяет использовать произвольные теги и элементы разметки для описания содержимого документов. Благодаря данному преимуществу XML стал де-факто стандартом для использования в приложениях, занимающихся обменом данными, специфичными для той или иной области. В частности, новостные агентства зачастую используют NITF (News Industry Text Format) - набор XML-элементов, позволяющих определять структуру и описывать содержимое новостных статей в виде документов XML, а также облегчающих их распространение и обмен.
NITF - это открытый стандарт, широко используемый некоторыми крупнейшими мировыми агентствами новостей. Он разработан и в настоящее время поддерживается Международным советом по прессе и телекоммуникациям (International Press Telecommunications Council - IPTC). Для облегчения работы с данным форматом был создан PHP-пакет XML_NITF, который можно найти в PHP Extension and Application Repository (PEAR). С помощью XML_NITF API можно извлекать содержимое различных элементов из файлов в формате NITF и далее использовать его в приложениях на PHP. Таким образом, пакет представляет собой надежный и простой в использовании инструмент для любых PHP/NITF-приложений.
Установка
XML_NITF, поддерживаемый Патриком О"Лоуном (Patrick O'Lone), был выпущен под лицензией PHP. Для его корректной работы требуется PHP версии не ниже 4.3.0. Пакет проще всего установить с помощью автоматического инсталлятора PEAR, который по умолчанию включен в поставку PHP. Для установки XML_NITF просто выполните следующую команду из командной строки:
shell> pear install XML_NITF
Инсталлятор PEAR должен соединиться с сервером пакетов PEAR, загрузить XML_NITF и установить его в соответствующее место на диске. В данной статье используется XML_NITF V. 1.1.0.
Пакет можно также установить вручную. Для этого скачайте архив с исходным кодом со страницы проекта и распакуйте в любую папку в вашей системе. Подобная ручная установка требует определенного представления о структуре пакетов PEAR.
Перед XML_NITF необходимо установить еще один PEAR-пакет, а именно XML_Parser. Он также может устанавливаться автоматически, как описано выше, или же вручную.
О формате NITF
Для работы с XML_NITF необходимо иметь базовое представление о формате NITF. Обратите внимание на пример простого документа NITF, приведенный в листинге 1:
Листинг 1. Пример документа NITF
<?xml version="1.0"?>
<nitf>
<head>
<title>Life Discovered on Mars</title>
<docdata management-status="usable" management-doc-idref="jf83820r">
<doc-id id-string="jf83820r" />
<urgency ed-urg="1" />
<date.issue norm="20100929T0000+0530" />
<date.release norm="20100929T0000+0530" />
<date.expire norm="20101029T0000+0530" />
<doc.copyright year="2010" holder="The World Times" />
<key-list>
<keyword key="mars"/>
<keyword key="space"/>
<keyword key="alien"/>
<keyword key="science"/>
</key-list>
</docdata>
<pubdata type="print" name="The World Times"
date.publication="20100929T0000+0530" />
</head>
<body>
<body.head>
<hedline>
<hl1>Life Discovered on Mars</hl1>
<hl2>But Is It Friendly?</hl2>
</hedline>
<byline>
By <person>John A. Doe</person>
</byline>
<abstract>
<p>Readings from the Mars probe confirm intelligent life.</p>
</abstract>
</body.head>
<body.content>
<p>Today, scientists from <org value="NASA" idsrc="NASA01">NASA</org>
's Elemental project announced
that the space probe sent to Mars has sent back
readings to earth conclusively identifying
the presence on intelligent life on the planet.</p>
<p>Some of the data sent back makes for
exciting reading...</p>
<media media-type="image">
<media-reference mime-type="image/jpeg" source="photo1.jpg"
alternate-text="Photo of crystalline structures on Mars.">
</media-reference>
<media-caption>
Photo of crystalline structures on Mars.
</media-caption>
</media>
</body.content>
</body>
</nitf>
|
Любой документ в формате NITF состоит из двух главных разделов:
- Секции
<head>, содержащей метаданные, описывающие новостную статью - Секции
<body>, содержащей сам текст статьи
Каждый из разделов в свою очередь делится на подразделы. Например, как показано в листинге 1, элемент <body> содержит элементы <body.head>, включающий в себя заголовок статьи, резюме и имя автора, и <body.content>, внутри которого помещено само содержимое статьи вместе со ссылками на рисунки и прочей второстепенной информацией. Похожим образом в разделе <head> содержатся элементы, описывающие такие метаданные, как владелец прав на статью, номер выпуска, дату истечения и ключевые слова.
Необходимо отметить, что в листинге 1 показан далеко не полный перечень элементов, определенных в спецификации NITF. Это не более чем простой пример, специально созданный для облегчения понимания формата теми, кто не имеет опыта использования NITF.
