SQL Server хранит информацию обо всех объектах и их свойствах в виде метаданных, доступ к которым возможен через системные представления. Кроме того, некоторые из системных представлений скрывают в себе интересные нюансы, позволяющие лучше понять как устроена DBMS.
Чтобы просмотреть тело системного преставления, как впрочем и любого другого скриптового объекта, применяют функцию - OBJECT_DEFINITION :
PRINT OBJECT_DEFINITION(OBJECT_ID('sys.objects'))
Однако, у OBJECT_DEFINITION , также как и у ее аналога sp_helptext , есть существенный недостаток - с их помощью нельзя вернуть скриптовое описание для табличного объекта.
IF OBJECT_ID('dbo.Table1', 'U') IS NOT NULL DROP TABLE dbo.Table1 GO CREATE TABLE dbo.Table1 (ColumnID INT PRIMARY KEY) GO EXEC sys.sp_helptext 'dbo.Table1' SELECT OBJECT_DEFINITION(OBJECT_ID('dbo.Table1', 'U'))
При выполнении sp_helptext мы получим ошибку:
Msg 15197, Level 16, State 1, Procedure sp_helptext, Line 107
There is no text for object 'dbo.Table1'.
При тех же условиях, системная функция OBJECT_DEFINITION вернет NULL .
Также не решит проблемы выборка из sys.sql_modules , поскольку внутри этого системного представления используется все тот же вызов функции OBJECT_DEFINITION :
CREATE VIEW sys.sql_modules AS SELECT object_id = o.id, definition = object_definition(o.id), ... FROM sys.sysschobjs o
Такое поведение весьма печально, поскольку для некоторых сценариев, бывает полезно получить скриптовое описание таблицы. Что ж, заглянем в системные представления и создадим аналог функции OBJECT_DEFINITION для работы с табличными объектами.
Для начала, создадим тестовую таблицу, чтобы процесс написания скрипта был более наглядным:
IF OBJECT_ID('dbo.WorkOut', 'U') IS NOT NULL DROP TABLE dbo.WorkOut GO CREATE TABLE dbo.WorkOut ( WorkOutID BIGINT IDENTITY(1,1) NOT NULL, TimeSheetDate AS DATEADD(DAY, -(DAY(DateOut) - 1), DateOut), DateOut DATETIME NOT NULL, EmployeeID INT NOT NULL, IsMainWorkPlace BIT NOT NULL DEFAULT 1, DepartmentUID UNIQUEIDENTIFIER NOT NULL, WorkShiftCD NVARCHAR(10) NULL, WorkHours REAL NULL, AbsenceCode VARCHAR(25) NULL, PaymentType CHAR(2) NULL, CONSTRAINT PK_WorkOut PRIMARY KEY CLUSTERED (WorkOutID) ) GO
И приступим к первому шагу - получение списка столбцов и их свойств:
В принципе, получить список столбцов можно простым обращением к одному из нескольких системных представлений. При этом важно делать выборку из наиболее легких системных представлений, чтобы время выполнения запроса было минимальным.
Приведу пару примеров вместе с планами их выполнения, сделанных в dbForge Studio for SQL Server:
--#1 SELECT * FROM INFORMATION_SCHEMA.COLUMNS c WHERE c.TABLE_SCHEMA = 'dbo' AND c.TABLE_NAME = 'WorkOut'
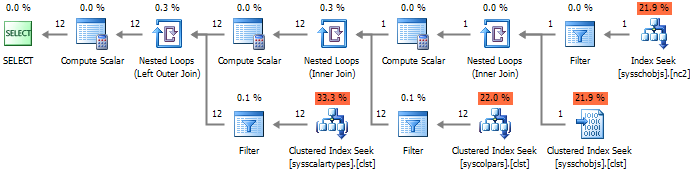
--#2 SELECT c.* FROM sys.columns c WITH(NOLOCK) JOIN sys.tables t WITH(NOLOCK) ON c.[object_id] = t.[object_id] JOIN sys.schemas s WITH(NOLOCK) ON t.[schema_id] = s.[schema_id] WHERE t.name = 'WorkOut' AND s.name = 'dbo'
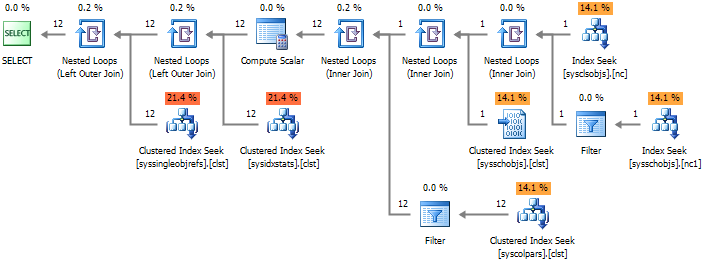
--#3 SELECT * FROM sys.columns c WITH(NOLOCK) WHERE OBJECT_NAME(c.[object_id]) = 'WorkOut' AND OBJECT_SCHEMA_NAME(c.[object_id]) = 'dbo'
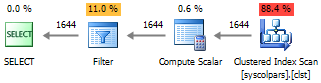
--#4 SELECT * FROM sys.columns c WITH(NOLOCK) WHERE c.[object_id] = OBJECT_ID('dbo.WorkOut', 'U')
Из представленных планов выполнения видно, что варианты #1 и #2 содержат избыточное количество соединений, которые увеличивают время выполнения запроса, при этом #3 подход приводит к полному сканированию индекса, что делает его наименее эффективным из всех.
