Технологии связанных данных эффективно объединяют множество наборов данных в один. Теперь, когда вам известна модель данных Resource Description Framework (RDF), а также протокол SPARQL и язык запросов RDF (SPARQL), мы рассмотрим, как объединить эти стандарты с веб-архитектурой для создания и использования легко потребляемых взаимосвязанных данных.
Принципы связанных данных
Призывая к согласованности способов публикации данных в Интернете, Тим Бернерс-Ли определил четыре принципа связанных данных:
- Использование в качестве имен универсальных идентификаторов ресурсов (URI).
- Использование URI в формате HTTP, чтобы эти имена можно было искать.
- Предоставление тем, кто ищет URI, полезной информации с использованием стандартов (RDF*, SPARQL).
- Включение ссылок на другие URI, чтобы можно было находить больше вещей.
Об этой серии статей
Эта серия статей посвящена исследованию и применению глобальных стандартов, относящихся к решению задач крупномасштабной интеграции данных, ежедневно встающих перед разработчиками, архитекторами и администраторами данных. Кроссплатформенные технологии, не зависящие от языка и приложений, описанные в этих статьях, способствуют интеграции информации в базах данных, документах, электронных таблицах и API-интерфейсах различных сервисов. Модели данных и инструменты, о которых вы узнаете, могут облегчить вашу работу и оказать существенное влияние на вашу организацию.
На данном этапе этой серии публикаций мотивация этих принципов не требует объяснений, но для ясности я все же кратко ее изложу.
Во-первых, цель системы именования - делать ссылки в общедоступном контексте. Эти ссылки должны быть согласованными, недвусмысленными и бесконфликтными. Стандарт URI дает такую схему именования: схему создания систем имен. Зная, как анализировать, представлять и хранить URI в своей системе, можно принимать идентификаторы из любых других систем, если они созданы с соблюдением стандарта. Такие системы могут включать уже написанный и развернутый код, который принимает ссылки на будущие, новые стандартизованные имена URI.
Имена URN
Использование URI не означает, что для Semantic Web номера ISBN бесполезны. Uniform Resource Name (URN) - это тип URI, который позволяет отображать внешнюю схему имен на пространство URI с помощью префикса пространства имен. У книги может быть следующий URN: urn:isbn:978-1608454303.
Существуют и другие глобальные системы имен. Общепринятая схема - это Международный стандартный номер книги (ISBN). Номера ISBN долгие годы играли решающую роль для стандартизации ссылок на книги. Успех этой схемы объясняется главным образом тем, что поддержка системы имен позволила сократить расходы и количество ошибок для рынков издания и распространения книг. К сожалению, ISBN относится только к книгам. У журналов, музыкальных партитур и аудиовизуальной продукции (кинофильмы, телевизионные программы, трансляции спортивных событий) свои схемы идентификаторов. Тематику книг можно указать с помощью схемы иерархической классификации, такой как система десятичной классификации Дьюи, но это еще одна несовместимая система идентификаторов. Ученых можно идентифицировать с помощью идентификаторов ORCID, но у прикладных специалистов такой системы нет. Таким образом, чтобы указать, что конкретная (академическая) книга написана конкретным ученым на известную тему, нужно использовать не просто три разных идентификатора, а три разные схемы! Стандартная схема ссылок на все эти вещи явно имеет смысл.
Обратите внимание, идея Бернерса-Ли не в том, что все должны использовать одни и те же коды URI. Базовое взаимодействие достигается просто с помощью стандарта URI. Хорошо, когда люди достигают соглашения о том, как называть вещи, но это не обязательно. Это верно как для идентификаторов узлов, так и для идентификаторов связей в RDF-графах.
Во-вторых, несмотря на то, что любая URI-совместимая система может использовать ссылку на идентификатор URI во внешнем наборе данных, пользователи этой системы могут не распознать идентификатор. Для незнакомых идентификаторов требуют средства поиска того, на что они указывают. Чтобы узнать что-нибудь о названной сущности, потребляющая система должна знать о такой службе или иметь средства обнаружить ее. В результате число зависимостей и связей, которые приложение-потребитель должно поддерживать для использования определенных схем имен, увеличивается.
Второй принцип несет в себе огромную ценность для обмена данными. Если система может потреблять URI и если это разрешимые URI (URL), то их можно рассматривать как любой другой веб-ресурс и обращаться к ним с запросами GET - чтобы узнать больше о том, к чему они относятся. Не нужно придумывать никакой специальной службы и нет никаких новых зависимостей, помимо HTTP и его единого интерфейса. Имя является идентификатором и дескриптором, по которому можно узнать больше.
