© Новичков Александр, Ематин Виктор, Закис Алексей, Шкляева Наталья, Подоляк Ольга
Статья была опубликована на сайте www.citforum.ru
Начать описание возможностей продукта Rational Purify хочется перефразированием одного очень известного изречения: "с точностью до миллиБАЙТА". Данное сравнение не случайно, ведь именно этот продукт направлен на разрешение всех проблем, связанных с утечками памяти. Ни для кого не секрет, что многие программные продукты ведут себя "не слишком скромно", замыкая на себя во время работы все системные ресурсы без большой на то необходимости. Подобная ситуация может возникнуть вследствие нежелания программистов доводить созданный код "до ума", но чаще подобное происходит не из за лени, а из-за невнимательности. Это понятно — современные темпы разработки ПО в условиях жесточайшего прессинга со стороны конкурентов не позволяют уделять слишком много времени оптимизации кода, ведь для этого необходимы и высокая квалификация, и наличие достаточного количества ресурсов проектного времени. Как мне видится, имея в своем распоряжении надежный инструмент, который бы сам в процессе работы над проектом указывал на все черные дыры в использовании памяти, разработчики начали бы его повсеместное внедрение, повысив надежность создаваемого ПО. Ведь и здесь не для кого не секрет, что в большинстве сложных проектов первоочередная задача, стоящая перед разработчиками заключается в замещении стандартного оператора "new" в С++, так как он не совсем адекватно себя ведет при распределении памяти.
Вот на создании\написании собственных велосипедов и позволит сэкономить Purify.
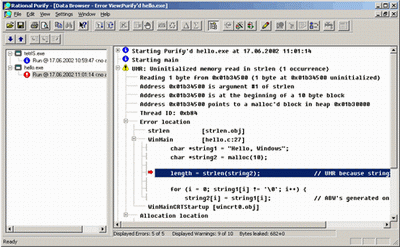
Рисунок демонстрирует внешний вид программы после проведения инструментирования (тестирования) программного модуля.
Общие возможности по управлению Purify схожи с Quantify, за исключением специфики самого продукта. Здесь также можно тестировать многопоточные приложения, также можно делать "слепки" памяти во время тестирования приложения.
Особенности использования данного приложения касаются спецификой отлавливаемых ошибок и способом выдачи информации.
Информация выдается в виде списке, с наименованием найденной ошибки или предупреждения. При разворачивании списка с конкретной ошибкой выводится дополнительный набор данных, характеризующих ошибку.
Работа с Purify возможна как при наличии исходных текстов и отладочной информации, так и без нее. В случае отсутствия debug-информации анализ ошибок ведется только по ip-адресам. Так же как и в случае с Quantify, возможен детальный просмотр функций из dll-библиотек. В этом случае наличие отладочной информации не является необходимостью.
Для того, чтобы иметь представление о возможностях продукта, опишем то, какие ошибки и потенциальные ошибки могут присутствовать в тестируемом приложение.
Отметим разницу между ошибкой и потенциальной ошибкой и опишем:
Естественно, что подобное поведение может быть вызвано спецификой приложения, например, так вести себя может текстовый редактор. Поэтому в Purify применятся деление информации на ошибки и потенциальные ошибки (которые можно воспринимать как специфику).
Список ошибок и потенциальных ошибок достаточно объемен и постоянно пополняется. Кратко опишем основные сообщения, выводимые после тестирования:
Предупреждения и ошибки удобно группировать по определенным признакам, чтобы легче можно было отыскать нужное предупреждение и отбросить ненужные.
Отметим категории и принадлежность к ним различных сообщений:
Многие статические ошибки могут вылавливать компиляторы на этапе разработки программного модуля или приложения. На этом этапе преимущества Purify не очень видны.
Все механизмы анализа ошибок открываются при исполнении приложения, при динамически меняющихся условиях.
Рассмотрим более подробно список отлавливаемых ошибок, определив их принадлежность к категориям с примерами на C++/C:
ABR: Array Bounds Read. Выход за пределы массива при чтении.
Известная болезнь всех разработчиков — неправильно поставленное условие в цикле. Соответственно, ошибка, которая имеет место быть в программе, связанная с чтением лишней информации, может проявить себя, а может и не проявить. Но она является потенциальной ошибкой.
