Concepts: Distribution Patterns
Topics
- Nodes, Processors and Devices
- Distribution Patterns
- 'Client/Server Architectures'
- The Peer-to-peer 'Architecture'
Nodes, Processors and Devices 
Processors and Devices are common stereotypes of Node. The distinction between the two may seem difficult to assess, as many devices now contain their own CPUs. However, the distinction between processors and devices lies in the type of software that executes on them. Processors execute programs/software that were explicitly written for the system being developed. Processors are general-purpose computing devices which have computing capacity, memory, and execution capability.
Devices execute software written that controls the functionality of the device itself. Devices are typically attached to a processor that controls the device. They typically execute embedded software and are incapable of running general-purpose programs. Their functionality is typically controlled by device-driver software.
Distribution Patterns
There are a number of typical patterns of distribution in systems, depending on the functionality of the system and the type of application. In many cases, the distribution pattern is informally used to describe the 'architecture' of the system, though the full architecture encompasses this but also many more things. For example, many times a system will be described as having a 'client-server architecture', although this is only the distribution aspect of the architecture. This serves to highlight the importance of the distribution aspects of the system and the extent to which they influence other architectural decisions.
The distribution patterns described below imply certain system characteristics, performance characteristics, and process architectures. Each solves certain problems but also poses unique challenges.
Client/Server Architectures
In so-called "client/server architectures", there are specialized network processor nodes called clients, and nodes called servers. Clients are consumers of services provided by a server. A client often services a single user and often handles end-user presentation services (GUI's), while the server usually provides services to several clients simultaneously; the services provided are typically database, security or print services. The "application logic", or the business logic, in these systems is typically distributed among both the client and the server. Distribution of the business logic is called application partitioning.
In the following figure, Client A shows an example of a 2-tier architecture, with most application logic located in the server. Client B shows a typical 3-tier architecture, with Business Services implemented in a Business Object Server. Client C shows a typical web-based application.
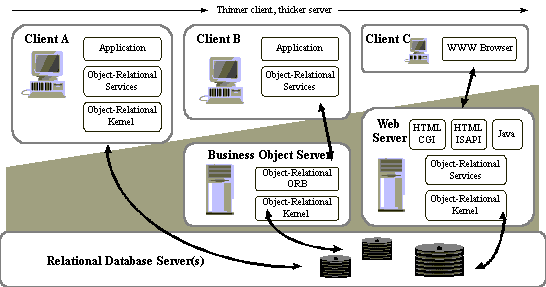
Variations of Client-Server Architectures
In traditional client/server systems, most of the business logic is implemented on clients; but some functionality is better suited to be located on the server, for example functionality that often access data stored on the server. By doing this, one can decrease the network traffic, which in most cases is quite expensive (it is an order of magnitude or two slower than inter-process communication).
Some characteristics:
- A system can consist of several different types of clients, examples of which include:
- User workstations
- Network computers
- Clients and servers communicate by using various technologies, such as CORBA/IDL, or RPC (remote-procedure call) technologies.
- A system can consist of several different types of servers, examples of which include:
- Database servers, handling database machines such as Sybase, Ingres, Oracle, Informix;
- Print servers, handling the driver logic (queuing etc.) for a specific printer;
- Communication servers (TCP/IP, ISDN, X.25),
- Window Manager servers (X)
- File servers (NFS under UNIX).
The
'3-Tier Architecture'
The '3-tier Architecture' is a special case of the 'Client/Server Architecture' in which functionality in the system is divided into 3 logical partitions: application services, business services, and data services. The 'logical partitions' may in fact map to 3 or more physical nodes.
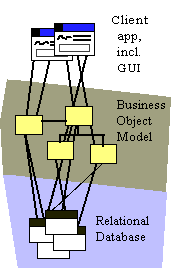
Example of a 3-tier Architecture
The logical partitioning into these three 'tiers' reflects an observation about how functionality in typical office applications tends to be implemented, and how it changes. Application services, primarily dealing with GUI presentation issues, tends to execute on a dedicated desktop workstation with a graphical, windowing operating environment. Changes in functionality tends to be dictated often by ease of use or aesthetic considerations, essentially human factors issues.
Data services tend to be implemented using database server technology, which tends to execute on one or more high-performance, high-bandwidth nodes that serve hundreds or thousands of users, connected over a network. Data services tend to change when the representation and relationships between stored information changes.
Business services reflect encoded knowledge of business processes. They manipulate and synthesize information obtained from the data services, and provide it to the application services. Business services are typically used by many users in common, so they tend to be located on specialized servers as well, though the may reside on the same nodes as the data services.
Partitioning functionality along these lines provides a relatively reliable pattern for scalability: by adding servers and re-balancing processing across data and business servers, a greater degree of scalability is achieved.
The 'Fat Client Architecture'
The client is "Fat" since nearly everything runs on it (except in a variation, called the '2-tier architecture', in which the data services are located on a separate node). Application Services, Business Services and Data Services all reside on client machine; the database server will be usually on another machine.

Traditional 2-tier or "Fat Client" Architecture
'Fat Clients' are relatively simple to design and build, but more difficult to distribute (they tend to be large and monolithic) and maintain. Because the client machines tend to cache data locally for performance, local cache coherency and consistency tend to be issues and areas warranting particular attention. Changes to shared objects located in multiple local caches are difficult and expensive to coordinate, involving as they do network broadcast of changes.
Web
Application
At the other end of the spectrum from the 'Fat Client' is the typical Web Application (which might be characterized as 'Fat Server' or 'Anorexic Client'. Since the client is simply a Web Browser running a set of HTML pages and Java applets, Java Beans or ActiveX components, there is very little application there at all. Nearly all work takes place on one or more web servers and data servers.
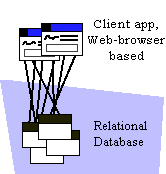
Web Application
Web applications are easy to distribute, easy to change. They are relatively inexpensive to develop and support (since much of the application infrastructure is provided by the browser and the web server). They may however not provide the desired degree of control over the application, and they tend to saturate the network quickly if not well-designed (and sometimes despite being well-designed).
Distributed Client/Server Architecture
In this architecture, the application, business and data services reside on different nodes, potentially with specialization of servers in the business services and data services tiers. A full realization of a 3-tier architecture.
The Peer-to-Peer Architecture
In the peer-to-peer architecture, any process or node in the system may be both client and server. Distribution of functionality is achieved by grouping inter-related services together to minimize network traffic while maximizing throughput and system utilization. Such systems tend to be complex, and there is a greater need to be aware of issues such as dead-lock, starvation between processes, and fault handling.
![]()