Третий принцип уточняет, что если обеспечить стандартную сериализацию стандартных моделей данных - в дополнение к любым другим специальным форматам, которые вы хотите получить при анализе своих ресурсов, - то для разбора результирующей структуры анализирующей системе не нужно знать ничего другого. Система может не знать, каковы идентификаторы, но - согласно второму принципу - всякий раз, когда хочет узнать больше, сможет различить их. В дополнение к стандартным форматам сериализации поддержка стандартных механизмов запросов, таких как SPARQL Protocol, позволяет клиентам задавать вопросы о ваших данных.
"Связанные данные - это принципиально иной подход, который работает при уровнях производительности, масштаба и гибкости, которые трудно себе представить, если все, что вы когда-либо имели в своем распоряжении - это решения уровня предприятия, зависящие от языка программирования. "
Так как первый принцип не требует использования стандартных идентификаторов - а только стандартный схемы идентификаторов, - это гарантирует, что в разных наборах данных одним и тем же вещам будут присвоены разные имена. Эту проблему можно решить многими способами, но я не буду вдаваться в детали. Общий подход состоит в том, чтобы использовать семантические отношения более высокого порядка, например, owl:sameAs из языка Web Ontology Language (OWL), чтобы отождествлять идентификаторы на постоянной основе. Тогда для запросов к любым эквивалентным ресурсам можно использовать любую систему аргументации, которая понимает семантику OWL, и получать их свойства. Основные моментом здесь является то, что такие механизмы обеспечивают способы соединения своих терминов с другими. Это обогащает данные и помогает поддерживать возможности поиска между наборами данных.
В целом эти принципы применимы как к общедоступным так и к частным данным. Не надо думать, что все эти технологии применимы только к бесплатным, публичным данным, которыми можно делиться со всеми. В конце концов, все это веб-ресурсы, и их можно разместить за межсетевым экраном, механизмом оплаты и моделями авторизации и проверки подлинности. Цель состоит в том, чтобы решить многие проблемы соединения информации между различными источниками данных с помощью технологий, которые работают на больших масштабах. Достижение этой цели помогает снизить стоимость интеграции почти до нуля по сравнению с более дорогими, хрупкими и трудоемкими технологиями, не основанными на сетевых стандартах.
Чтобы увидеть эти идеи в действии, достаточно рассмотреть проект сообщества Linking Open Data.
Проект Linking Open Data
В 2007 году небольшая группа людей - проект сообщества Linking Open Data (LOD) - взялась за соединение ряда общедоступных наборов данных. На рисунке 1 представлены первые 12 наборов данных, связанных между собой - включая информацию DBpedia, GeoNames и US Census.
Рисунок 1. Облако проекта Linking Open Data в 2007 году
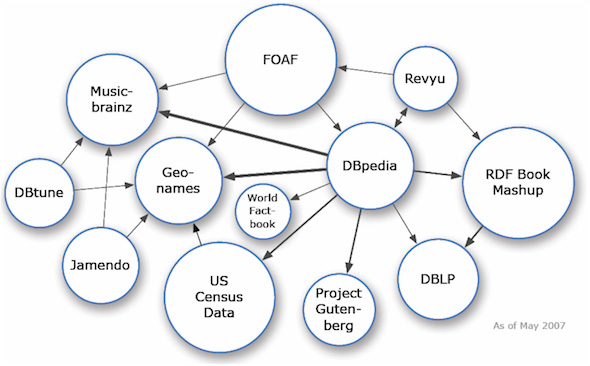
Ниже я расскажу о DBpedia подробнее. Пока же начнем с того, что в DBpedia есть информация из Википедии по теме Оберн, штат Калифорния. Другую информацию об Оберне можно найти в 2000 U.S. Census и в проекте GeoNames. Эти три набора данных используют разные идентификаторы для одного и того же (Оберн), но немного покопавшись под капотом, можно обнаружить, что для установления связи между терминами DBpedia использует OWL sameAs. Теперь для запроса данных через механизм рассуждений OWL и извлечения всех результатов можно использовать любой из трех терминов. (Опять же то, как и почему это работает, выходит за рамки настоящей статьи.)
