Anatoly Levenchuk
Tony Pearson из IBM написал интересный материал "как построить собственный IBM Watson-младший у себя в подвале" -- https://www.ibm.com/developerworks/mydeveloperworks/blogs/InsideSystemStorage/entry/ibm_watson_how_to_build_your_own_watson_jr_in_your_basement7?lang=en. Все компоненты уже есть, вопрос только в "системной интеграции" -- и ведь наверняка появятся умельцы, которые за такое возьмутся!
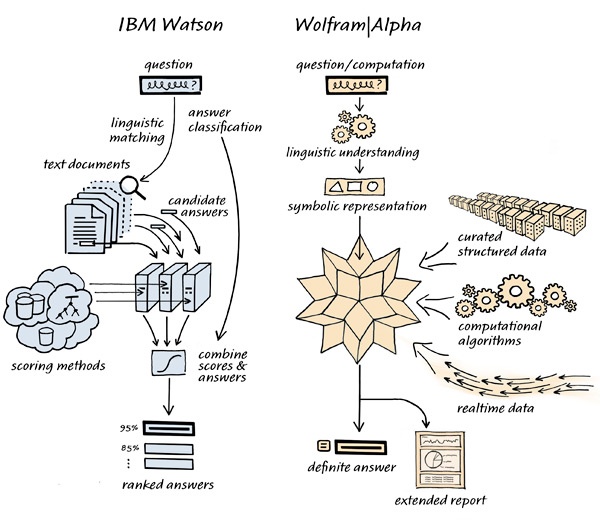
Вот ссылки, которые было бы интересно посмотреть тем людям, которым интересно про внутреннее устройство IBM Watson:
-- http://www.jfsowa.com/pubs/arch.htm -- Architectures for Intelligent Systems, предложена John Sowa в IBM в 2002г.
-- рассказ четырехлетней давности про UIMA: http://ontolog.cim3.net/file/resource/presentation/DavidFerrucci_20060511/UIMA-SemanticWeb--DavidFerrucci_20060511.pdf и звукозапись по этим слайдам: http://ontolog.cim3.net/file/resource/presentation/DavidFerrucci_20060511/UIMA-SemanticWeb--DavidFerrucci_20060511_Recording-2914992-460237.mp3
-- как относятся задачи Jeopardy! с другими вопросно-ответными задачами: http://domino.watson.ibm.com/library/cyberdig.nsf/papers/D12791EAA13BB952852575A1004A055C/$File/rc24789.pdf
-- видео, где David Ferucci объясняет, что он сделал: http://www-943.ibm.com/innovation/us/watson/watson-for-a-smarter-planet/building-a-jeopardy-champion/how-watson-works.html
-- статья про DeepQA в AI Magazine: http://www.stanford.edu/class/cs124/AIMagzine-DeepQA.pdf
На волне публикаций об IBM Watson вылезло и много других интересных проектов, например база данных FactNexus -- http://factnexus.com и пример семантического сервиса на её основе -- поисковой системы http://wik.me (одной из самых крутых на сегодня из доступных в онлайне).
Похоже, что Prolog использовался много больше, чем можно подумать:
http://arxiv.org/ftp/arxiv/papers/0809/0809.0680.pdf -- The Prolog Interface to the Unstructured Information Management Architecture (UIMA). В результате ontolog-forum бросился опять (снова, уже в который раз) обсуждать Prolog в оппозицию "попсовым" OWL/SPARQL --http://ontolog.cim3.net/forum/ontolog-forum/2011-02/index.html. Triple-store плюс Prolog -- вот как представляется сейчас правильное семантическое приложение.
Выясняется, что в VivoMind тоже используется Prolog (John Sowa написал: "In fact, Prolog is the primary language that we use at VivoMind, because it is highly flexible and can be quickly adapted to either informal processing (along the lines used by Watson) or precision analysis (as needed for formal logic). We also use C, but only for heavily used, well tested algorithms that can be frozen in low-level code" -- http://ontolog.cim3.net/forum/ontolog-forum/2011-02/msg00331.html. И в этом же письме его пояснение про связь онтологий с неструктурированной информацией через микротеории (можно считать, что этот термин CYC прижился в более широком сообществе):
> It will be interesting to see how "ontologists" make the shift from
> being "owltogists" to "Watson feeders".
Watson is much more flexible than OWL. A knowledge engineer working with OWL is forced to state every point very precisely in an exactly *decidable* way. But most of the knowledge in every field is vague, flexible, and rarely, if ever, *decidable*.
There are very specialized domains (microtheories) for which OWL and other formal logics are valuable. But the overwhelming amount of knowledge in the world is *unstructured* -- the first letter of UIMA.
I believe that the combination of Prolog with UIMA (or something like it) is much better suited to processing the vast resources of the Web than OWL.
Я сам считаю, что самое интересное будет происходить не в части unstructured, а в части structured: разные онтологии структурирования, разные компактификации знания, разные варианты распознавания одинаковых объектов реального мира (ассоциативная память, работа с аналогиями и т.д.), закодированных по-разному, разные по скорости алгоритмы формального вывода и эвристики в таких алгоритмах и т.д.. Ибо Watson показал, что с "unstructured" можно работать на уровне не хуже, чем чемпионы мира по быстрому пониманию вопросов. Дальше нужно реализовывать не столько "понималку-вспоминалку" с задействованием всего мирового знания, сколько "думалку". Тут еще валялось очень и очень мало коней.
То есть я буду тут заниматься всем, кроме парсера (типа того же парсера McCord, который был использован в Watson). Ибо после прохода парсера возникает вполне формальное представление информации, и дальше нужно "думать", а не "понимать". Вот и будем "думать".
Это, замечу, ничуть не убирает все размышления про семантику и прагматику. Думать-то нужно всегда в контексте, думать для какого-то действия, а не "просто думать". Смотреть в пупок или на чашку риса при медитациях -- бесплодно, даже если этим занимается машина. Думать нужно обязательно "куда-то" и "зачем-то".
(далее идет инф. от редактора сайта)
Презентация с описанием проекта по созданию Mini DeepQA на опенс-сорсном софте (СПО), выполненным в течении 10 недель 5ю студентами и 1м аспирантом в Политехническом институте Ренселлера (http://www.rpi.edu/).
