Использование технологий Microsoft в системе "FinExpert хранилище данных" компании IDM
В 2002 году корпорация Microsoft выпустила SQL Accelerator For BI - набор инструментов для построения решений, использующих OLAP и информационные хранилища. Напомним, что в его состав входят сервер баз данных SQL Server, аналитические OLAP-службы для многоразмерного анализа Analysis Services, службы сбора, преобразования и загрузки данных Data Transformation Services (DTS), а также средства поиска закономерностей в данных и графические интерфейсы. Но для реализации конкретной бизнес-задачи при применении SQL Accelerator все равно требуется участие программистов, что мы и хотим показать на примере системы "Хранилище данных" от компании IDM.
Технологическая основа
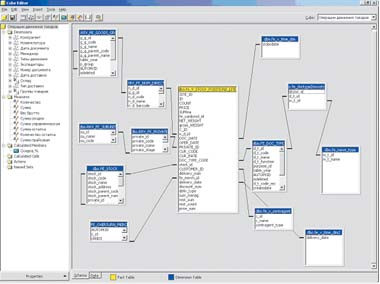
В качестве сервера базы данных хранилища используется Microsoft SQL Server 2000 SP3, хотя ничто не мешает задействовать и другие СУБД. В качестве OLAP-сервера применяются службы Analysis Services из состава SQL Server. На этапе загрузки данных в промежуточные таблицы хранилища используется технология DTS. Для генерации отчетов применяется генератор отчетов Seagate Crystal Reports 8.5 и компоненты Microsoft Office Web Components (OWC). Общая архитектура системы строится по модульному принципу и делится на несколько подсистем (см. Рисунки 1, 2).
Для построения приложений поддержки принятия решений в системе применяются Analysis Services из пакета SQL Server. При необходимости возможна поддержка и других продуктов класса OLAP - например, ORACLE Express. Однако для этого уже потребуется дополнительная разработка. Пока же технология интеграции приложений IDM в Microsoft Analysis Services позволяет выбрать один из вариантов использования:
- применение объекта Microsoft Excel.Worksheet и вывод его в интерфейсных формах системы с подключением к выбранному OLAP-кубу и автоматическим (программным) либо ручным выбором разрезов и измерений;
- использование HTML-шаблонов, публикуемых из Microsoft Excel, с внедренными диаграммами, для построения отчетных форм по заданным OLAP-кубам (с помощью Microsoft Office Web Components);
- использование генератора отчетов Crystal Reports для получения данных из OLAP-куба и построения фиксированных отчетов, например, на бланках строгой отчетности;
- получение данных на промежуточном прикладном уровне через провайдер OLE DB и MDX-запросы и использование их "внутри" приложений.
Сами OLAP-кубы разрабатываются в стандартном инструменте Microsoft - Analysis Manager - с применением языка MDX. При реализации конкретного проекта можно выбрать, например, структуру данных типа "звезда", поскольку этот подход позволяет минимизировать размер исходной базы данных. Приемлемая скорость работы с кубом достигается за счет максимально полного агрегирования данных и выбора смешанного (HOLAP) способа хранения данных куба.
При переносе данных в промежуточные таблицы базы данных мы использовали DTS. В процессе разработки пакетов нам пришлось столкнуться с рядом проблем, и прежде всего с "привязанностью" готового DTS-пакета к именам серверов, базам данных, таблицам и путям файлов. Конечно, эту проблему можно решить, описав по одному источнику данных для базы источника и приемника, а для остальных таблиц использовать копии (клоны) этих источников. Но в таком случае пакет сможет обрабатывать только одну таблицу в каждый момент времени. При больших же объемах данных представляется более целесообразным описывать несколько физических источников данных (до пяти), так чтобы все таблицы распределялись равномерно по этим открытым источникам, в зависимости от средних (прогнозируемых) объемов содержащихся в них данных. При этом нагрузка на каждое открытое соединение с базой данных должна быть по возможности одинаковой. На практике такой подход позволяет увеличить скорость пересылки данных примерно в 3-4,5 раза - в зависимости от степени распараллеливания.
Использование DTS на удаленных площадках имело два очевидных недостатка:
- требовалось реализовать выгрузку данных на основе написанного "универсального" сценария на VBScript, для того чтобы обеспечить управление выгрузкой через настройки, а не через модификацию DTS-пакета.