В листинге 1 URI Оберн из проекта GeoNames приравнивается к ресурсу об Оберне в контексте DBpedia на английском языке. Затем я подключаю к ресурсу DBpedia идентификатор Оберна из Freebase. Наконец, я подключаю к английскому контексту идентификатор Оберна из контекста DBpedia на японском языке. Теперь все четыре имени приравнены друг к другу. Триады, указанные в качестве предмета любым из них, теперь верны для них всех.
Листинг 1. Соединение идентификаторов с помощью OWL
Следует помнить, что это наборы данных из разных организаций, не обязательно произведенные членами проекта LOD. Но они выражены с использованием стандартов, что делает возможным получение данных, доступных широкому кругу клиентов. Некоторые данные хранятся в RDF-файлах, другие - в хранилищах триад, а третьи - в реляционных базах данных и при необходимости отображаются как RDF. Использование технологий связанных данных обычно не обременительно для источников информации. Эти технологии - всего лишь проводники для получения информации и простого ее соединения с родственным контентом. Связь между наборами данных можно присоединить к остальному контенту или хранить отдельно в наборе ссылок .
Из предыдущей статьи вы знаете, что посредством SPARQL можно получать информацию из нескольких источников данных одновременно, просто обращаясь к ним с ключевым словом FROM. Теперь можно оставить источники данных нетронутыми, а хранить в файле связи между идентификаторами, как в листинге 1, и в запросе SPARQL обращаться к этому набору ссылок, как в листинге 2. В этом запросе связь между терминами в каждом из источников данных будет включена в граф и доступна для интеграции на основе механизма рассуждений.
Листинг 2. Запрос SPARQL с наборами данных и наборами ссылок
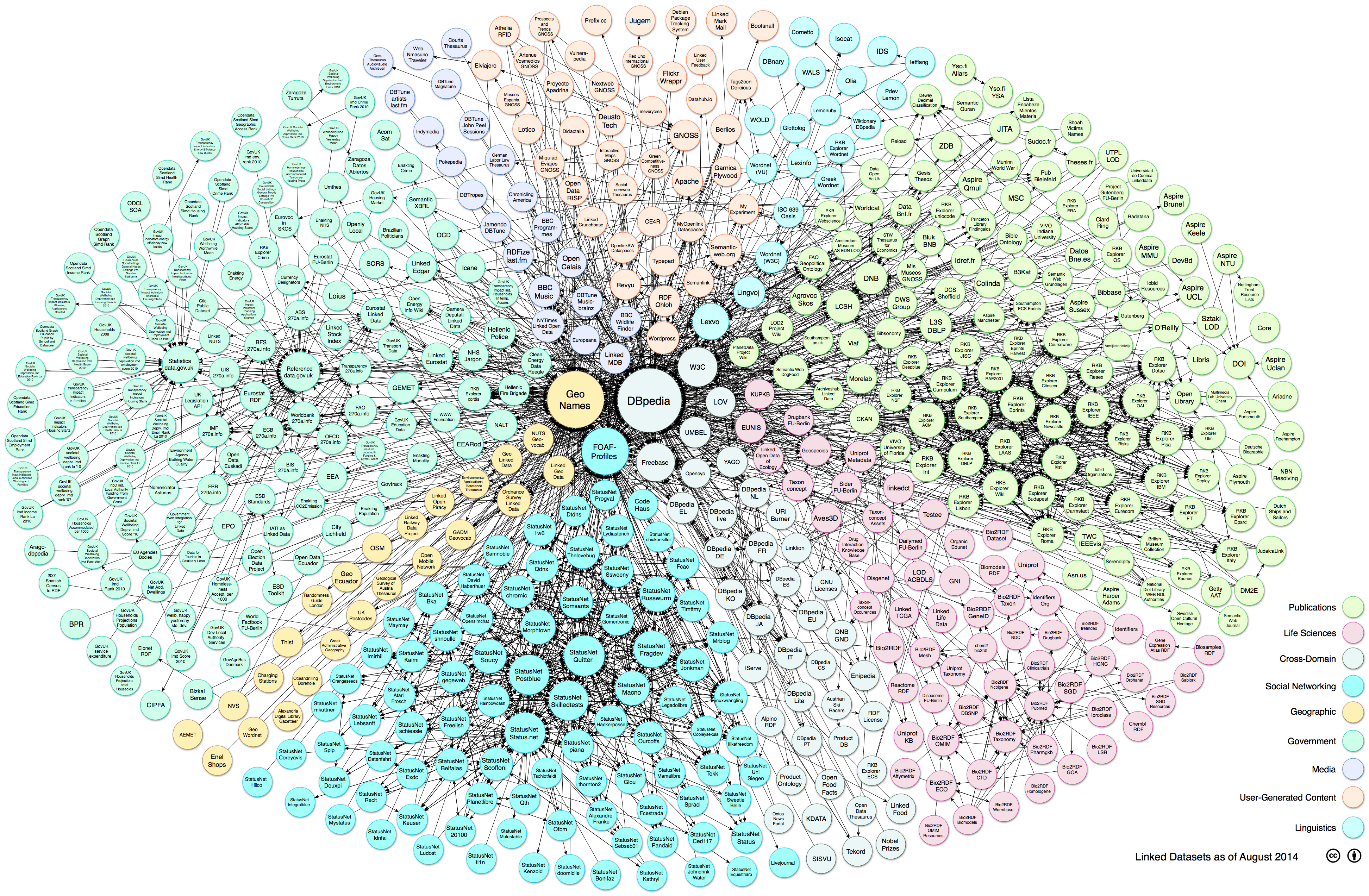
Таким образом были связаны первые 12 наборов данных проекта LOD. Затем к ним добавились другие. Потом еще. Проект добавил новые классы наборов данных, включая цитирование научных исследований; науки о жизни; данные госучреждений; информацию об актерах, режиссерах, кинофильмах, ресторанах и многое другое. К 2014 году были связаны 570 наборов данных, представляющих миллиарды триад RDF. Итоговая схема облака LOD по состоянию на 2014 год приведена на рисунке 2. Еще интереснее изучать интерактивную версию в браузере с поддержкой SVG. Нажимая на большую часть отдельных наборов данных, вы попадаете на соответствующие страницы Datahub.
Схемы облака LOD
Схемы LOD публикуются по лицензии CC-BY-SA и доступны из разных исторических этапов облака. Схема облака Linking Open Data 2014 года Макса Шмахтенберга, Кристиана Брайзера, Анжея Йенцсха и Ричарда Сиганьяка.