Watson at RPI - Summer 2013
Тексты к слайдам
- 1. TECHNICAL PROJECT REVIEW 14 TH AUGUST, 2013 WATSON @ RPI WATSON RESEARCH LAB PROFESSOR JIM HENDLER SIMON ELLIS KATE MCGUIRE NICOLE NEGEDLY DILLON BURNS MATT KLAWONN AVI WEINSTOCK
- 2. WATSON RPI Simon Ellis INTRODUCTION
- 3. IBM Watson
- 4. Watson is… … a piece of software that will run on your laptop Though very slowly Specialised hardware and control platform … an implementation of the DeepQA concept … the first iteration of the "cognitive computing‟ platform … a very clever artificial intelligence A very clever application of human intelligence
- 5. Background IBM agrees to give RPI a version of Watson Watson team is set up to undertake summer research on the Watson system Watson hardware/software configuration not ready at beginning of summer session So what do we do with: 10 weeks, 5 undergraduates and 1 graduate…
- 6. Challenge accepted! Build a new version of Watson Based on research published in IBM J Res & Dev With support and input from IBM Research Use open source libraries wherever possible Faster development No IP issues Turns out to be a very useful project Trains team in the details of the operation of Watson system Can be used in education, training, testing, evaluation
- 7. Sample output Demo run of RPI version of Watson Shows output representing most of the "pipeline"
- 8. Inside Watson Watson pipeline as published by IBM; see IBM J Res & Dev 56 (3/4), May/July 2012, p. 15:2
- 9. WATSON RPI Nicole Negedly QUESTION ANALYSIS
- 10. Question Analysis
- 11. Question Analysis What is the question asking for? What structured information can be determined from the unstructured text of the question? Topics Parsers Syntactic and Semantic Analysis Tools Focus and Lexical Answer Type Detection Future Work
- 12. Parsing Open-source parsers Stanford Parser Berkeley Parser Functions Determine grammatical structure of text Parse trees, part-of-speech Tags, dependency relations
- 13. Coreference Resolution What terms in the question refer to the same entity?
- 14. Named Entity Extraction Identifies people, places, organizations, and time spans.
- 15. Focus and Lexical Answer Type POETS & POETRY He was a bank clerk in the Yukon before he published Songs of a Sourdough in 1907 Focus: "he" LAT: "he", "clerk", "poet"
- 16. Future Work Adding additional parsers to the system Comparison of parser output Relation extraction Prolog code and database Improved focus and LAT detection Princeton WordNet
- 17. WATSON RPI Dillon Burns PRIMARY SEARCH
- 18. Primary Search
- 19. Primary Search & Corpus Generation Primary search is used to generate our corpus of information from which to take candidate answers, passages, supporting evidence, and essentially all textual input to the system. Search Wikipedia for the focus identified during the Question Analysis phase. Grab first 5 documents returned back as corpus. Uses Jsoup library to collect and parse HTML.
- 20. JSoup String[] results = {"/wiki/Snapple","/wiki/Dr_Pepper_Snapple_Group","/wiki/Snapple_Theater…."
- 21. JSoup String[] results = {"/wiki/Snapple","/wiki/Dr_Pepper_Snapple_Group","/wiki/Snapple_Theater…." To Cache
- 22. DBpedia
- 23. DBpedia As of 2011 it had 3.64 million things categorized in its database URLs are a direct map to Wikipedia‟s Wikipedia redirect lists help with alternate names for entities and closely related concepts to certain entities or people
- 24. Future Directions Use DBpedia to fact-check answers about entities in the database Making use of the DBpedia subject matching
- 25. WATSON RPI Kate McGuire CANDIDATE GENERATION
- 26. Search Result Processing and Candidate Generation
- 27. Search Result Processing and Candidate Generation
- 28. Search Result Processing Passage Retrieval Watson: Indri and Lucene Identifies each HTML sentence and adds both the HTML and the clean text to the passage type Adds information about each passage Passage Parsing Forms parse trees for each individual sentence Add an array of passages to each document
- 29. Search Result Processing Passage Retrieval Watson: Indri and Lucene Identifies each HTML sentence and adds both the HTML and the clean text to the passage type Adds information about each passage Passage Parsing Forms parse trees for each individual sentence Add an array of passages to each document
- 30. Search Result Processing Passage Retrieval Watson: Indri and Lucene
- 32. Search Result Processing Passage Retrieval Watson: Indri and Lucene
- 33. Search Result Processing Passage Retrieval Watson: Indri and Lucene
- 34. Search Result Processing Passage Retrieval Watson: Indri and Lucene
- 35. Search Result Processing Passage Retrieval Watson: Indri and Lucene
- 37. Candidate Generation Using each document, and the passages created by Search Result Processing, we generate candidates using three techniques: 1. Title of Document (T.O.D.): Adds the title of the document as a candidate. 2. Wikipedia Title Candidate Generation: Adds any noun phrases within the document‟s passage texts that are also the titles of Wikipedia articles. 3. Anchor Text Candidate Generation: Adds candidates based on the hyperlinks and metadata within the document.