- на каждой площадке требовалось наличие DTS Runtime, для чего обычно устанавливался Microsoft SQL Server Desktop Edition (MSDE).
Для устранения этих недостатков процедура выгрузки данных была "вынесена" в самостоятельное консольное приложение, написанное на Visual Basic 6. Таким образом, теперь для выгрузки требуется только наличие Microsoft Data Access Components (MDAC). Примерный внешний вид настроек выгрузки данных приведен в Листинге 1. Как можно заметить, в реестре прописываются фактически фрагменты SQL-предложения, что позволяет задавать список таблиц и правил выгрузки без перекомпиляции приложения или без модификации DTS-пакета.
При реализации системы "Хранилище данных" в качестве основного средства разработки мы использовали Microsoft Visual Basic 6 из комплекта Microsoft Visual Studio 6 SP5. Некоторые компоненты, например COM-интерфейсы, были реализованы на VC++ 6 при помощи ATL.
Для проектирования (описания) структуры баз данных и генерации SQL-сценариев создания баз данных применялось CASE-средство CA ERWin 4.1 в сочетании с репозитарием для коллективной разработки ModelMart 4.1.
"НОУ-ХАУ" от компании IDM
Одной из основных задач системы является обеспечение получения целостной картины из разрозненных наборов данных. Как известно, большинство предприятий на просторах бывшего СНГ не имеют единых корпоративных справочников, поэтому, даже если собрать информацию из подразделений в центре, ее нельзя будет адекватно сопоставить, и уж тем более консолидировать. Эта проблема решается при помощи подсистемы подстановки соответствий.
Процесс подстановки соответствий подразумевает замену всех полей ссылок (relationships fields) разрозненных записей, поступивших с разных площадок, а следовательно, основанных на разных версиях справочников (возможно, продуцированных различными системами), на ссылки на записи так называемых корпоративных справочников хранилища. Процедура подстановки соответствий выполняется в виде пакета (на всем множестве записей промежуточной таблицы), однако должна отработать для каждой ссылки каждой записи, импортированной в промежуточные таблицы хранилища.
Очевидно, что при такой постановке задач наиболее логичным представляется использование так называемых предметных идентификаторов записей, т. е. поиск ID записи справочника по набору предметных полей, однозначно идентифицирующих сущность, которую представляет запись справочника. Например, для контрагента такими наборами могут быть "код контрагента" или набор "код банка" + "номер счета в этом банке". Для того чтобы данная операция была возможной, каждая запись должна содержать избыточную информацию, которой и являются предметные поля из справочника.
С технической точки зрения процесс подстановки соответствий представляет собой выполнение массированных модификаций записей промежуточных таблиц. Для каждой ссылки между двумя таблицами описывается правило подстановки соответствия, которое определяет, по соответствию каких полей промежуточной таблицы и справочника в какое поле промежуточной таблицы попадает ключ записи справочника. Кроме того, учитываются так называемые "ручные" правила соответствий, которые представляют собой своего рода исключения из общего правила. "Ручные" правила обрабатываются для каждого правила в первую очередь и имеют более высокий приоритет, чем автоматические.
 |
| Рисунок 3. Пример OLAP-куба, разработанного для конфигурации "Торговый дом" |
Процесс подстановки автоматических соответствий разделяется на два этапа. На первом этапе из справочника во временную таблицу извлекаются столбцы, задействованные в правиле. Затем, в зависимости от настроек системы, удаляются дубликаты по полям соответствий (может быть оставлена запись из числа дубликатов с минимальным значением PK - это определяется настройкой). Кроме того, из временной таблицы удаляются записи, одно или более полей которых пусты (Рисунок 4). На втором этапе осуществляется подстановка соответствий в промежуточную таблицу (Рисунок 5). Подстановка выполняется для записей, для которых отработали все предыдущие правила. Признак успешной отработки очередного правила для определенной записи промежуточной таблицы - увеличение на единицу значения в служебном поле confset этой записи.
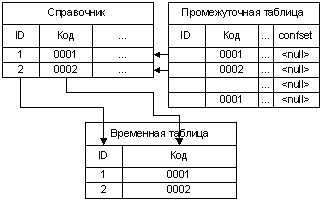 |
| Рисунок 4. Схема удаления записей |
После того как процесс подстановки для таблицы завершен, записи, для которых выполнены подстановки по всем заданным правилам, могут быть перенесены в основные таблицы хранилища. Записи, для которых по каким-либо причинам не выполнялась подстановка хотя бы по одному правилу, остаются в промежуточных таблицах до того момента, когда пользователь устранит причину "отсутствия" соответствующих ссылок.