Рисунок 2. Облако проекта LOD в 2014 году
Многие из этих наборов данных описаны с помощью RDF-словаря для описания взаимосвязанных данных: Vocabulary of Interlinked Datasets (VoID). Кто создал эти наборы? Когда они изменялись в последний раз? Как они велики? Где найти ссылки для их соединения с другими данными? Описание VoID отвечает на все эти вопросы.
Давайте углубимся в один из этих источников данных: DBpedia. DBpedia - одна из первых попыток предоставления структурированных метаданных из Википедии. VoID-описание DBpedia будет содержать метаданные, такие как в листинге 3.
Листинг 3. Пример VoID-описания из DBpedia
Из этого описания следует, что DBpedia - это данные, извлеченные из Википедии. Хотя большая часть содержания Википедии не структурирована, сайт включает в себя значительную часть редакционно-управляемой структуры. В частности, инфобоксы в статьях стандартизованы, и их информацию легко извлекать хорошо структурированными способами. Как следствие, более 12,6 млн предметов однозначно описаны с применением 2,5 млрд RDF-триад из 119 локализованных языковых контекстов, в том числе:
- 830 000 персон
- 640 000 мест
- 370,000 художественных произведений
- 210 000 организаций
- 226 000 видов животных и растений
- 5600 заболеваний
Каждый из этих предметов представляет собой ресурс со своим собственным разрешимым идентификатором. При оценке масштабов и разнообразия указанных тем помните, что этот многодоменный набор данных поддерживается и курируется добровольцами. Он включает в себя 25 млн ссылок на изображения, 28 млн ссылок на документы и 45 млн ссылок на другие наборы данных RDF. Почти три четверти ресурсов классифицированы по нескольким онтологиям.
У каждого из этих ресурсов есть логический идентификатор, HTML-страница и прямая ссылка RDF/XML-сериализацию:
Если проследовать по ссылке на логический ресурс, то вы будете перенаправлены на HTML-представление. Это происходит потому, что при нажатии на эту ссылку браузер запрашивает ответ с указанием в качестве предпочтительного источника HTML. И сервер DBpedia перенаправляет вас на визуализированную форму. Там можно найти связи Оберна с родственными ресурсами, такими как городская газета, округ в котором он находится, и его знаменитости.
Все эти URI представляют собой ссылки на ресурсы, и каждый ресурс описан с помощью RDF из Википедии. То, что вы видите, нажав на ссылку, это не веб-страница данного ресурса, а HTML-отрисовка данных RDF. Например, у Auburn Journal есть своя собственная веб-страница, которую можно найти, отправившись с ресурса газеты по ссылке http://dbpedia.org/ontology/wikiPageExternalLink.