- 38. Wikipedia Title Candidate Generation Runs on the passage array from each search result. Using the parse tree, retrieves all the noun phrases in each passage. 39. Wikipedia Title Candidate Generation Runs on the passage array from each search result. Using the parse tree, retrieves all the noun phrases in each passage. Checks if each Noun Phrase is the title of a Wikipedia Article Adds the verified candidates along with an array of the passages that contained them Array of Passages Retrieving Noun Phrases Check against Previous Data Wikipedia URL Check Candidate and Containing Passages
- 40. Wikipedia Title Candidate Generation Runs on the passage array from each search result. Using the parse tree, retrieves all the noun phrases in each passage. Checks if each Noun Phrase is the title of a Wikipedia Article Adds the verified candidates along with an array of the passages that contained them Array of Passages Retrieving Noun Phrases Check against Previous Data Wikipedia URL Check Candidate and Containing Passages Shirley Ann Jackson Shirley Ann Jackson (born August 5, 1946) August 5, 1946 An American Physicist An American Physicist, and the 18th president of Rensselaer Polytechnic Institute The 18th president The 18th president of Rensselaer Polytechnic Institute Rensselaer Polytechnic Institute
- 41. Wikipedia Title Candidate Generation Runs on the passage array from each search result. Using the parse tree, retrieves all the noun phrases in each passage. Checks if each Noun Phrase is the title of a Wikipedia Article Adds the verified candidates along with an array of the passages that contained them Array of Passages Retrieving Noun Phrases Check against Previous Data Wikipedia URL Check Candidate and Containing Passages http://en.wikipedia.org/w/index.php?title=Special%3ASearch&profile=default&search= Shirley+Ann+Jackson Shirley Ann Jackson Shirley Ann Jackson (born August 5, 1946) August 5, 1946 An American Physicist An American Physicist, and the 18th president of Rensselaer Polytechnic Institute The 18th president The 18th president of Rensselaer Polytechnic Institute Rensselaer Polytechnic Institute
- 42. Wikipedia Title Candidate Generation Runs on the passage array from each search result. Using the parse tree, retrieves all the noun phrases in each passage. Checks if each Noun Phrase is the title of a Wikipedia Article Adds the verified candidates along with an array of the passages that contained them Array of Passages Retrieving Noun Phrases Check against Previous Data Wikipedia URL Check Candidate and Containing Passages http://en.wikipedia.org/w/index.php?title=Special%3ASearch&profile=default&search= Shirley+Ann+Jackson Shirley Ann Jackson Shirley Ann Jackson (born August 5, 1946) August 5, 1946 An American Physicist An American Physicist, and the 18th president of Rensselaer Polytechnic Institute The 18th president The 18th president of Rensselaer Polytechnic Institute Rensselaer Polytechnic Institute
- 43. Anchor Text Candidate Generation Runs on the passage array from each search result. Checks for hyperlinks within the HTML text of each passage. Adds the title of the hyperlinked article as a candidate Adds each passage containing the candidate to an array
- 44. Anchor Text Candidate Generation Runs on the passage array from each search result. Checks for hyperlinks within the HTML text of each passage. Adds the title of the hyperlinked article as a candidate Adds each passage containing the candidate to an array
- 45. Search Result Processing
- 46. Search Result Processing
- 47. Future Work Search Result Processing Improve methods of imitating Indri or Lucene passage retrieval without a corpus. Create a passage score and rank. Candidate Generation Continue to improve the speed and quality of Candidate Generation Research and implement Candidate Generation from Structured Sources (Prismatic, Answer Lookup) Record and measure recall in comparison with Watson and other Question answering software.
- 48. WATSON RPI Matt Klawonn SCORING & RANKING
- 49. Scoring & Ranking
- 50. Differentiating between answers Making sense of candidates Filtering Supporting Evidence Retrieval (SER) Scoring (passage-based)
- 51. Scorers Passage Term Match Textual Alignment Skip-Bigram Each of these scores supportive evidence These scores are then merged to produce a single candidate score
- 52. Passage Term Search Question Terms Extracted Passage is searched for those terms Score calculated for that passage Done per passage "Where is Toronto?" "Where" "is" "Toronto" "Toronto is in Southern Ontario" "Toronto is " Score = IDF(Toronto) + IDF(is)
- 53. Textual Alignment Finds an optimal alignment of a question and a passage Assigns "partial credit" for close matches "Who is the President of RPI?" Shirley Ann Jackson is the President of RPI. Who is the President of RPI.
- 54. Skip-Bigram Constructs a graph Nodes represent terms (syntactic objects) Edges represent relations Extracts skip-bigrams A skip-bigram is a pair of nodes either directly connected or which have only one intermediate node Skip-bigrams represent close relationships between terms Scores based on number of common skip-bigrams
- 55. Example Who authored "The Good Earth"? "Pearl Buck, author of the good earth…"
- 56. Future Directions More algorithms Logical form answer candidate scoring Improved Type Coercion scoring Begin implementing machine learning Temporal/Spatial reasoning
- 57. WATSON RPI Avi Weinstock UIMA PIPELINE
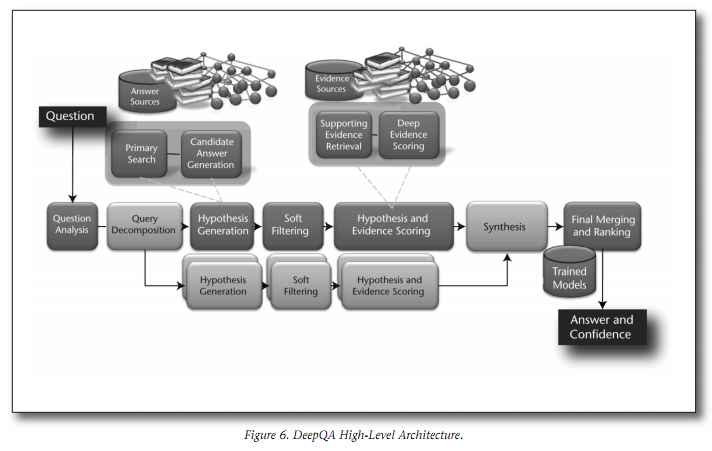
- 58. UIMA The DeepQA architecture is built on top of another architecture, UIMA (Unstructured Information Management Architecture). A UIMA CAS (Common Analysis Structure) contains a contiguous block of data (normally text), and annotations, which contain start & end indexes into the data, and additional data (strings, integers, doubles, arrays, annotation references).
- 59. UIMA CAS Multipliers output multiple CASes based on the data in the input CAS; this facilitates parallelization, which is the key to Watson‟s response time.
- 60. DeepQA Architecture The DeepQA architecture, which both IBM Watson and RPI MiniDeepQA implement, is a QA (Question Answering) system that answers questions by generating as many potential answers as is practical, then filtering them with multiple evidence scorers in parallel.
- 61. Data cache IBM Watson has a pre-processed corpus of information, generated automatically by a subset of the DeepQA pipeline from an enormous volume of raw text, which the remainder of the pipeline uses at question time. As our system retrieves information from the internet on a per-question basis, it cannot (practically) process the whole corpus in advance.
- 62. Data cache Since parsing the documents takes a large amount of time, in order to test/demonstrate the system, it is beneficial to store webpages and associated parses locally. This allows a question that has been asked before, and candidates that come up for multiple questions, to be processed faster. As a side-benefit of the caching, if a website is temporarily down, its data can still be used (if it was not down at some point in the past).
- 63. Graphical User Interface Towards the start of the project, we ran our system using the Document Analyzer (a UIMA-provided tool). While it was useful, once we had the entire pipeline set up, testing the full system required more input than necessary. Additionally, there wasn't a convenient way to display just the intended output, nor intermediate output at a level suitable for monitoring progress/giving demonstrations.
- 64. Graphical User Interface The GUI addresses these concerns, and has additionally been extensively tweaked to be demonstration-friendly.

