| СТАТЬЯ |
26.06.03
|
© Алексей Стариков, BaseGroup
Labs.
© Статья была опубликована на сайте Лаборатория
BaseGroup
Механизм OLAP является на сегодня одним из популярных методов анализа данных. Есть два основных подхода к решению этой задачи. Первый из них называется Multidimensional OLAP (MOLAP) – реализация механизма при помощи многомерной базы данных на стороне сервера, а второй Relational OLAP (ROLAP) – построение кубов 'на лету' на основе SQL запросов к реляционной СУБД. Каждый из этих подходов имеет свои плюсы и минусы. Их сравнительный анализ выходит за рамки этой статьи. Мы же опишем нашу реализацию ядра настольного ROLAP модуля.
Такая задача возникла после применения ROLAP системы, построенной на основе компонентов Decision Cube, входящих в состав Borland Delphi. К сожалению, использование этого набора компонент показало низкую производительность на больших объемах данных. Остроту этой проблемы можно снизить, стараясь отсечь как можно больше данных перед подачей их для построения кубов. Но этого не всегда бывает достаточно.
В Интернете и прессе можно найти много информации об OLAP системах, но практически нигде не сказано о том, как это устроено внутри. Поэтому решение большинства проблем нам давалось методом проб и ошибок.
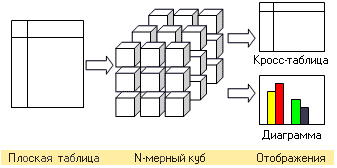
Общую схему работы настольной OLAP системы можно представить следующим образом:
Алгоритм работы следующий:
Рассмотрим как подобная система может быть устроена внутри. Начнем мы это с той стороны, которую можно посмотреть и пощупать, то есть с отображений.
Отображения, используемые в OLAP системах, чаще всего бывают двух видов – кросс-таблицы и диаграммы. Рассмотрим кросс-таблицу, которая является основным и наиболее распространенным способом отображения куба.
На приведенном ниже рисунке, желтым цветом отображены строки и столбцы, содержащие агрегированные результаты, светло-серым цветом отмечены ячейки, в которые попадают факты и темно-серым ячейки, содержащие данные размерностей.
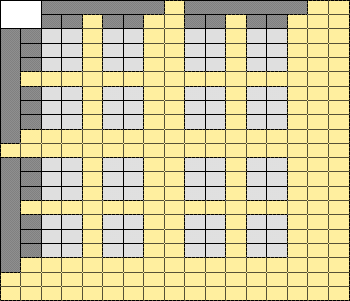
Таким образом, таблицу можно разделить на следующие элементы, с которыми мы и будем работать в дальнейшем:
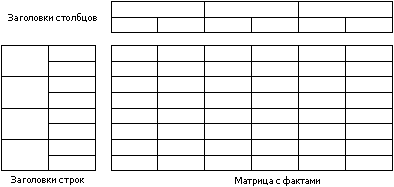
Заполняя матрицу с фактами, мы должны действовать следующим образом:
При этом нужно отметить то, что полученная матрица будет сильно разреженной, почему ее организация в виде двумерного массива (вариант, лежащий на поверхности) не только нерациональна, но, скорее всего, и невозможна в связи с большой размерностью этой матрицы, для хранения которой не хватит никакого объема оперативной памяти. Например, если наш куб содержит информацию о продажах за один год, и если в нем будет всего 3 измерения – Клиенты (250), Продукты (500) и Дата (365), то мы получим матрицу фактов следующих размеров:
Кол-во элементов = 250 х 500 х 365 = 45 625 000
И это при том, что заполненных элементов в матрице может быть всего несколько тысяч. Причем, чем больше количество измерений, тем более разреженной будет матрица.
Поэтому, для работы с этой матрицей нужно применить специальные механизмы работы с разреженными матрицами. Возможны различные варианты организации разреженной матрицы. Они довольно хорошо описаны в литературе по программированию, например, в первом томе классической книги "Искусство программирования" Дональда Кнута.
Рассмотрим теперь, как можно определить координаты факта, зная соответствующие ему измерения. Для этого рассмотрим подробнее структуру заголовка:
![]()
При этом можно легко найти способ определения номеров соответствующей ячейки и итогов, в которые она попадает. Здесь можно предложить несколько подходов. Один из них – это использование дерева для поиска соответствующих ячеек. Это дерево может быть построено при проходе по выборке. Кроме того, можно легко определить аналитическую рекуррентную формулу для вычисления требуемой координаты.
Данные, хранящиеся в таблице необходимо преобразовать для их использования. Так, в целях повышения производительности при построении гиперкуба, желательно находить уникальные элементы, хранящиеся в столбцах, являющихся измерениями куба. Кроме того, можно производить предварительное агрегирование фактов для записей, имеющих одинаковые значения размерностей. Как уже было сказано выше, для нас важны уникальные значения, имеющиеся в полях измерений. Тогда для их хранения можно предложить следующую структуру:
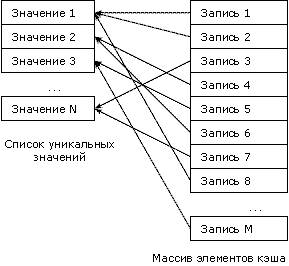
При использовании такой структуры мы значительно снижаем потребность в памяти. Что довольно актуально, т.к. для увеличения скорости работы желательно хранить данные в оперативной памяти. Кроме того, хранить можно только массив элементов, а их значения выгружать на диск, так как они будут нам требоваться только при выводе кросс-таблицы.
Описанные выше идеи были положены в основу при создании библиотеки компонентов CubeBase.
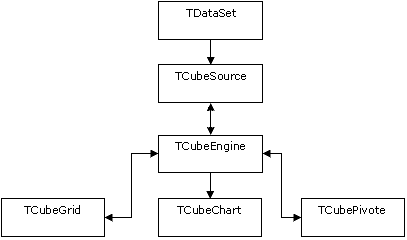
TСubeSource осуществляет кэширование и преобразование данных во внутренний формат, а также предварительное агрегирование данных. Компонент TСubeEngine осуществляет вычисление гиперкуба и операции с ним. Фактически, он является OLAP-машиной, осуществляющей преобразование плоской таблицы в многомерный набор данных. Компонент TCubeGrid выполняет вывод на экран кросс-таблицы и управление отображением гиперкуба. TСubeChart позволяет увидеть гиперкуб в виде графиков, а компонент TСubePivote управляет работой ядра куба.
Данный набор компонент показал намного более высокое быстродействие, чем Decision Cube. Так на наборе из 45 тыс. записей компоненты Decision Cube потребовали 8 мин. на построение сводной таблицы. CubeBase осуществил загрузку данных за 7сек. и построение сводной таблицы за 4 сек. При тестировании на 700 тыс. записей Decision Cube мы не дождались отклика в течение 30 минут, после чего сняли задачу. CubeBase осуществил загрузку данных за 45 сек. и построение куба за 15 сек.
На объемах данных в тысячи записей CubeBase отрабатывал в десятки раз быстрее Decision Cube. На таблицах в сотни тысяч записей – в сотни раз быстрее. А высокая производительность – один из самых важных показателей OLAP систем.
Дополнительная информация
За дополнительной информацией обращайтесь в компанию Interface Ltd.
| INTERFACE Ltd. |
| ||||