Я упоминал, что большая часть ресурсов DBpedia классифицирована по нескольким онтологиям. Конкретно это означает, что ресурсы представляют собой экземпляры классов, которые также являются RDF-ресурсами. Если внимательно посмотреть на страницу ресурсов Оберна, то можно увидеть, что это rdf:type из нескольких классов, в том числе:
- http://www.w3.org/2003/01/geo/wgs84_pos#SpatialThing
- http://schema.org/City
- http://dbpedia.org/class/yago/CitiesInPlacerCounty,California
- http://dbpedia.org/class/yago/CountySeatsInCalifornia
Обратите внимание, что это разные классы из разных схем. Легко догадаться, как можно в любое время добавлять новые категории, устанавливая новые отношения экземпляра rdf:type со всем, что имеет смысл. Однако это отношение членства в наборе. То есть можно спрашивать обо всем, что входит в этот набор (или является экземпляром этого класса). Если отправиться по ссылке на категорию http://dbpedia.org/class/yago/CitiesInPlacerCounty,California, то можно увидеть другие города округа Placer County, включая Лумис, Роклин и Роузвиль. Здесь вы видите набор связанных городов, основанный на отношении вложенности как частей одного и того же округа.
Класс http://dbpedia.org/class/yago/CountySeatsInCalifornia включает в себя гораздо больший набор. Здесь классифицированы главные города округов штата Калифорния, и к ним можно переходить через отношения к другим, о которых вам известно. Навигация по ссылкам эффективно осуществляется с помощью неявных запросов SPARQL, обрабатываемых за кулисами. Вот эквивалентный запрос:
Так как DBpedia поддерживает протокол SPARQL, о котором я писал в предыдущей статье, этот запрос можно превратить в прямую ссылку. Вот расширенная форма:
Теперь объединим некоторые вещи, которые я показал вам, в новый запрос:
Добавим к предыдущему запросу еще одно отношение. Теперь мы просим: "Показать все главные города округов штата Калифорния и связанные с ними внешние веб-страницы". Это мощный запрос, позволяющий автоматически объединять данные, извлекаемые из Википедии. Его результаты можно увидеть здесь.
Теперь внесем в запрос одно простое изменение. Вместо ресурсов, которые являются членами класса http://dbpedia.org/class/yago/CountySeatsInCalifornia, используем http://dbpedia.org/class/yago/CapitalsInEurope:
Результаты здесь. Ничего не изменилось, кроме того, что теперь результаты отражают внешние веб-страницы, связанные со столицами стран на Европейском континенте!
Если изменить искомое отношение к ресурсам, классифицированным подобным образом, то можно задать совершенно другой вопрос. Этот запрос, вместо внешних ссылок, дает информацию о широте и долготе:
Результаты здесь.