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char *ptr = new char[5];//Выделяем память под массив из 5 символов
ptr[0] = ‘e’;
ptr[1] = ‘r’;
ptr[2] = ‘r’;
ptr[3] = ‘o’;
ptr[4] = ‘r’;
for (int i=0; i <= 5; i++) {
//Ошибка, при i=5 – выход за пределы массива
cerr << "ptr[" << i << "] == " << ptr[i] << '\n';
}
delete[] ptr;
return(0);
}
ABW: Array Bounds Write. Выход за пределы массива при записи
Вероятность того, что приложение может неадекватно вести себя из-за данной ошибки более высоко, так как запись по адресу, превышающим размер блока, вызывает исключение.
Отметим, что память можно определить статически, массовом, как показано в примере. А можно динамически (например, выделив блок памяти по ходу исполнения приложения).
По умолчанию, Purify успешно справляется только с динамическим распределением, четко выводя сообщение об ошибке. В случае статического распределения, все зависит от размеров "кучи" и настроек компилятора.
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char * ptr = new char[5];//Выделяем память под массив из 5символов
for (int i=0; i <= 5; i++) {
//Ошибка, при i=5 - выход за пределы массива
ptr[i] = ‘!’;
cerr << "ptr[" << i << "] == " << ptr[i] << '\n'; //ABW + ABR when i is 5
}
delete[] ptr;
return(0);
}
ABWL: Late Detect Array Bounds Write. Cообщение указывает, что программа записала значение перед началом или после конца распределенного блока памяти
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char * ptr = new char[5];//Выделяем память под массив из 5 символов
for (int i=0; i <= 5; i++) {
//Ошибка – попытка записи после блока выделенной памяти
ptr[i] = ‘!’;
cerr << "ptr[" << i << "] == " << ptr[i] << '\n';
}
delete[] ptr; //ABWL: ОШИБКА
return(0);
}
BSR: Beyond Stack Read. Сообщение указывает, что функция в программе собирается читать вне текущего указателя вершины стека
Категория: Stack Error
#include <windows.h>
#include <iostream.h>
#define A_NUM 100
char * create_block(void)
{
char block[A_NUM];//Ошибка: массив должен быть статическим
for (int i=0; i < A_NUM; i++) {
block[i] = ‘!’;
}
return(block);//Ошибка: неизвестно, что возвращать
}
int main(int, char **)
{
char * block;
block = create_block();
for (int i=0; i < A_NUM; i++) {
//BSR: нет гарантии, что элементы из "create_block" до сих пор находятся в стеке
cerr << "element #" << i << " is " << block[i] << '\n';
}
return(0);
}
FFM: Freeing Freed Memory. Попытка освобождения свободного блока памяти.
В большом приложении трудно отследить момент распределения блока и момент освобождения. Очень часто методы реализуются разными разработчиками, и, соответственно, возможна ситуация, когда распределенный блок памяти освободается дважды в разных участках приложения.
Категория: Allocations and deallocations
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char *ptr1 = new char;
char *ptr2 = ptr1;//Ошибка: должен дублировать объект, а не копировать указатель
*ptr1 = ‘a’;
*ptr2 = ‘b’;
cerr << "ptr1" << " is " << *ptr1 << '\n';
cerr << "ptr2" << " is " << *ptr2 << '\n';
delete ptr1;
delete ptr2;//Ошибка – освобождение незанятой памяти
return(0);
}
FIM: Freeing Invalid Memory. Попытка освобождения некорректного блока памяти.
Разработчики часто путают простые статические значения и указатели, пытаясь освободить то, что не освобождается. Компилятор не всегда способен проанализировать и нейтрализовать данный вид ошибки.
Категория: Allocations and deallocations
#include <iostream.h>
int main(int, char **)
{
char a;
delete[] &a;//FIM: в динамической памяти нет объектов для уничтожения
return(0);
}
FMM: Freeing Mismatched Memory. Сообщение указывает, что программа пробует освобождать память с неправильным ВЫЗОВОМ API для того типа памяти
Категория: Allocations and deallocations
#include <windows.h>
int main(int, char **)
{
HANDLE heap_first, heap_second;
heap_first = HeapCreate(0, 1000, 0);
heap_second = HeapCreate(0, 1000, 0);
char *pointer = (char *) HeapAlloc(heap_first, 0, sizeof(int));
HeapFree(heap_second, 0, pointer);
//Ошибка – во второй куче не выделялась память
HeapDestroy(heap_first);
HeapDestroy(heap_second);
return(0);
}
FMR: Free Memory Read. Попытка чтения уже освобожденного блока памяти
Все та же проблема с указателем. Блок распределен, освобожден, а потом, в ответ на событие, по указателю начинают записываться (или читаться) данные.