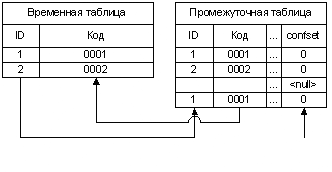 |
| Рисунок 5. Схема подстановки соответствий |
Настройка правил установки соответствий проводится в два этапа: на первом этапе задаются автоматические правила соответствия (фактически правила поиска соответствий), на втором, при необходимости, задаются "ручные" соответствия для записей ("прямые" соответствия типа запись-запись), которые не могут по каким-либо причинам обрабатываться автоматическими правилами. Как автоматические, так и "ручные" правила соответствия предназначены для обеспечения поддержания ссылочной целостности записей, поступающих из различных источников.
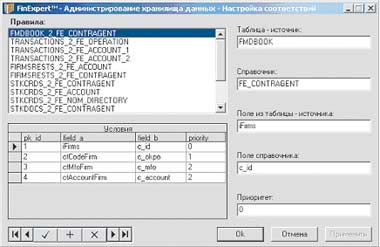 |
| Рисунок 6. Настройка автоматических правил соответствия |
Правило соответствия устанавливается отдельно для каждой ссылки таблицы фактов хранилища. В правиле можно указать несколько условий (т. е. соответствий конкретных полей), при выполнении одного из которых запись считается обработанной по данному правилу. Порядок применения условий в рамках правила определяется его приоритетом (чем меньше приоритет, тем раньше применяется условие). Можно задать условие более чем по одному полю - для этого нужно просто указать одинаковые значения приоритета для различных условий, в таком случае условия объединяются по оператору "И" (AND). Настройка "ручных" правил соответствия выполняется на уровне отдельных записей.
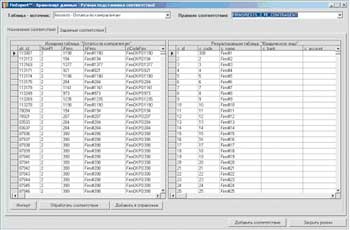 |
| Рисунок 7. Назначение соответствий вручную |
Подсистема генерации статистических отчетов реализована на базе генератора отчетов Crystal Reports. Данная подсистема позволяет пользователям получать статистические отчеты непосредственно по данным хранилища, в том числе и без применения других подсистем, как-то: OLAP-подсистема, Web-подсистема и др.
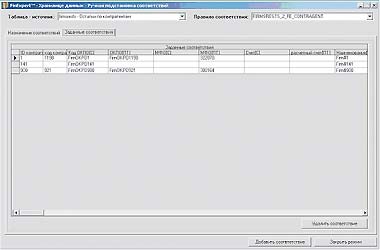 |
| Рисунок 8. Заданные ручные соответствия |
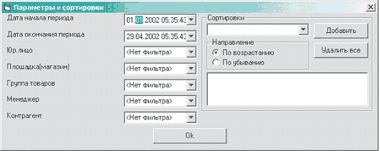 |
| Рисунок 9. Динамически формируемая форма запроса параметров для построения отчета |
Подсистема для работы со справочниками (см. Рисунок 10) была бы стандартной, если бы не списки (grids) и экранные формы для каждого справочника, которые не создаются программистом, а конструируются "на ходу", по выбранным таблицам и метаданным (наименования полей на русском языке и т. д.). Кроме того, производится отслеживание полей-ссылок и замена стандартных полей ввода на выпадающие списки (определение ссылок выполняется при помощи стандартной информации, хранящейся в системных таблицах, естественно "обернутой" в представление; код представления см. в Листинге 2).