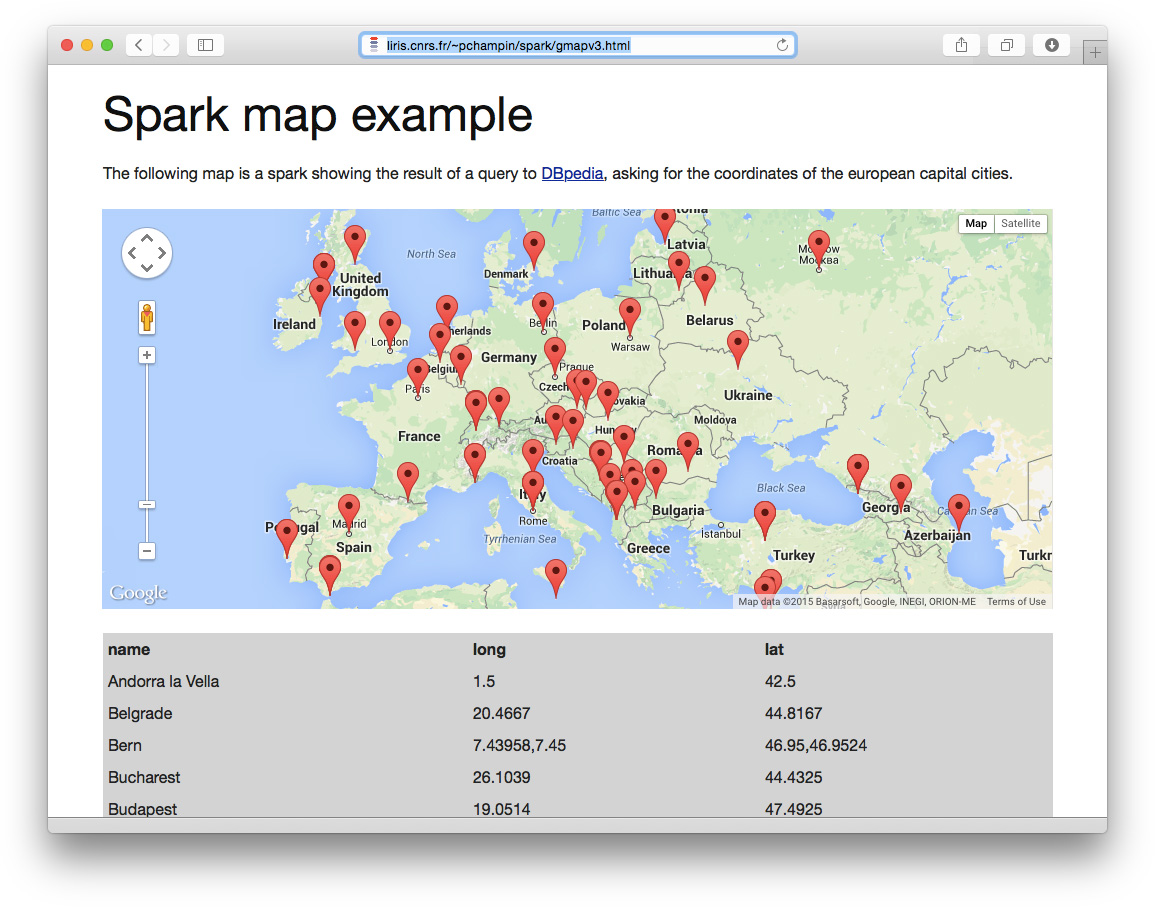
Нетрудно представить себе получение информации в ответ на такой запрос и ее отображение на карте Google Maps. Результат этого показан на рисунке 3, а взаимодействовать с этим результатом можно здесь. Подумайте о том, как много кода пришлось бы изменить, чтобы найти и визуализировать места рождения всех глав государств европейских стран. (Подсказка: очень много.)
Рисунок 3. Европейские столицы из DBpedia
Теперь, когда мы знаем механику, не трудно представить, как задавать другие вопросы на произвольные темы. Мой любимый запрос к DBpedia (который мне предложил Боб Дюшарм) - найти все приколы на школьной доске из всех эпизодов "Симпсонов". Отправившись по этой ссылке, имейте в виду, что каждый эпизод также является ресурсом, который содержит ссылки на режиссера эпизода, особых гостей, героев и т.п. Каждый эпизод классифицируется как член набора телевизионных программ определенного года выпуска. Следуя по ссылкам, относящимся к этим классам, можно найти другие телевизионные эпизоды, которые выходили в эфир примерно в то же время.
Так что предела разнообразию вопросов, которые можно задавать DBpedia, не существует. И имейте в виду, что DBpedia - лишь один из почти 600 наборов данных, которые входят в облако LOD. Связанные данные дают впечатляющие результаты при относительно малом количестве усилий.
Заключение
Подумайте о том, как много времени уходит у вашей организации на то, чтобы интегрировать каждый новый источник данных. Связанные данные - это принципиально иной подход, который работает при уровнях производительности, масштаба и гибкости, которые трудно себе представить, если все, что вы когда-либо имели в своем распоряжении, - это решения уровня предприятия, зависящие от языка программирования. Ничто в этом подходе не ограничивает его применимости и к общедоступным данных. Те же идеи легко использовать за пределами межсетевого экрана.
Фрагменты связанных данных
Для решения задачи надежных запросов к связанным данным одна группа предложила новый подход, называемый фрагментами связанных данных (Linked Data Fragments). Это пока не стандартный подход, но он несет в себе много полезных идей, с которыми я советую вам ознакомиться.
Связанные данные - это не магия. Стандартные идентификаторы, разрешаемые путем стандартной сериализации стандартных моделей данных, - это простой (хотя, возможно, и не интуитивно понятный) набор концепций. Однако с технической точки зрения поддержка протокола SPARQL в открытом Интернете - невероятно трудное дело. Трудно предсказать, какие виды нагрузок на ваши серверы будут исходить от случайных людей. В работу DBpedia вкладываются значительные усилия.