По материалам статьи Craig Freedman: Introduction to Parallel Query Execution
SQL Server умеет выполнять запросы одновременно на нескольких процессорах. Такую возможность принято называть параллельным исполнением запроса. Параллельное исполнение запроса может использоваться для сокращения времени отклика (то есть, повышение быстродействия) больших запросов. Оно также может использоваться и при исполнении больших запросов (которые обрабатывают большой объём данных) в одно и то же время с маленькими запросами (масштабирование), увеличивая число процессоров, используемых в обслуживании запроса. Для большинства больших запросов SQL Server масштабируется практически линейно или почти линейно. Повышение быстродействия тут означает, что если мы удваиваем число процессоров, мы можем наблюдать сокращение времени отклика тоже в два раза. Масштабирование тут означает, что если мы удваиваем число процессоров и размер запроса, мы получает то же самое время отклика.
Как я уже отметил выше, параллелизм может использоваться для сокращения времени отклика одного запроса. Однако, параллелизм влияет на стоимость: она увеличивается за счёт увеличения накладных расходов на исполнение запроса. Несмотря на то, что эти накладные расходы невелики, параллелизм не желателен для маленьких запросов (особенно для OLTP -запросов), для которых такой "довесок" будет соразмерим с полным временем исполнения. Кроме того, если мы сравним время исполнения одного и того же маленького запроса в режиме параллельного исполнения на двух процессорах или последовательного исполнения (без параллелизма, на одном процессоре), для таких запросов будет типично более длительное исполнение распараллеленного запроса, причём, почти в два раза дольше. Опять же, это объясняется сравнительно большой долей накладных расходов на параллелизм для маленьких запросов.
В первую очередь параллелизм полезен для тех серверов, которые выполняют относительно небольшое число параллельных запросов. Для таких серверов, параллелизм может предоставить возможность маленькому числу запросов утилизировать большое число процессоров. Для серверов с большим числом параллельных запросов (например, OLTP), необходимость в параллелизме меньше, поскольку все процессоры и так будут утилизированы; просто потому, что у системы достаточно много для этого запросов. Распараллеливание этих запросов только добавило бы дополнительную нагрузку, что снизило бы общую производительность системы.
Как SQL Server распараллеливает запросы?
SQL Server распараллеливает запросы, выполняя горизонтальное секционирование входных даны, и число приблизительно равных секций устанавливается равным числу доступных процессоров, после чего для каждой секции выполняется одна и та же операция (например, агрегация, соединение и т.п.). Предположим, что мы хотим использовать два процессора для запроса с агрегатом хэша, который нужен для группировки по целочисленному столбцу. Мы создаем два потока (один для каждого процессора). Каждый поток выполняет один и тот же оператор агрегата хэша. Разделение входных данных можно организовать, например, на основе чётности или нечётности значений столбца группировки. Все принадлежащие одной группе и выделенные в один поток строки обрабатываются одним оператором агрегации хэша, и в итоге мы получаем правильный результат.
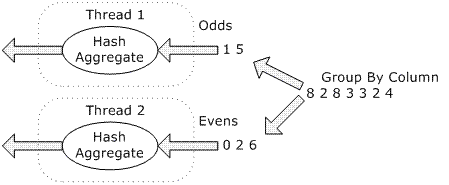
Этот метод параллельного выполнения запроса является и простым и хорошо масштабируемым. В показанном выше примере, оба потока агрегата хэша выполняются независимо. Этим двум потокам не нужно обмениваться сообщениями или координировать свою работу. Если нужно увеличить степень параллелизма (DOP), мы можем простой добавлять ещё потоков и откорректировать соответственно функцию секционирования (на практике для секционирования строк для агрегата хэша используется хеш-функция, которая пригодна для любого типа данных, любого числа групп столбцов, и любого числа потоков).
Реальное секционирование и перемещение данных между потоками выполняется итератором параллелизма (или ещё говорят - итератором обмена). Хотя этот итератор очень специфичен, он поддерживает те же интерфейсы, что любой другой итератор. Большинство итераторов не должны ничего знать о том, что они выполняются параллельно. Просто соответствующие итераторы параллелизма добавляются в план, и выполнение идёт параллельно.
Обратите внимание на то, что описанный выше метод параллелизма не одно и тот же, что и "конвейерный" параллелизм, когда несколько не связанных между собой операторов выполняются одновременно в разных потоках. Хотя SQL Server часто размещает разные операторы в разные потоки, первопричина в том, чтобы можно было снова выделять секции данных, когда они будут передаваться от одного оператора к следующему. С конвейером степень параллелизма и общее число потоков были бы ограничены числом операторов.
Кто решает, распараллеливать ли запрос?
Оптимизатор запросов принимает решение о необходимости распараллеливания исполнения запроса. Это решение, как и большинство других, основывается на стоимости. Сложный и дорогой запрос, который обрабатывает много строк, с большей вероятностью будет распараллелен, чем простой запрос, который обрабатывает очень мало строк.
Кто определяет степень параллелизма (DOP)?
DOP - не является частью кэшируемого откомпилированного плана исполнения запроса и может измениться при следующем исполнении. DOP определяется в начале исполнения, с учётом числа процессоров на сервере и установленных посредством sp_configure параметров глобальной конфигурации "max degree of parallelism" и "max worker threads" (они видны только если установлено значение "show advanced options"), и с учётом подсказки оптимизатору MAXDOP, если она используется. Короче говоря, DOP выбирается таким, чтобы получить параллелизм и не исчерпать число рабочих потоков. Если указан MAXDOP 1, все итераторы параллелизма будут из плана удалены и запрос выполняется по последовательному плану в одном потоке.
Обратите внимание, что число используемых параллельным запросом потоков может превысить DOP. Если при исполнении параллельного запроса отслеживать состояние sys.sysprocesses, можете увидеть большее чем DOP число потоков. Как я говорил выше, если снова выделять секции данных между двумя операторами, они будут помещаться в разные потоки. DOP определяет число потоков на оператор, а не общее число потоков на план исполнения запроса. В SQL Server 2000, если DOP был меньше числа процессоров, дополнительные потоки могли использовать оставшиеся процессоры, что фактически могло привести к отступлениям от заданных настроек MAXDOP. В SQL Server 2005, когда исполняется запрос с заданным DOP, также ограничивается и число планировщиков. То есть все потоки, используемые запросом, будут назначены тому же самому набору планировщиков, и запрос будет использовать только заданное DOP число процессоров независимо от общего числа потоков.