Tony Pearson is a Master Inventor and Senior IT Specialist for the IBM System Storage product line at the
IBM Executive Briefing Center in Tucson Arizona, and featured contributor to IBM's developerWorks. In 2011, Tony celebrated his 25th year anniversary with IBM Storage on the same day as the
IBM's Centennial. He is author of the Inside System Storage
series of books. This blog is for the open exchange of ideas relating to storage and storage networking hardware, software and services. You can also follow him on Twitter @az990tony.
(Short URL for this blog:
ibm.co/Pearson )
IBM Watson - How to build your own "Watson Jr." in your basement
For the longest time, people thought that humans could not run a mile in less than four minutes. Then, in 1954, [Sir Roger Bannister] beat that perception, and shortly thereafter, once he showed it was possible, many other runners were able to achieve this also. The same is being said now about the IBM Watson computer which appeared this week against two human contestants on Jeopardy!
| |
Often, when a company demonstrates new techology, these are prototypes not yet ready for commercial deployment until several years later. IBM Watson, however, was made mostly from commercially available hardware, software and information resources. As several have noted, the 1TB of data used to search for answers could fit on a single USB drive that you buy at your local computer store.
But could you fit an entire Watson in your basement? The IBM Power 750 servers used in IBM Watson earned the [EPA Energy Star] rating, and is substantially [more energy-efficient than comparable 4-socket x86, Itanium, or SPARC servers]. However, having ninety of them in your basement would drive up your energy bill. |
Take a look at the [IBM Research Team] to determine how the project was organized. Let's decide what we need, and what we don't in our Watson Jr. :
| Role: |
Do we need it for Watson Jr. ? |
| Team Lead |
Yes, That's you. Assuming this is a one-person project, you will act as Team Lead. |
| Algorithms |
Yes, I hope you know computer programming! |
| Game Strategy |
No, since Watson Jr. won't be appearing on Jeopardy, we won't need strategy on wager amounts for the Daily Double, or what clues to pick next. Let's focus merely on a computer that can accept a question in text, and provide an answer back, in text. |
| Systems |
Yes, this team focused on how to wire all the hardware together. We need to do that, although Watson Jr. will have fewer components. |
| Speech Synthesis |
Optional. For now, let's have Watson Jr. just return its answer in plain text. Consider this Extra Credit after you get the rest of the system working. Consider using [eSpeak], [FreeTTS], or the Modular Architecture for Research on speech sYnthesis [MARY] Text-to-Speech synthesizers. |
| Annotations |
Yes, I will explain what this is, and why you need it. |
| Information Sources |
Yes, we will need to get information for Watson Jr. to process |
| Question Parsing |
Yes, this team developed a system for parsing the question being asked, and to attach meaning to the different words involved. |
| Search Optimization |
No, this team focused on making IBM Watson optimized to answer in 3 seconds or less. We can accept a slower response, so we can skip this. |
| Project Management |
Yes, even for a one-person project, having a little "project management" never hurt anyone. I highly recommend the book [Getting Things Done: The Art of Stress-Free Productivity] by David Allen]. |
(Disclaimer: As with any Do-It-Yourself (DIY) project, I am not responsible if you are not happy with your Watson Jr. I am basing the approach on what I read from publicly available sources, and my work in Linux, supercomputers, XIV, and SONAS. For our purposes, Watson Jr. is based entirely on commodity hardware, open source software, and publicly available sources of information. Your Watson Jr. will certainly not be as fast or as clever as the IBM Watson you saw on television.)
- Step 1: Buy the Hardware
-
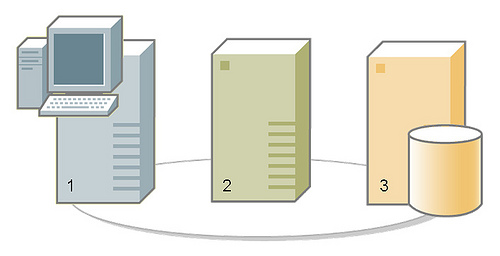 |
Supercomputers are built as a cluster of identical compute servers lashed together by a network. You will be installing Linux on them, so if you can avoid paying extra for Microsoft Windows, that would save you some money. Here is your shopping list:
- Three x86 hosts, with the following:
- 64-bit quad-core processor, either Intel-VT or AMD-V capable,
- 8GB of DRAM, or larger
- 300GB of hard disk, or larger
- CD or DVD Read/Write drive
- 1GbE Ethernet
- Computer Monitor, mouse and keyboard
- Ethernet 1GbE 4-port hub, and appropriate RJ45 cables
- Surge protector and Power strip
- Local Console Monitor (LCM) 4-port switch (formerly known as a KVM switch) and appropriate cables. This is optional, but will make it easier during the development. Once your Watson Jr. is operational, you will only need the monitor and keyboard attached to one machine. The other two machines can remain "headless" servers.
|
- Step 2: Establish Networking
-
IBM Watson used Juniper switches running at 10Gbps Ethernet (10GbE) speeds, but was not connected to the Internet while playing Jeopardy! Instead, these Ethernet links were for the POWER7 servers to talk to each other, and to access files over the Network File System (NFS) protocol to the internal customized SONAS storage I/O nodes.
The Watson Jr. will be able to run "disconnected from the Internet" as well. However, you will need Internet access to download the code and information sources. For our purposes, 1GbE should be sufficient. Connect your Ethernet hub to your DSL or Cable modem. Connect all three hosts to the Ethernet switch. Connect your keyboard, video monitor and mouse to the LCM, and connect the LCM to the three hosts.
- Step 3: Install Linux and Middleware
-
To say I use Linux on a daily basis is an understatement. Linux runs on my Android-based cell phone, my laptop at work, my personal computers at home, most of our IBM storage devices from SAN Volume Controller to XIV to SONAS, and even on my Tivo at home which recorded my televised episodes of Jeopardy!
For this project, you can use any modern Linux distribution that supports KVM. IBM Watson used Novel SUSE Linux Enterprise Server [SLES 11]. Alternatively, I can also recommend either Red Hat Enterprise Linux [RHEL 6] or Canonical [Ubuntu v10]. Each distribution of Linux comes in different orientations. Download the the 64-bit "ISO" files for each version, and burn them to CDs.