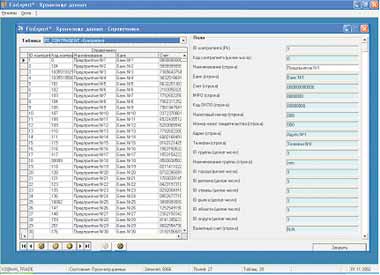 |
| Рисунок 10. Редактирование корпоративного справочника контрагентов |
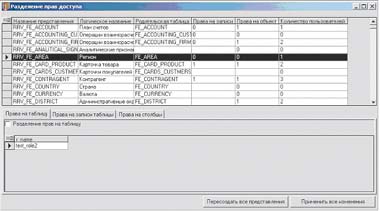 |
| Рисунок 11. Внешний вид окна режима настройки доступа по таблицам |
При этом также отслеживаются типы полей, ограничения на их длину, обязательность для заполнения и т. д. Это позволяет, в частности, добавлять новые справочники в систему без какого-либо программирования, путем настроек в модуле "Администратор системы".
Настройки системы и безопасность
Настройки системы "Хранилище данных" хранятся в реестре Windows. Для редактирования настроек предусмотрен специальный инструмент с удобным интерфейсом, чтобы не приходилось пользоваться программой RegEdit (что, как правило, ведет к ошибкам при настройке и серьезным проблемам, вплоть до порчи системного реестра). Средства обеспечения безопасности системы интегрированы со средствами безопасности SQL Server - используется аутентификация (поддерживаются режимы как Windows, так и Integrated Security). Подсистема разделения прав доступа использует механизм ролей (roles) SQL Server. Данная подсистема реализована на основании механизмов SQL Server - пользователей и ролей (roles). Разделение доступа к данным таблиц построчно производится с помощью механизма управляемых представлений (controlled views; см. Листинг 3).
На сегодня в системе поддерживаются следующие уровни назначения разрешений доступа (см. Рисунки 11, 12):
- доступ на уровне сущностей (таблиц, представлений), реализованный с помощью управляемых представлений и внутренней настроечной таблицы;
- доступ на уровне строк таблиц и представлений, реализованный с помощью управляемых представлений и внутренних настроечных таблиц.
Сохранение настроек в собственных настроечных таблицах позволяет:
- более гибко настраивать разрешения (особенно на отдельные записи);
- гарантировать восстановление корректной работы системы и подсистемы разрешений хранилища в случае практически любых сбоев аппаратных и/или программных средств системы.
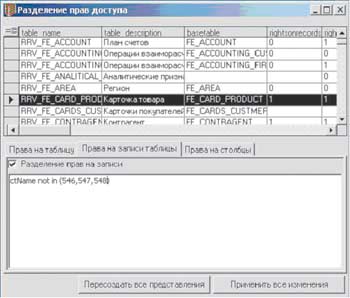 |
| Рисунок 12. Внешний вид окна режима настройки доступа по строкам таблиц |
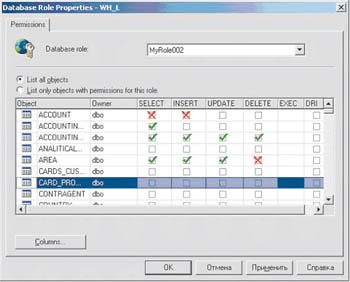 |
| Рисунок 13. Настроенные из приложения "Администратор системы" права доступа к таблицам при просмотре их средствами SQL Server |
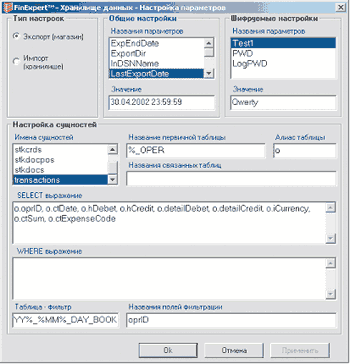 |
| Рисунок 14. Утилита настройки параметров (выгрузка) |
В системе предусмотрена возможность добавлять новые источники данных для хранилища постепенно. Эта процедура выполняется на уровне настроек системы, т. е. без изменения ее компонентов. Для настройки сущностей - источников данных - в системе предусмотрена специальная утилита (см. Рисунок 14). При настройке сущностей можно задать параметры, необходимые для переноса данных из таблицы-источника в таблицу-приемник (наименования сущностей, поля таблицы источника и соответствующие поля приемника, условия выборки). Кроме того, можно задать условие выгрузки с учетом наличия связанной таблицы, т. е. выгрузить только те записи, для которых имеются соответствующие в другой выгружаемой таблице; такое условие применяется с учетом периодов фиксации обеих таблиц. Фактически настройки выгрузки представляют собой указание таблиц и полей для выгрузки, а также некоторых условий выгрузки в формате фрагментов SQL-запросов.