Категория: Invalid pointers
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char *ptr = new char[2];
ptr[0] = ‘!’;
ptr[1] = ‘!’;
delete[] ptr;//Ошибка – освобождение выделенной памяти
for (int i=0; i < 2; i++) {
//FMR: Ошибка- попытка чтения освобождённой памяти
cerr << "element #" << i << " is " << ptr[i] << '\n';
}
return(0);
}
FMW: Free Memory Write. Попытка записи уже освобожденного блока памяти
Категория: Invalid pointers
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char *ptr = new char[2];
ptr[0] = ‘!’;
ptr[1] = ‘!’;
delete[] ptr;//специально освобождаем выделенную память
for (int i=0; i < 2; i++) {
ptr[i] *= ‘A’; //FMR + FMW: память для *ptr уже освобождена
cerr << "element #" << i << " is " << ptr[i] << '\n'; //FMR
}
return(0);
}
HAN: Invalid Handle. Операции над неправильным дескриптором
Категория: Invalid handles
#include <iostream.h>
#include <windows.h>
#include <malloc.h>
int main(int, char **)
{
int i=8;
(void) LocalUnlock((HLOCAL)i);//HAN: i – не является описателем объекта памяти
return(0);
}
HIU: Handle In Use. Индикация утечки ресурсов. Неправильная индикация дескриптора.
#include <iostream.h>
#include <windows.h>
static long GetAlignment(void)
{
SYSTEM_INFO desc;
GetSystemInfo(&desc);
return(desc.dwAllocationGranularity);
}
int main(int, char **)
{
const long alignment = GetAlignment();
HANDLE handleToFile = CreateFile("file.txt",
GENERIC_READ|GENERIC_WRITE, 0, NULL, CREATE_ALWAYS,
FILE_ATTRIBUTE_NORMAL, NULL);
if (handleToFile == INVALID_HANDLE_VALUE) {
cerr << "Ошибка открытия, создания файла\n";
return(1);
}
HANDLE handleToMap = CreateFileMapping(handleToFile, NULL, PAGE_READWRITE, 0, alignment, "mapping_file");
if (handleToMap == INVALID_HANDLE_VALUE) {
cerr << "Unable to create actual mapping\n";
return(1);
}
char * ptr = (char *) MapViewOfFile(handleToMap, FILE_MAP_WRITE, 0, 0, alignment);
if (ptr == NULL) {
cerr << "Unable to map into address space\n";
return(1);
}
strcpy(ptr, "hello\n");
//HIU: handleToMap до сих пор доступен и описывает существующий объект
return(0);
}
IPR: Invalid Pointer Read. Ошибка обращения к памяти, когда программа пытается произвести чтение из недоступной области
Категория: Invalid pointers
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char * pointer = (char *) 0xFFFFFFFF;
//Ошибка - указатель на зарезервированную область памяти
for (int i=0; i < 2; i++) {
//IPR: обращение к зарезервированной части адресного пространства
cerr << "pointer[" << i << "] == " << pointer[i] << '\n';
}
return(0);
}
IPW: Invalid Pointer Write. Ошибка обращения к памяти, когда программа пытается произвести запись из недоступной области
Категория: Invalid pointers
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char *pointer = (char *) 0xFFFFFFFF;
//Ошибка - указатель на зарезервированную область памяти
for (int i=0; i < 2; i++) {
//IPW + IPR: обращение к зарезервированной части адресного пространства
pointer[i] = ‘!’;
cerr << "ptr[" << i << "] == " << ptr[i] << '\n';
}
return(0);
}
MAF: Memory Allocation Failure. Ошибка в запросе на распределение памяти. Возникает в случаях, когда производится попытка распределить слишком большой блок памяти, например, когда исчерпан файл подкачки.
Категория: Allocations and deallocations
#include <iostream.h>
#include <windows.h>
#define BIG_BLOCK 3000000000 //размер блока
int main(int, char **)
{
char *ptr = new char[BIG_BLOCK / sizeof(char)];
//MAF: слишком большой размер для распределения
if (ptr == 0) {
cerr << "Failed to allocating, as expected\n";
return (1);
} else {
cerr << "Got " << BIG_BLOCK << " bytes @" << (unsigned long)ptr << '\n';
delete[] ptr;
return(0);
}
}
MLK: Memory Leak. Утечка памяти
Распространенный вариант ошибки. Многие современные приложения грешат тем, что не отдают системе распределенные ресурсы по окончании своей работы.