С точки зрения производительности, для меня наиболее привлекательным остается #4 вариант.
Однако, данные которые содержатся sys.columns (как впрочем и в INFORMATION_SCHEMA.COLUMNS ) не достаточно, чтобы полностью описать табличную структуру. Это вынуждает выполнять соединения с другими системными представлениями:
SELECT c.name , [type_name] = tp.name , type_schema_name = s.name , c.max_length , c.[precision] , c.scale , c.collation_name , c.is_nullable , c.is_identity , ic.seed_value , ic.increment_value , computed_definition = cc.[definition] , default_definition = dc.[definition] FROM sys.columns c WITH(NOLOCK) JOIN sys.types tp WITH(NOLOCK) ON c.user_type_id = tp.user_type_id JOIN sys.schemas s WITH(NOLOCK) ON tp.[schema_id] = s.[schema_id] LEFT JOIN sys.computed_columns cc WITH(NOLOCK) ON c.[object_id] = cc.[object_id] AND c.column_id = cc.column_id LEFT JOIN sys.identity_columns ic WITH(NOLOCK) ON c.[object_id] = ic.[object_id] AND c.column_id = ic.column_id LEFT JOIN sys.default_constraints dc WITH(NOLOCK) ON dc.[object_id] = c.default_object_id WHERE c.[object_id] = OBJECT_ID('dbo.WorkOut', 'U')
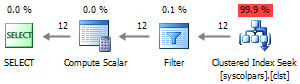
Соотвественно, план выполнения станет выглядеть не таким жизнерадостным, как прежде. Если обратить внимание, то список столбцов у нас, вообще, вычитывает трижды:
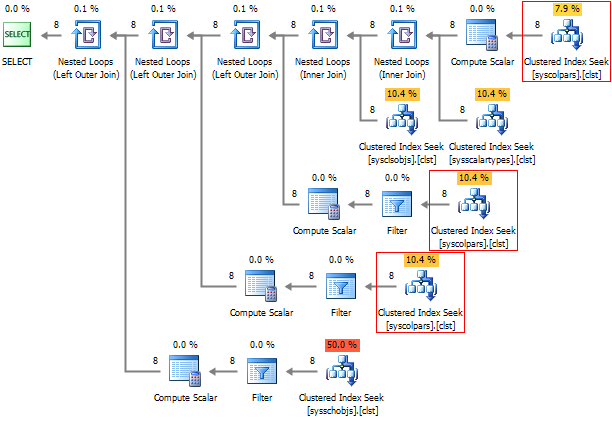
Заглянем внутрь sys.default_constraints :
ALTER VIEW sys.default_constraints AS SELECT name, object_id, parent_object_id, ... object_definition(object_id) AS definition, is_system_named FROM sys.objects$ WHERE type = 'D ' AND parent_object_id > 0
Внутри системного представления можно увидеть вызов OBJECT_DEFINITION , соответственно, чтобы получить описание дефолтного констрейнта нам необязательно делать соединение.
В sys.computed_columns используется все та же OBJECT_DEFINITION :
ALTER VIEW sys.computed_columns AS SELECT object_id = id, name = name, column_id = colid, system_type_id = xtype, user_type_id = utype, ... definition = object_definition(id, colid), ... FROM sys.syscolpars WHERE number = 0 AND (status & 16) = 16 -- CPM_COMPUTED AND has_access('CO', id) = 1
Получается, что от двух соединений мы уже избавились. С sys.identity_columns ситуация более интересная:
ALTER VIEW sys.identity_columns AS SELECT object_id = id, name = name, column_id = colid, system_type_id = xtype, user_type_id = utype, ... seed_value = IdentityProperty(id, 'SeedValue'), increment_value = IdentityProperty(id, 'IncrementValue'), last_value = IdentityProperty(id, 'LastValue'), ... FROM sys.syscolpars WHERE number = 0 -- SOC_COLUMN AND (status & 4) = 4 -- CPM_IDENTCOL AND has_access('CO', id) = 1
Для получения информации о свойствах IDENTITY применяется недокументированная функция IDENTITYPROPERTY . В результате проверки, было установлено ее неизменное поведение на 2005 версии SQL Server и выше.