Доступ к базовой информации
Создав документ в формате NITF, можно начать использовать XML_NITF, обеспечивающий простой доступ ко всей содержащийся в документе информации. PHP-скрипт для извлечения заголовка, имени автора и самого содержимого статьи показан в листинге 2:
Листинг 2. PHP-скрипт, извлекающий заголовок и содержимое документа в формате NITF
<?php
// включение класса
include 'XML/NITF.php';
// инициализация экземпляра класса
$nitf =& new XML_NITF();
// разбор документа XML
$nitf->setInputFile("mars.xml");
$nitf->parse();
?>
<html>
<head>
<title><?php echo $nitf->getHeadline(); ?></title>
</head>
<body>
<h2><?php echo $nitf->getHeadline(); ?></h2>
<h4><?php echo $nitf->getByline(); ?></h3>
<?php
foreach ($nitf->getContent() as $para) {
echo '<p>' . $para . '</p>';
}
?>
</body>
</html>
|
Скрипт в листинге 2 использует пакет XML_NITF для чтения документа NITF, показанного выше в листинге 1, и трансформирует его содержимое в страницу HTML, отображаемую любым Web-браузером. Вначале скрипт инициализирует экземпляр класса XML_NITF путем обращения к соответствующему файлу. Далее вызывается метод setInputFile() данного класса, который принимает в качестве параметра местонахождение документа NITF. Затем происходит разбор документа внутри метода parse(), который использует SAX-парсер PHP. Как только документ разобран, вызываются методы getHeadline() и getByline(), возвращающие заголовок статьи и имя автора соответственно. Само содержимое статьи извлекается с помощью метода getContent(), который возвращает его в виде массива абзацев. Наконец, PHP-цикл foreach() перебирает абзацы и форматирует их в виде HTML.
Вывод листинга 2 показан на рисунке 1:
Рисунок 1. Web-страница, созданная на основе документа NITF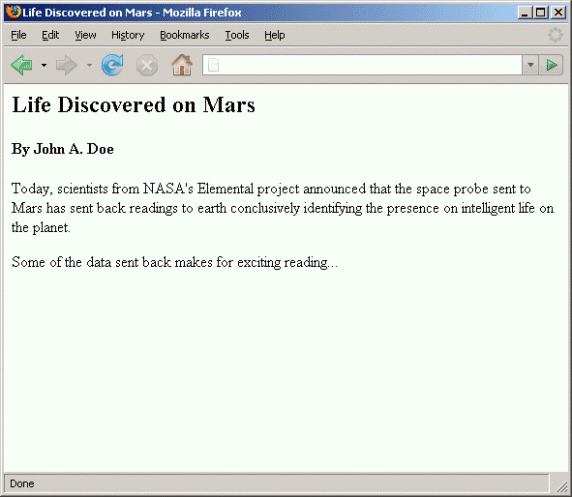
Извлечение дополнительной информации
Пакет XML_NITF также предоставляет методы для извлечения метаданных, в частности, содержимого элементов <docdata> и <pubdata>, находящихся внутри элемента <head>. Кроме этого, можно получать доступ к любым медиа-данным, связанным со статьей. Пример использования данных методов показан в листинге 3:
Листинг 3. PHP-скрипт, извлекающий метаданные из документа NITF
<html>
<head></head>
<body>
<pre>
<?php
// включение класса
include 'XML/NITF.php';
// инициализация экземпляра
$nitf =& new XML_NITF();
// разбор XML
$nitf->setInputFile("mars.xml");
$nitf->parse();
// печать метаданных
echo "Document data:\n";
foreach ($nitf->getDocData() as $k=>$v) {
if (is_array($v)) {
echo "\t$k: " . implode(' ', $v) . "\n";
} else {
echo "\t$k: $v\n";
}
}
echo "\n";
// печать издательской информации
echo "Publication data:\n";
foreach ($nitf->getPubData() as $k=>$v) {
if (is_array($v)) {
echo "\t$k: " . implode(' ', $v) . "\n";
} else {
echo "\t$k: $v\n";
}
}
echo "\n";
// печать медиа-информации
echo "Media attached to the article:\n";
foreach ($nitf->getMedia() as $m) {
foreach ($m as $k=>$v) {
echo "\t$k: $v\n";
}
echo "\n";
}
?>
</pre>
</body>
</html>
|
В листинге 3 показано, как использовать три важных метода:
getDocData(), который возвращает содержимое элемента<docdata>в качестве набора пар типа "ключ-значение"getPubData(), который делает тоже самое, но применительно к элементу<pubdata>getMedia(), который возвращает массив элементов<media>, определенных в теле статьи
Во всех трех случаях, возвращаемое значение методов обрабатывается внутри цикла foreach(). Вдобавок, можно обращаться к отдельным значениям по ключам.
Вывод листинга 3 показан на рисунке 2:
Рисунок 2. Вывод метаданных с помощью скрипта в листинге 3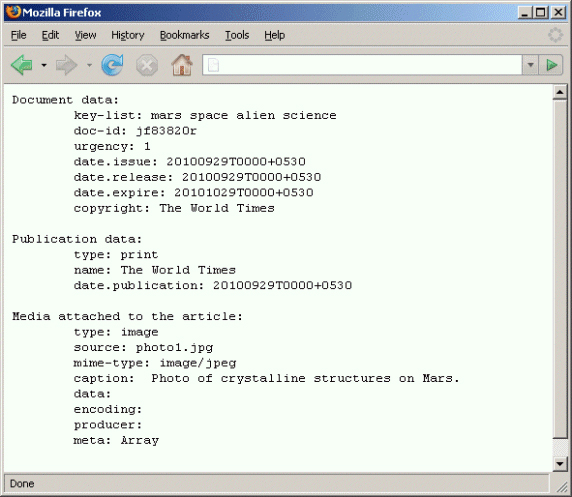
Как видно из примеров, пакет XML_NITF предоставляет удобные средства для простого доступа к нужным фрагментам новостных статей, представленных в формате NITF. Попробуйте применить данный пакет в следующий раз, когда вам придется иметь дело с NITF, и составьте свое мнение о нем.