Категория: Memory leaks
#include <windows.h>
#include <iostream.h>
int main(int, char **)
{
(void) new int[1000];
(void) new int[1000];
//результат потери памяти
return(0);
}
MPK: Potential Memory Leak. Потенциальная утечка памяти Иногда возникает ситуация, в которой необходимо провести инициализацию массива не с нулевого элемента. Purify считает это ошибкой. Но разработчик, пишущий пресловутый текстовый редактор может инициализировать блок памяти не с нулевого элемента.
Категория: Memory leaks
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
static int *pointer = new int[100000];
pointer += 100;//MPK: потеряли начало массива
return(0);
}
NPR: Null Pointer Read. Попытка чтения с нулевого адреса
Бич всех программ на С\С++. Очень часто себя ошибка проявляет при динамическом распределении памяти приложением, так как не все разработчики ставят условие на получение блока памяти, и возникает ситуация, когда система не может выдать блок указанного размера и возвращает ноль. По причине отсутствия условия разработчик как не в чем не бывало начинает проводить операции над блоком, адрес в памяти которого 0.
Категория: Invalid pointers
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char * pointer = (char *) 0x0; //указатель на нулевой адрес
for (int i=0; i < 2; i++) {
//NPR: попытка чтения с нулевого адреса
cerr << "pointer[" << i << "] == " << pointer[i] << '\n';
}
return(0);
}
NPW: Null Pointer Write. Попытка записи в нулевой адрес
Категория: Invalid pointers
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char * pointer = (char *) 0x0; //указатель на нулевой адрес
for (int i=0; i < 2; i++) {
//NPW: ошибка доступа
pointer[i]=’!’;
cerr << "pointer[" << i << "] == " << pointer[i] << '\n';
}
return(0);
}
UMC: Uninitialized Memory Copy. Попытка копирования непроинициализированного блока памяти
Категория: Unitialized memory
#include <iostream.h>
#include <windows.h>
#include <string.h>
int main(int, char **)
{
int * pointer = new int[10];
int block[10];
for (int i=0; i<10;i++)
{
pointer[i]=block[i]; //UMC предупреждение
cerr<<block[i]<<”\n”;
}
delete[] pointer;
return(0);
}
UMR: Uninitialized Memory Read. Попытка чтения непроинициализированного блока памяти
Категория: Unitialized memory
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char *pointer = new char;
cerr << "*pointer is " << *pointer << '\n';
//UMR: pointer указывает на непроинициализированный элемент
delete[] pointer;
return(0);
}
Чтобы не загромождать пользовательский интерфейс лишними данными, в Purify предусмотрена система гибких фильтров.
Система фильтров Purify способна регламентировать тип ошибок и предупреждений и ошибок (группировка производится по категориям) к программе, но и число исследуемых внешних модулей (чтобы разработчик мог концентрироваться только на ошибках собственного модуля). Таким образом возможно создание универсальных фильтров с осмысленными именами, которые ограничивают поток информации. Число создаваемых фильтров ничем не ограничено.
Фильтры создаются и назначаются и модифицируются через верхнее меню (View->CreateFilter и View->FilterManager). По умолчанию Purify выводит все сообщения и предупреждения.
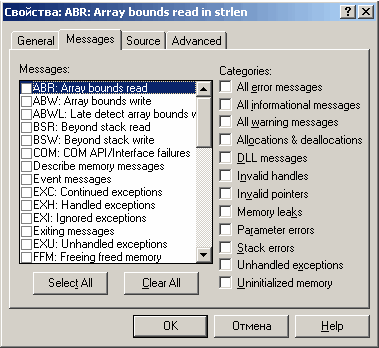
Рисунок показывает внешний вид окна создания фильтра (View->CreateFilter). Здесь мы имеем возможность по выбору сообщений, которые нужно отфильтровывать.
Пункт General — управляет именем фильтра и комментарием, его сопровождающим, Source — определяет местоположение исходных файлов, для которых необходимо вывести сообщения. Подход используется в том случае, когда происходит вызов одного модуля из другого, дабы ограничить количество информации в отчете.
Следующий рисунок демонстрирует вид окна настроек фильтров. Здесь имеется возможность по активации\деактвации фильтров и модулей.
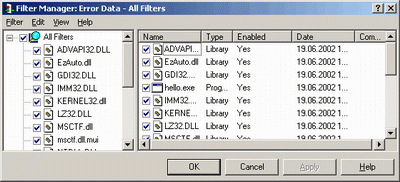
Выше упоминалось, что Purify не ограничивает число фильтров. Следует понимать, что не ограничивается не только общее число фильтров, но и их количество на одно протестированное приложение.