В результате вызова этих функций напрямую, запрос на получение списка столбцов заметно упроститься:
SELECT c.name , [type_name] = tp.name , type_schema_name = s.name , c.max_length , c.[precision] , c.scale , c.collation_name , c.is_nullable , c.is_identity , seed_value = CASE WHEN c.is_identity = 1 THEN IDENTITYPROPERTY(c.[object_id], 'SeedValue') END , increment_value = CASE WHEN c.is_identity = 1 THEN IDENTITYPROPERTY(c.[object_id], 'IncrementValue') END , computed_definition = OBJECT_DEFINITION(c.[object_id], c.column_id) , default_definition = OBJECT_DEFINITION(c.default_object_id) FROM sys.columns c WITH(NOLOCK) JOIN sys.types tp WITH(NOLOCK) ON c.user_type_id = tp.user_type_id JOIN sys.schemas s WITH(NOLOCK) ON tp.[schema_id] = s.[schema_id] WHERE c.[object_id] = OBJECT_ID('dbo.WorkOut', 'U')
Да и план выполнения станет более лояльным:
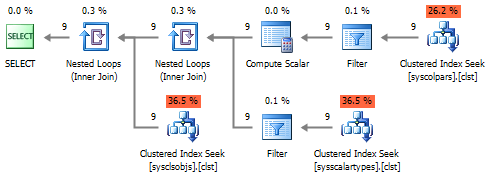
В завершение можно вместо соединения с sys.schemas делать вызов системной функции SCHEMA_NAME , которая отрабатывает заметно быстрее соединения. Это утверждение верно, при условии, если количество схем не превышает количество пользовательских объектов. А поскольку такая ситуация маловероятна - ею можно пренебречь.
Далее получим список столбцов входящих в состав первичного ключа. Самый очевидный вариант - обращение к sys.key_constraints :
SELECT pk_name = kc.name , column_name = c.name , ic.is_descending_key FROM sys.key_constraints kc WITH(NOLOCK) JOIN sys.index_columns ic WITH(NOLOCK) ON kc.parent_object_id = ic.object_id AND ic.index_id = kc.unique_index_id JOIN sys.columns c WITH(NOLOCK) ON ic.[object_id] = c.[object_id] AND ic.column_id = c.column_id WHERE kc.parent_object_id = OBJECT_ID('dbo.WorkOut', 'U') AND kc.[type] = 'PK'
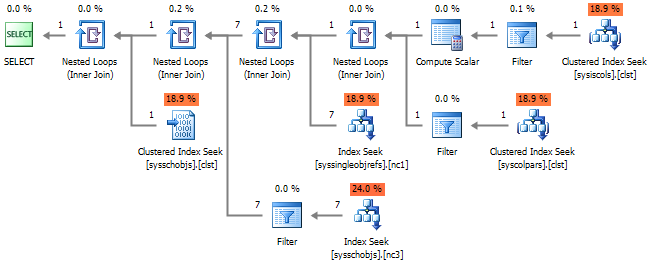
Если вспомнить теорию, то PRIMARY KEY - это кластерный индекс и ограничение Unique .
На уровне метаданных, SQL Server для всех кластерных индексов задает index_id равный 1, поэтому можно сделать выборку из sys.indexes фильтруя по is_primary_key = 1 .