После выполнения процедуры подстановки соответствий данные могут быть перенесены из промежуточных таблиц в основные таблицы хранилища. В этом процессе принимают участие записи, для которых успешно применены все заданные правила соответствий. Настройка алгоритма переноса данных выполняется для каждой промежуточной таблицы индивидуально средствами системы (см. Рисунок 15). Как показано на рисунке, настройка переноса данных фактически представляет собой SQL-запросы, которые будут выполняться системой при переносе данных для каждой таблицы.
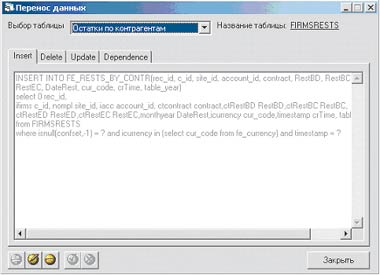 |
| Рисунок 15. Настройка переноса данных. |
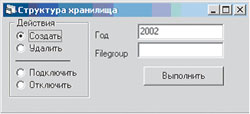 |
| Рисунок 16. Управление разделением |
При стремительном накоплении объемов данных в хранилище рано или поздно возникает вопрос, где хранить уже неактуальную на текущий момент информацию. Почему бы не вынести такую информацию на внешний носитель, "разгрузив" ресурсы сервера? Для обеспечения такой возможности в нашей системе реализована схема использования технологии разделяемых представлений SQL Server. Данные таблиц фактов за каждый год хранятся в отдельных файловых группах данных базы данных, что позволяет "отключать" и по мере необходимости "включать" их в представления, реализованные "поверх" этих таблиц фактов. Операции "включения" и "исключения" могут осуществляться администратором при помощи одного из режимов системы (см. Рисунок 16).
Например, имеется две таблицы, FE_ORDERS_POS_2002 и FE_ORDERS_POS_2003, располагающиеся в разных файловых группах SQL Server. Для работы с ними создается разделяемое представление, показанное в Листинге 4. Таблицы FE_ORDERS_POS_NNNN должны формироваться в разных файловых группах SQL Server (см. Рисунок 17). Код создания триггера обработки команды INSERT для этого представления (представления и коды триггеров формируются автоматически) показан в Листинге 5. Подобные же триггеры создаются и для операций UPDATE, DELETE. Таким образом, приложение работает с одной таблицей FE_ORDERS_POS, "не задумываясь" о том, что реально данные находятся в нескольких разделяемых таблицах.
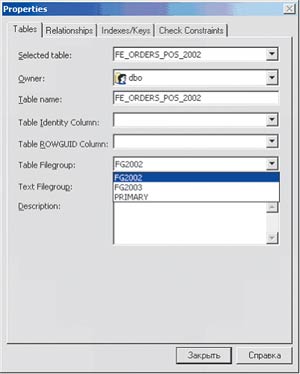 |
| Рисунок 17. Назначение файловой группы для разделяемой таблицы. |
Реализация схемы разделения в системе повлекла за собой необходимость разработки собственной схемы генерации автоинкрементных первичных ключей, поскольку поля с признаком IDENTITY для разделяемых таблиц не поддерживаются. Эта схема реализуется при помощи триггеров и нескольких вспомогательных таблиц. При реализации такой схемы основное внимание уделялось повышению быстродействия при выполнении пакетной вставки больших массивов данных. Для этого использовались временные таблицы со структурой, соответствующей структуре "базовой" таблицы, за исключением поля - суррогатного первичного ключа: для него был выбран стандартный автоинкремент SQL Server с динамически задаваемым диапазоном. В Листинге 6 приведен пример триггера для генерации автоинкрементного первичного ключа.
Сын ошибок трудных
Как показывает практика, данные чаще всего приходится получать из весьма несовершенных систем и СУБД. Причина проста и прозаична - как правило, основным критерием при покупке OLTP-системы является ее функциональность. А самая богатая функциональность обычно бывает у тех систем, которые разрабатываются давно и несут изрядный груз устаревших технических решений. К тому же для корректной обработки данных желательно соблюдать ряд требований в отношении данных системы-источника:
- наличие в каждой таблице уникального ключа для идентификации записи (можно суррогатного ключа, можно - натурального);
- ведение штампа времени изменения каждой записи;
- ведение протокола удаленных записей.