Ограничение по модулям, которое также можно выставить в данном диалоге, определяет число внешних модулей, предупреждения от которых появляются в отчете.
Rational Purify также имеет ряд функций интерфейса, воздействуя на которые, разработчик на этапе создания приложения может пользоваться всеми благами, предоставляемые данным приложением.
Опишем основные функции интерфейса с краткой характеристикой, разделив предварительно все функции по основным группам:
Функции установки статуса распределенных блоков:
Функции тестирования состояний распределенных блоков
Функции, определяющие разрушения
Функции, определяющие утечки памяти
Purify позволяет сохранять результаты тестирования (file->save copy as) в четырех различных представлениях, позволяющих наиболее эффективным образом получить информацию о ходе тестирования.
Рассмотрим варианты сохранения:
При установленном MS Outlook, возможно отправление отчета почтой через пункт file->send из верхнего меню Purify.
Перед исполнением тестируемого приложения, возможно, задать дополнительные настройки, которые смогут настроить Purify на эффективное тестирование.
Запуск приложения производится точно также как и в случае с Quantify (по F5 или file->Run). Параметры настройки находятся пункте Settings, появившегося окна.
Первая страница диалога представлена на рисунке
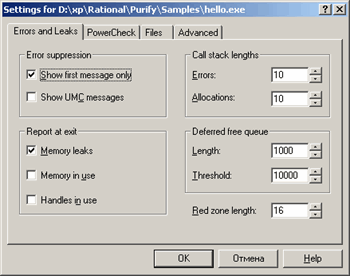
Отметим основные особенности, которые качественно могут сказаться на результирующем отчете:
Закладка PowerCheck позволит настроить уровень анализа каждого отдельно взятого модуля. Существует два способа инструментирования тестируемого приложения: Precise и Minimal. В первом случае проводится детальное инструментирование кода, но при этом модуль работает относительно медленно. Во втором случае, проводится краткое инструментирование, при котором Purify вносит в модуль меньше отладочной информации, и, как следствие, способна отловить меньшее число ошибок. Последний подход оправдан, когда приложение вызывает массу внешних библиотек от третьих фирм, которые не будут подвергаться правке.
Основное назначение продукта — выявление участков кода, пропущенного при тестировании приложения — проверка области охвата кода.
Очевидно, что при тестировании разработчику или тестировщику не удастся проверить работоспособность абсолютно всех функций. Также невозможно за один проход тестирования исполнить приложение с учетом всех условных ветвлений.
По требованиям на разработку программного кода, программист должен предоставить для функционального тестирования стабильно работающее приложение или модуль, без утечек памяти и полностью протестированный.
Понятие "полностью протестированный" определяет руководство компании в числовом, процентном значении. То есть, при оформлении требований указано, что область охвата кода 70%. Соответственно, по достижении данной цифры дальнейшие проверки кода можно считать нецелесообразными. Конечно, вопрос области охвата, очень сложный и неоднозначный. Единственным утешением может служить то, что 100% области охвата в крупных проектах не бывает.
Из трех рассматриваемых инструментов тестирования PureCoverage можно считать наиболее простым, так как информация им предоставляемая — это просмотр исходного текста приложения, где указано сколько раз исполнилась та или иная строка в приложении.
Запуск приложения ведется точно таким же образом, как и в остальных случаях. Здесь нового ничего нет. Из особенностей можно отметить то, что тестировать можно только то приложение, которое содержит отладочную информацию. Данная особенность выделяет PureCoverage из линейки инструментов тестирования для разработчиков, которые могут тестировать как код с отладочной информацией, так и без нее.
При попытке исполнить приложение, не содержащее отладочной информации, на экран, по окончании тестирования, будет выведено сообщение об ошибке.
По принципу работы PureCoverage слегка напоминает Quantify: также подсчитывает количество вызовов функций. Правда, получаемая статистика не столь исчерпывающая как в Quantify (в визуальном отношении), но для проверки области охвата кода вполне и вполне пригодна.
Система отчетности представлена 4-я различными видами отчетов:
На рисунке показана статистическая выкладка, выведенная Coverage по окончании тестирования приложения.
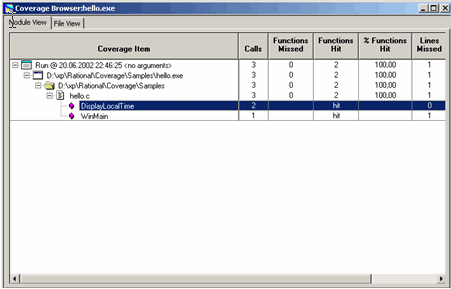
Поле Calls определяет число вызовов функции.