- Graphical User Interface (GUI) oriented, often referred to as "Desktop" or "HPC-Head"
- Command Line Interface (CLI) oriented, often referred to as "Server" or "HPC-Compute"
- Guest OS oriented, to run in a Hypervisor such as KVM, Xen, or VMware. Novell calls theirs "Just Enough Operating System" [JeOS].
For Watson Jr. , I have chosen a [multitier architecture], sometimes referred to as an "n-tier" or "client/server" architecture.
- Host 1 - Presentation Server
-
For the Human-Computer Interface [HCI], the IBM Watson received categories and clues as text files via TCP/IP, had a [beautiful avatar] representing a planet with 42 circles streaking across in orbit, and text-to-speech synthesizer to respond in a computerized voice. Your Watson Jr. will not be this sophisticated. Instead, we will have a simple text-based Query Panel web interface accessible from a browser like Mozilla Firefox.
Host 1 will be your Presentation Server, the connection to your keyboard, video monitor and mouse. Install the "Desktop" or "HPC Head Node" version of Linux. Install [Apache Web Server and Tomcat] to run the Query Panel. Host 1 will also be your "programming" host. Install the [Java SDK] and the [Eclipse IDE for Java Developers]. If you always wanted to learn Java, now is your chance. There are plenty of books on Java if that is not the language you normally write code.
While three little systems doesn't constitute an "Extreme Cloud" environment, you might like to try out the "Extreme Cloud Administration Tool", called [xCat], which was used to manage the many servers in IBM Watson.
- Host 2 - Business Logic Server
-
Host 2 will be driving most of the "thinking". Install the "Server" or "HPC Compute Node" version of Linux. This will be running a server virtualization Hypervisor. I recommend KVM, but you can probably run Xen or VMware instead if you like.
- Host 3 - File and Database Server
-
Host 3 will hold your information sources, indices, and databases. Install the "Server" or "HPC Compute Node" version of Linux. This will be your NFS server, which might come up as a question during the installation process.
Technically, you could run different Linux distributions on different machines. For example, you could run "Ubuntu Desktop" for host 1, "RHEL 6 Server" for host 2, and "SLES 11" for host 3. In general, Red Hat tries to be the best "Server" platform, and Novell tries to make SLES be the best "Guest OS".
My advice is to pick a single distribution and use it for everything, Desktop, Server, and Guest OS. If you are new to Linux, choose Ubuntu. There are plenty of books on Linux in general, and Ubuntu in particular, and Ubuntu has a helpful community of volunteers to answer your questions.
- Step 4: Download Information Sources
-
You will need some documents for Watson Jr. to process.
IBM Watson used a modified SONAS to provide a highly-available clustered NFS server. For Watson Jr. , we won't need that level of sophistication. Configure Host 3 as the NFS server, and Hosts 1 and 2 as NFS clients. See the [Linux-NFS-HOWTO] for details. To optimize performance, host 3 will be the "official master copy", but we will use a Linux utility called rsync to copy the information sources over to the hosts 1 and 2. This allows the task engines on those hosts to access local disk resources during question-answer processing.
We will also need a relational database. You won't need a high-powered IBM DB2. Watson Jr. can do fine with something like [Apache Derby] which is the open source version of IBM CloudScape from its Informix acquisition. Set up Host 3 as the Derby Network Server, and Hosts 1 and 2 as Derby Network Clients. For more about structured content in relational databases, see my post [IBM Watson - Business Intelligence, Data Retrieval and Text Mining].
Linux includes a utility called wget which allows you to download content from the Internet to your system. What documents you decide to download is up to you, based on what types of questions you want answered. For example, if you like Literature, check out the vast resources at [FullBooks.com]. You can automate the download by writing a shell script or program to invoke wget to all the places you want to fetch data from. Rename the downloaded files to something unique, as often they are just "index.html". For more on wget utility, see [IBM Developerworks].
- Step 5: The Query Panel - Parsing the Question
-
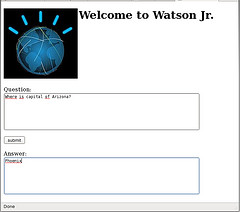 |
Next, we need to parse the question and have some sense of what is being asked for. For this we will use [OpenNLP] for Natural Language Processing, and [OpenCyc] for the conceptual logic reasoning. See Doug Lenat presenting this 75-minute video [Computers versus Common Sense]. To learn more, see the [CYC 101 Tutorial].
Unlike Jeopardy! where Alex Trebek provides the answer and contestants must respond with the correct question, we will do normal Question-and-Answer processing. To keep things simple, we will limit questions to the following formats:
- Who is ...?
- Where is ...?
- When did ... happen?
- What is ...?
- Which ...?
|
Host 1 will have a simple Query Panel web interface. At the top, a place to enter your question, and a "submit" button, and a place at the bottom for the answer to be shown. When "submit" is pressed, this will pass the question to "main.jsp", the Java servlet program that will start the Question-answering analysis. Limiting the types of questions that can be posed will simplify hypothesis generation, reduce the candidate set and evidence evaluation, allowing the analytics processing to continue in reasonable time.
- Step 6: Unstructured Information Management Architecture
-
The "heart and soul" of IBM Watson is Unstructured Information Management Architecture [UIMA]. IBM developed this, then made it available to the world as open source. It is maintained by the [Apache Software Foundation], and overseen by the Organization for the Advancement of Structured Information Standards [OASIS]. 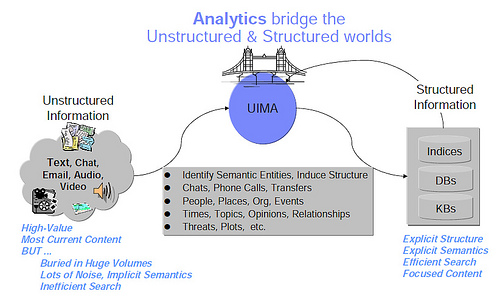
Basically, UIMA lets you scan unstructured documents, gleam the important points, and put that into a database for later retrieval. In the graph above, DBs means 'databases' and KBs means 'knowledge bases'. See the 4-minute YouTube video of [IBM Content Analytics], the commercial version of UIMA. 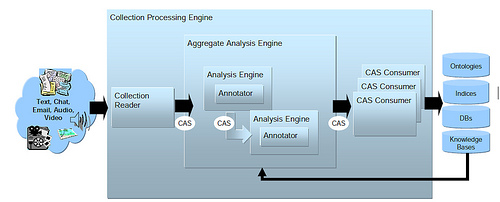
Starting from the left, the Collection Reader selects each document to process, and creates an empty Common Analysis Structure (CAS) which serves as a standardized container for information. This CAS is passed to Analysis Engines , composed of one or more Annotators which analyze the text and fill the CAS with the information found. The CAS are passed to CAS Consumers which do something with the information found, such as enter an entry into a database, update an index, or update a vote count.