Дополнительно, что избавится от соединения с sys.columns , можно использовать системную функцию COL_NAME :
SELECT pk_name = i.name , column_name = COL_NAME(ic.[object_id], ic.column_id) , ic.is_descending_key FROM sys.indexes i WITH(NOLOCK) JOIN sys.index_columns ic WITH(NOLOCK) ON i.[object_id] = ic.[object_id] AND i.index_id = ic.index_id WHERE i.is_primary_key = 1 AND i.[object_id] = object_id('dbo.WorkOut', 'U')
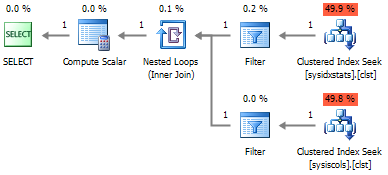
Теперь объедим полученные выборки в одну и получим следующий запрос:
DECLARE @object_name SYSNAME , @object_id INT , @SQL NVARCHAR(MAX) SELECT @object_name = '[' + OBJECT_SCHEMA_NAME(o.[object_id]) + '].[' + OBJECT_NAME([object_id]) + ']' , @object_id = [object_id] FROM (SELECT [object_id] = OBJECT_ID('dbo.WorkOut', 'U')) o SELECT @SQL = 'CREATE TABLE ' + @object_name + CHAR(13) + '(' + CHAR(13) + STUFF(( SELECT CHAR(13) + ' , [' + c.name + '] ' + CASE WHEN c.is_computed = 1 THEN 'AS ' + OBJECT_DEFINITION(c.[object_id], c.column_id) ELSE CASE WHEN c.system_type_id != c.user_type_id THEN '[' + SCHEMA_NAME(tp.[schema_id]) + '].[' + tp.name + ']' ELSE '[' + UPPER(tp.name) + ']' END + CASE WHEN tp.name IN ('varchar', 'char', 'varbinary', 'binary') THEN '(' + CASE WHEN c.max_length = -1 THEN 'MAX' ELSE CAST(c.max_length AS VARCHAR(5)) END + ')' WHEN tp.name IN ('nvarchar', 'nchar') THEN '(' + CASE WHEN c.max_length = -1 THEN 'MAX' ELSE CAST(c.max_length / 2 AS VARCHAR(5)) END + ')' WHEN tp.name IN ('datetime2', 'time2', 'datetimeoffset') THEN '(' + CAST(c.scale AS VARCHAR(5)) + ')' WHEN tp.name = 'decimal' THEN '(' + CAST(c.[precision] AS VARCHAR(5)) + ',' + CAST(c.scale AS VARCHAR(5)) + ')' ELSE '' END + CASE WHEN c.collation_name IS NOT NULL AND c.system_type_id = c.user_type_id THEN ' COLLATE ' + c.collation_name ELSE '' END + CASE WHEN c.is_nullable = 1 THEN ' NULL' ELSE ' NOT NULL' END + CASE WHEN c.default_object_id != 0 THEN ' CONSTRAINT [' + OBJECT_NAME(c.default_object_id) + ']' + ' DEFAULT ' + OBJECT_DEFINITION(c.default_object_id) ELSE '' END + CASE WHEN cc.[object_id] IS NOT NULL THEN ' CONSTRAINT [' + cc.name + '] CHECK ' + cc.[definition] ELSE '' END + CASE WHEN c.is_identity = 1 THEN ' IDENTITY(' + CAST(IDENTITYPROPERTY(c.[object_id], 'SeedValue') AS VARCHAR(5)) + ',' + CAST(IDENTITYPROPERTY(c.[object_id], 'IncrementValue') AS VARCHAR(5)) + ')' ELSE '' END END FROM sys.columns c WITH(NOLOCK) JOIN sys.types tp WITH(NOLOCK) ON c.user_type_id = tp.user_type_id LEFT JOIN sys.check_constraints cc WITH(NOLOCK) ON c.[object_id] = cc.parent_object_id AND cc.parent_column_id = c.column_id WHERE c.[object_id] = @object_id ORDER BY c.column_id FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 7, ' ') + ISNULL((SELECT ' , CONSTRAINT [' + i.name + '] PRIMARY KEY ' + CASE WHEN i.index_id = 1 THEN 'CLUSTERED' ELSE 'NONCLUSTERED' END +' (' + ( SELECT STUFF(CAST(( SELECT ', [' + COL_NAME(ic.[object_id], ic.column_id) + ']' + CASE WHEN ic.is_descending_key = 1 THEN ' DESC' ELSE '' END FROM sys.index_columns ic WITH(NOLOCK) WHERE i.[object_id] = ic.[object_id] AND i.index_id = ic.index_id FOR XML PATH(N''), TYPE) AS NVARCHAR(MAX)), 1, 2, '')) + ')' FROM sys.indexes i WITH(NOLOCK) WHERE i.[object_id] = @object_id AND i.is_primary_key = 1), '') + CHAR(13) + ');' PRINT @SQL
Который при выполнении будет генерировать следующий скрипт для нашей таблицы:
CREATE TABLE [dbo].[WorkOut] ( [WorkOutID] [BIGINT] NOT NULL IDENTITY(1,1) , [TimeSheetDate] AS (dateadd(day, -(datepart(day,[DateOut])-(1)),[DateOut])) , [DateOut] [DATETIME] NOT NULL , [EmployeeID] [INT] NOT NULL , [IsMainWorkPlace] [BIT] NOT NULL DEFAULT ((1)) , [DepartmentUID] [UNIQUEIDENTIFIER] NOT NULL , [WorkShiftCD] [NVARCHAR](10) COLLATE Cyrillic_General_CI_AI NULL , [WorkHours] [REAL] NULL , [AbsenceCode] [VARCHAR](25) COLLATE Cyrillic_General_CI_AI NULL , [PaymentType] [CHAR](2) COLLATE Cyrillic_General_CI_AI NULL , CONSTRAINT [PK_WorkOut] PRIMARY KEY CLUSTERED ([WorkOutID]) );
PS: Генерация скриптового описания таблицы разумеется не ограничивается списком столбов и первичным ключем.