В принципе, возможна эксплуатация решений для хранилищ данных и без наличия такой функциональности в системах - источниках данных, однако это приведет к возрастанию объема передаваемых данных либо к невозможности корректного отслеживания удаленных записей. Кроме того, структуры данных различных систем имеют свои особенности, даже при условии автоматизации одной и той же предметной области. Отсюда рекомендации - строить решение для выгрузки данных на основании средств, предусматривающих возможность максимально детализированной настройки, например хранения фрагментов SQL-выражений на компьютере, где производится выгрузка данных.
Далее, как известно, максимальное количество таблиц в одном SQL-запросе для SQL Server 2000 равно 256. Казалось бы, это довольно много. Однако не следует забывать, что если в запросе участвуют представления, то в число используемых в нем таблиц входят все таблицы, применяемые в данном представлении. В нашем случае при использовании разделяемого представления ситуация осложняется тем, что при достаточно нормализованной схеме данных количество таблиц в запросе приходится умножать на количество лет, за которое хранится информация в разделе. Если в запросе одна и та же таблица подключается несколько раз, с разными псевдонимами, то она "считывается" также несколько раз. В результате для сложных таблиц данных с большим количеством справочников "упереться" в ограничение в 256 таблиц можно буквально за два-три года.
В принципе с такой проблемой мы столкнулись только в отчетах, которые строятся непосредственно по базе данных хранилища и интегрируют данные за достаточно длительный период либо содержат столбцы, вычисляемые отдельными подзапросами по периодам. Выход из подобного положения довольно прост: для каждого такого отчета создается хранимая процедура, в которой пошагово наполняется некая временная таблица. По окончании выполнения процедура возвращает вызвавшему модулю набор строк, содержащий строки этой временной таблицы. Таким образом, один большой запрос мы разбиваем на ряд мелких, в каждом из которых менее 256 таблиц.
В этой статье мы попытались обобщить опыт, полученный при решении классической задачи OLAP - хранилище данных на протяжении нескольких последних лет. Надеемся, что она будет интересна как специалистам компаний, разрабатывающим готовые решения, так и сотрудникам ИT-подразделений корпораций. Для тех, кто хотел бы больше узнать о решаемых бизнес-задачах и функциональности системы, рекомендуем обратиться к статьям, приведенным в списке "Литература". Для пополнения теоретического багажа в области технологий OLAP&Warehousing можно обратиться к ресурсам сайта http://www.olap.ru .
Литература
- Банасевич А., Гурленко А. Хранилища данных и OLAP//Корпоративные системы, Киев, 2002, № 4, с. 44-51.
- Банасевич А., Кудинов А. От Informix - к SQL Server//Открытые системы, январь 2002, рубрика СУБД, с. 55-61.
- Муравьев В., Банасевич А. Использование технологий INFORMIX в ERP-системе FinExpert. 8.0//INFORMIX Magazine/русское издание, лето 2001, рубрика "Проекты и приложения", с. 23-27.
- Пресс-релиз "Хранилища данных и технологии OLAP для обработки информации"//Office, 2002, №5 (52), с. 77 (см. также http://www.finexpert.com/News/Presrel/ hdolappr.html ).
- Муравьев В., Банасевич А. Технологические решения в управлении предприятием//Корпоративные системы, 2000, № 4, рубрика "Отраслевые решения", с. 27-31.
- Пресс-релиз "Cистема FinExpert(tm) 8.0 компании IDM переведена на платформу СУБД Microsoft SQL Server 2000", http://www.microsoft.com/rus/General/Press/ 2001/june/FinExpert.htm .
- Использование современных технологий корпорации Microsoft в системе автоматизации управления предприятием FinExpert(tm) 8.0//Материалы совместного семинара компаний IDM и Microsoft на выставке "Управление предприятием-2001", 6.12.2001.
- Семинар Тройственного союза компаний//Материалы совместного семинара компаний IDM, Microsoft и KPMG на выставке "Управление предприятием-2000", 2.11.2000, http://idm.kiev.ua/news/index.html (см. также IDM, KPMG и Microsoft провели совместный семинар, http://itc-ua.com/article.phtml?ID=4251 ).
- Server 2000 Books Online, Microsoft.