(Note: This point requires, what we in the industry call a small matter of programming, or [SMOP]. If you've always wanted to learn Java programming, XML, and JDBC, you will get to do plenty here. )
If you are not familiar with UIMA, consider this [UIMA Tutorial].
- Step 7: Parallel Processing
-
People have asked me why IBM Watson is so big. Did we really need 2,880 cores of processing power? As a supercomputer, the 80 TeraFLOPs of IBM Watson would place it only in 94th place on the [Top 500 Supercomputers]. While IBM Watson may be the [Smartest Machine on Earth], the most powerful supercomputer at this time is the Tianhe-1A with more than 186,000 cores, capable of 2,566 TeraFLOPs.
To determine how big IBM Watson needed to be, the IBM Research team ran the DeepQA algorithm on a single core. It took 2 hours to answer a single Jeopardy question! Let's look at the performance data:
| Element |
Number of cores |
Time to answer one Jeopardy question |
| Single core |
1 |
2 hours |
| Single IBM Power750 server |
32 |
< 4 minutes |
| Single rack (10 servers) |
320 |
< 30 seconds |
| IBM Watson (90 servers) |
2,880 |
< 3 seconds |
The old adage applies, [many hands make for light work]. The idea is to divide-and-conquer. For example, if you wanted to find a particular street address in the Manhattan phone book, you could dispatch fifty pages to each friend and they could all scan those pages at the same time. This is known as "Parallel Processing" and is how supercomputers are able to work so well. However, not all algorithms lend well to parallel processing, and the phrase [nine women can't have a baby in one month] is often used to remind us of this.
Fortuantely, UIMA is designed for parallel processing. You need to install UIMA-AS for Asynchronous Scale-out processing, an add-on to the base UIMA Java framework, supporting a very flexible scale-out capability based on JMS (Java Messaging Services) and ActiveMQ. We will also need Apache Hadoop, an open source implementation used by Yahoo Search engine. Hadoop has a "MapReduce" engine that allows you to divide the work, dispatch pieces to different "task engines", and the combine the results afterwards.
Host 2 will run Hadoop and drive the MapReduce process. Plan to have three KVM guests on Host 1, four on Host 2, and three on Host 3. That means you have 10 task engines to work with. These task engines can be deployed for Content Readers , Analysis Engines , and CAS Consumers . When all processing is done, the resulting votes will be tabulated and the top answer displayed on the Query Panel on Host 1.
- Step 8: Testing
-
To simplify testing, use a batch processing approach. Rather than entering questions by hand in the Query Panel, generate a long list of questions in a file, and submit for processing. This will allow you to fine-tune the environment, optimize for performance, and validate the answers returned.
There you have it. By the time you get your Watson Jr. fully operational, you will have learned a lot of useful skills, including Linux administration, Ethernet networking, NFS file system configuration, Java programming, UIMA text mining analysis, and MapReduce parallel processing. Hopefully, you will also gain an appreciation for how difficult it was for the IBM Research team to accomplish what they had for the Grand Challenge on Jeopardy! Not surprisingly, IBM Watson is making IBM [as sexy to work for as Apple, Google or Facebook], all of which started their business in a garage or a basement with a system as small as Watson Jr. . |
Jon Baer, Senior Application Developer, Father, Hockey Player
The press release seems to go into some details on how Apache UIMA and Hadoop are used. [1] There is also a great followup article on The Register. [2]
The Watson system uses UIMA as its principal infrastructure for
component interoperability and makes extensive use of the UIMA-AS
scale-out capabilities that can exploit modern, highly parallel hardware
architectures. UIMA manages all work flow and communication between
processes, which are spread across the cluster. Apache Hadoop manages
the task of preprocessing Watson's enormous information sources by
deploying UIMA pipelines as Hadoop mappers, running UIMA analytics.
David Gondek tells El Reg that IBM used Prolog to do question
analysis. Some Watson algorithms are written in C or C++, particularly
where the speed of the processing is important. But Gondek says that
most of the hundreds of algorithms that do question analysis, passage
scoring, and confidence estimation are written in Java. [2]
Hadoop was used to create Watson"s "brain," or the database of knowledge
and facilitation of Watson"s processing of enormously large volumes of
data in milliseconds. Watson depends on 200 million pages of content and
500 gigabytes of preprocessed information to answer Jeopardy questions. That huge catalog of documents has to be searchable in seconds. [3]
Building Watson: An Overview of the DeepQA Project - PDF [4]
Building Watson: An Overview of the DeepQA Project - Video [5]
IBM Watson used a modified SONAS to provide a highly-available clustered NFS server. [6]
Also here's a video with Grady Booch that talks about the system architecture at a high level
Posted by Erik Martin (hueypriest) at
12:13
/
Below are answers to your top 10 questions, along with some bonus common ones as well. Thanks for taking the time to answer,
Watson Team!
--
1. Could you give an example of a question (or question style) that Watson always struggled with? (Chumpesque)
Any questions that require the resolution of very opaque references especially to everyday knowledge that no one might have written about in an explicit way. For example, "If you're standing, it's the direction you should look to check out the wainscoting."
Or questions that require a resolving and linking opaque and remote reference, for example "A relative of this inventor described him as a boy staring at the tea kettle for an hour watching it boil."
The answer is James Watt, but he might have many relatives and there may be very many ways in which one of them described him as studying tea boil. So first, find every possible inventor (and there may be 10,000's of inventors), then find each relative, then what they said about the inventor (which should express that he stared at boiling tea). Watson attempts to do exactly this kind of thing but there are many possible places to fail to build confident evidence in just a few seconds.
2. What was the biggest technological hurdle you had to overcome in the development of Watson? (this_is_not_the_cia)
Accelerating the innovation process - making it easy to combine, weigh evaluate and evolve many different independently developed algorithms that analyze language form different perspectives.