Из полученной таблицы видна статистическая информация о том, какие строки и сколько раз исполнялись.
К особенностям работы PureCoverage отнесем тестирование только тех исполняемых файлов, которые уже имеют отладочную информацию от компилятора. Соответственно, тестирование стандартных приложений и библиотек данным продуктом невозможно. Впрочем, и не нужно. Особые преимущества инструмент демонстрирует при совместном тестировании с Robot при функциональном тестировании, подсчитывая строки исходных текстов в момент воспроизведения скрипта. Тем самым на выходе тестировщик (или разработчик) получает информацию о стабильности функциональных компонент, плюс, область покрытия кода (область охвата).
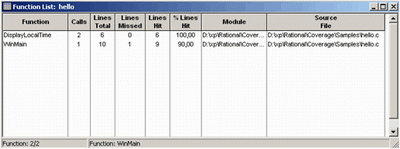
Поле %Lines Hit показывает процентное отношение протестированных строк кода для отдельной функции.
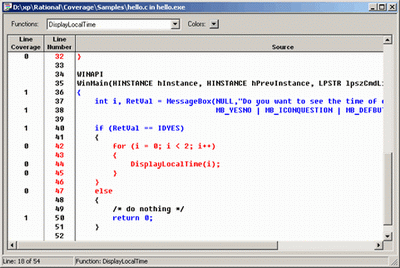
Вид окна перехода на уровень работы с исходным текстом. Из него видно, что PureCoverage ведет нумерацию строки и подсчитывает число исполнений каждой. Не исполнившиеся фрагменты подсвечиваются красным цветом (палитра может регулироваться пользователем).
Как и Quantify с Purify, данный инструмент имеет функции расширения интерфейса. Рассмотрим их краткое описание.
Данные из инструмента тестирования сохраняются в текстовом файле (как и в двух предыдущих случаях). Текстовый формат выдачи информации делает возможным включать различные обработчики отчетов основанные на скриптовых языках (например, при помощи Perl, можно "выудить" специфичные поля из текстового отчета и поместить их в средство документирования, получив отчет).
Пример фрагмента отчета приведен ниже:
CoverageData WinMain Function D:\xp\Rational\Coverage\Samples\hello.c D:\xp\Rational\Coverage\Samples\hello.exe 0 1 1 100.0 5 5 10 50.00 36 1 SourceLines D:\xp\Rational\Coverage\Samples\hello.c D:\xp\Rational\Coverage\Samples\hello.exe LineNumber LineCoverage 18.1 0 23.1 0 26.1 0 26.1 0 27.1 0 27.1 0
PureCoverage также как и Quantify может переносить табличные данные в Microsoft Excel.
Данный инструмент представляется наиболее простым из трех. Основное его отличие невозможность работы с приложениями, в которых отсутствует отладочная информация. Из достоинств отметим возможность одновременного запуска совместно с Purify, что позволяет получить отчеты по утечкам памяти и подсчет числа строк за один проход в тестировании, что существенно экономит время при отладке и тестировании.
Все инструментальные средства могут работать на 3 уровнях исполнения:
Одно из важных преимуществ перед конкурентами — возможность тестирования специальных приложений, таких как сервисы.
Особенность работы заключается в том, что сервис нельзя запускать из среды разработки. Инструменты тестирования понимают это, и предлагают свое решение, по которому необходимо насытить код откомпилированного сервиса (с отладочной информацией) отладочной информацией (не запустив при этом). Полученные в результате файл зарегистрировать в качестве сервиса. Сделать это можно как из GUI так и из командной строки. Мы рассмотрим последовательность шагов для командной строки, демонстрируя ее возможности (в примере, используется ссылка на Purify, но вместо него подставить имя любого средства тестирования):
По окончании действий, в зависимости от типа операционной системы, необходимо перезапустить сервис или перезагрузить компьютер и запустить сервис.
В момент старта сервиса инструмент тестирования запустится автоматически.
Поскольку специальные программные средства могут не иметь графической оболочки, то для их детальной проработки рекомендуется использование функций API из инструментов тестирования для разработчиков.
За дополнительной информацией обращайтесь в компанию Interface Ltd.
Обсудить на форуме IBM Rational Software
| INTERFACE Ltd. |
| ||||