Watson is a leap in computers being able to understand natural language, which will help humans be able to find the answers they need from the vast amounts of information they deal with everyday. Think of Watson as a technology that will enable people to have the exact information they need at their fingertips
3. Can you walk us through the logic Watson would go through to answer a question such as, "The antagonist of Stevenson's Treasure Island." (Who is Long John Silver?) (elmuchoprez)
Step One: Parses sentence to get some logical structure describing the answer
X is the answer.
antagonist(X).
antagonist_of(X, Stevenson's Treasure Island).
modifies_possesive(Stevenson, Treasure Island).
modifies(Treasure, Island)
Step Two: Generates Semantic Assumptions
island(Treasure Island)
location(Treasure Island)
resort(Treasure Island)
book(Treasure Island)
movie(Treasure Island)
person(Stevenson)
organization(Stevenson)
company(Stevenson)
author(Stevenson)
director(Stevenson)
person(antagonist)
person(X)
Step Three: Builds different semantic queries based on phrases, keywords and semantic assumptions.
Step Four: Generates 100s of answers based on passage, documents and facts returned
from 3. Hopefully Long-John Silver is one of them.
Step Five: For each answer formulates new searches to find evidence in support or
refutation of answer -- score the evidence.
Positive Examples:
Long-John Silver the main character in Treasure Island.....
The antagonist in Treasure Island is Long-John Silver
Treasure Island, by Stevenson was a great book.
One of the great antagonists of all time was Long-John Silver
Richard Lewis Stevenson's book, Treasure Island features many great
characters, the greatest of which was Long-John Silver.
Step Six: Generate, get evidence and score new assumptions
Positive Examples: (negative examples would support other characters,
people, books, etc associated with any Stevenson, Treasure or Island)
Stevenson = Richard Lewis Stevenson
"by Stevenson" --> Stevenson's
main character --> antagonist
Step Seven: Combine all the evidence and their scores
Based on analysis of evidence for all possible answer compute a final
confidence and link back to the evidence.
Watson's correctness will depend on evidence collection, analysis and
scoring algorithms and the machine learning used to weight and combine the
scores.
4. What is Watson"s strategy for seeking out Daily Doubles, and how did it compute how much to wager on the Daily Doubles and the final clue? (AstroCreep5000)
Watson"s strategy for seeking out Daily Doubles is the same as humans -- Watson hunts around the part of the grid where they typically occur.
In order to compute how much to wager, Watson uses input like its general confidence, the current state of the game (how much ahead or behind), its confidence in the category and prior clues, what is at risk and known human betting behaviors. We ran Watson through many, many simulations to learn the optimal bet for increasing chances of winning.
5. It seems like Watson had an unfair advantage with the buzzer. How did Jeopardy! and IBM try to level the playing field? (Raldi)
Jeopardy! and IBM tried to ensure that both humans and machines had equivalent interfaces to the game. For example, they both had to press down on the same physical buzzer. IBM had to develop a mechanical device that grips and physically pushes the button. Any given player however has different strengths and weakness relative to his/her/its competitors. Ken had a fast hand relative to his competitors and dominated many games because he had the right combination of language understanding, knowledge, confidence, strategy and speed. Everyone knows you need ALL these elements to be a Jeopardy! champion.
Both machine and human got the same clues at the same time -- they read differently, they think differently, they play differently, they buzz differently but no player had an unfair advantage over the other in terms of how they interfaced with the game. If anything the human players could hear the clue being read and could anticipate when the buzzer would enable. This allowed them the ability to buzz in almost instantly and considerably faster than Watson's fastest buzz. By timing the buzz just right like this, humans could beat Watson's fastest reaction. At the same time, one of Watson's strength was its consistently fast buzz -- only effective of course if it could understand the question in time, compute the answer and confidence and decide to buzz in before it was too late.
The clues are in English -- Brad and Ken's native language; not Watson's. Watson analyzes the clue in natural language to understand what the clue is asking for. Once it has done that, it must sift through the equivalent of one million books to calculate an accurate response in 2-3 seconds and determine if it's confident enough to buzz in, because in Jeopardy! you lose money if you buzz in and respond incorrectly. This is a huge challenge, especially because humans tend to know what they know and know what they don't know. Watson has to do thousands of calculations before it knows what it knows and what it doesn't. The calculating of confidence based on evidence is a new technological capability that is going to be very significant in helping people in business and their personal lives, as it means a computer will be able to not only provide humans with suggested answers, but also provide an explanation of where the answers came from and why they seem correct.
6. What operating system does Watson use? What language is he written in? (RatherDashing)
Watson is powered by 10 racks of IBM Power 750 servers running Linux, and uses 15 terabytes of RAM, 2,880 processor cores and is capable of operating at 80 teraflops. Watson was written in mostly Java but also significant chunks of code are written C++ and Prolog, all components are deployed and integrated using UIMA.
Watson contains state-of-the-art parallel processing capabilities that allow it to run multiple hypotheses - around one million calculations - at the same time. Watson is running on 2,880 processor cores simultaneously, while your laptop likely contains four cores, of which perhaps two are used concurrently. Processing natural language is scientifically very difficult because there are many different ways the same information can be expressed. That means that Watson has to look at the data from scores of perspectives and combine and contrast the results. The parallel processing power provided by IBM Power 750 systems allows Watson to do thousands of analytical tasks simultaneously to come up with the best answer in under three seconds.
7. Are you pleased with Watson's performance on Jeopardy!? Is it what you were expecting? (eustis)
We are pleased with Watson's performance on Jeopardy! While at times, Watson did provide the wrong response to the clues, such as its Toronto response, it is still a giant leap in a computer"s understanding of natural human language; in its ability to understand what the Jeopardy! clue was asking for and respond with the correct response the majority of the time.
8. Will Watson ever be available public [sic] on the Internet? (i4ybrid)
We envision Watson-like cloud services being offered by companies to consumers, and we are working to create a cloud version of Watson's natural language processing. However, IBM is focused on creating technologies that help businesses make sense of data in order to enable companies to provide the best service to the consumer.
So, we are first focused on providing this technology to companies so that those companies can then provide improved services to consumers. The first industry we will provide the Watson technology to is the healthcare industry, to help physicians improve patient care.
Consider these numbers:
- Primary care physicians spend an average of only 10.7 - 18.7 minutes face-to-face with each patient per visit.
- Approximately 81% average 5 hours or less per month - or just over an hour a week -- reading medical journals.
- An estimated 15% of diagnoses are inaccurate or incomplete.
In today"s healthcare environment, where physicians are often working with limited information and little time, the results can be fragmented care and errors that raise costs and threaten quality. What doctors need is an assistant who can quickly read and understand massive amounts of information and then provide useful suggestions.
In terms of other applications we"re exploring, here are a few examples of how Watson might some day be used:
- Watson technology offered through energy companies could teach us about our own energy consumption. People querying Watson on how they might improve their energy management would draw on extensive knowledge of detailed smart meter data, weather and historical information.
- Watson technology offered through insurance companies would allow us to get the best recommendations from insurance agents and help us understand our policies more easily. For our questions about insurance coverage, the question answering system would access the text for that person"s actual policy, the other policies that they might have purchased, and any exclusions, endorsements, and riders.
- Watson technology offered through travel agents would more easily allow us to plan our vacations based on our interests, budget, desired temperature, and more. Instead of having to do lots of searching, Watson-like technology could help us quickly get the answers we need among all of the information that is out there on the Internet about hotels, destinations, events, typical weather, etc, to plan our travel faster.
9. How raw is your source data? I am sure that you distilled down whatever source materials you were using into something quick to query, but I noticed that on some of the possible answers Watson had, it looked like you weren't sanitizing your sources too much; for example, some words were in all caps, or phrases included extraneous and unrelated bits. Did such inconsistencies not cause you any problems? Couldn't Watson trip up an answer as a result? (knorby)
Some of the source data was very messy and we did several things to clean it up. It was relatively rare, less than 1% of the time that this issue overtly surfaced in a confident answer. Evidentiary passages might have been weighed differently if they were cleaner, however. We did not measure how much of problem messy data effected evidence assessment.
10. I'm interested in how Watson is able to (sometimes) use object-specific questions like "Who is --" or "Where is --". In the training/testing materials I saw, it seemed to be limited to "What is--" regardless of what is being talked about ("What is Shakespeare?"), which made me think that words were only words and Watson had no way of telling if a word was a person, place, or thing. Then in the Jeopardy challenge, there was plenty of "Who is--." Was there a last-minute change to enable this, or was it there all along and I just never happened to catch it? I think that would help me understand the way that Watson stores and relates data. (wierdaaron)
Watson does distinguish between and people, things, dates, events, etc. certainly for answering questions. It does not do it perfectly of course, there are many ambiguous cases where it struggles to resolve. When formulating a response, however, since "What is...." was acceptable regardless, early on in the project, we did not make the effort to classify the answer for the response. Later in the project, we brought more of the algorithms used in determining the answer to help formulate the more accurate response phrase. So yes, there was a change in that we applied those algorithms, or the results there-of, to formulate the "who"/"what" response.
11. Now that both Deep Blue and Watson have proven to be successful, what is IBM's next "great challenge"? (xeones)
We don"t assign grand challenges, grand challenges arrive based on our scientists' insights and inspiration. One of the great things about working for IBM Research is that we have so much talent that we have ambitious projects going on in a wide variety of areas today. For example:
- We are working to make computing systems 1,000 times more powerful than they are today from the petascale to the exascale.
- We are working to make nanoelectronic devices 1,000 times smaller than they are today, moving us from an era of nanodevices to nanosystems. One of those systems we are working on is a DNA transistor, which could decode a human genome for under $1000, to help enable personalized medicine to become reality.
- We are working on technologies that move from an era of wireless connectivity -- which we all enjoy today -- to the Internet of Things and people, where all sorts of unexpected things can be connected to the Internet.
12. Can we have Watson itself / himself do an AMA? If you give him traditional questions, ie not phrased in the form they are on jeopardy, how well will he perform- how tailored is he to those questions, and how easy would it be to change that? Would it be unfeasible to hook him up to a website and let people run queries?
At this point, all Watson can do is play Jeopardy and provide responses in the Jeopardy format. However, we are collaborating with Nuance, Columbia University Medical Center and the University of Maryland School of Medicine to apply Watson technology to healthcare. You can read more about that here: http://www-03.ibm.com/press/us/en/pressrelease/33726.wss
13. After seeing the description of how Watson works, I found myself wondering whether what it does is really natural language processing, or something more akin to word association. That is to say, does Watson really need to understand syntax and meaning to just search its database for words and phrases associated with the words and phrases in the clue? How did Waston's approach differ from simple phrase association (with some advanced knowledge of how Jeopardy clues work, such as using the word "this" to mean "blank"), and what would the benefit/drawback have been to taking that approach? (ironicsans)
Watson performs deep parsing on questions and on background content to extract the syntactic structure of sentences (e.g., grammatical and logical structure) and then assign semantics (e.g., people, places, time, organization, actions, relationship etc). Watson does this analysis on the Jeopardy! clue, but also on hundreds of millions of sentences from which it abstracts propositional knowledge about how different things relate to one another. This is necessary to generate plausible answers or to relate an evidentiary passage to a question even if they are expressed with different words or structures. Consider more complex clues like: "A relative of this inventor described him as a boy staring at the tea kettle for an hour watching it boil."
Sometimes, of course, Jeopardy questions are best answered based on the weight of a simple word associations. For example, "Got ___ !" - well if "Milk" occurs mostly frequently in association with this phrase in everything Watson processed, then Watson should answer "Milk". It"s a very quick and direct association based on the frequency of exposure to that context.
Other questions require a much deeper analysis. Watson has to try many different techniques, some deeper than others, for almost all questions and all at the same time to learn which produces the most compelling evidence. That is how it gets its confidence scores for its best answer. So even the ones that might have been answered based on word-association evidence, Watson also tried to answer other ways requiring much deeper analysis. If word association evidence produced strong evidence (high confidence scores) then that is what Watson goes with. We imagine this is to the way a person might quickly peruse many different paths toward an answer simultaneously but then will provide the answer they are most confident in being correct.
14. In the time it takes a human to even know they are hearing something (about .2 seconds) Watson has already read the question and done several million computations. It's got a huge head start. Do you agree or disagree with that assessment? (robotpirateninja)
The clues are in English -- Brad and Ken's native language; not Watson's. Watson must calculate its response in 2-3 seconds and determine if it's confident enough to buzz in, because as you know, you lose money if you buzz in and respond incorrectly. This is a huge challenge, especially because humans tend to know what they know and know what they don't know. Watson has to do thousands of calculations before it knows what it knows and what it doesn't. The calculating of confidence based on evidence is a new technological capability that is going to be very significant in helping people in business and their personal lives, as it means a computer will be able to not only provide humans with suggested answers, but also provide an explanation of where the answers came from and why they seem correct. This will further human ability to make decisions.