Эрик Браун
Статья была опубликована на сайте Microsoft №7/2004
Следующая версия SQL Server с кодовым названием «Yukon» включает ряд усовершенствований и обеспечивает расширенную поддержку языков программирования. Например, Transact-SQL теперь в большей мере отвечает спецификации SQL ANSI-99, а запросы стали более гибкими и четкими. Yukon позволяет выполнять пользовательские функции, хранимые процедуры и триггеры, написанные на CLR-совместимых языках, в частности на Visual Basic .NET и C#. Он также поддерживает подмножество языка XQuery, предлагаемого W3C в качестве стандарта, и содержит встроенные средства работы с XML. Автор статьи рассматривает наиболее значимые возможности языка и показывает их применение на примере приложения для ввода заказов.
На этапе планирования очередной версии Microsoft SQL Server с кодовым названием «Yukon» большое внимание уделялось перспективам баз данных и возможностям программирования SQL Server. Разработчики Microsoft осознали, что в будущем потребуются более симметричная модель программирования и гораздо более гибкая поддержка различных моделей данных. Требование симметричности модели программирования означало, что типичные задачи доступа к данным и манипулирования ими можно было бы решать самыми разнообразными способами — с помощью XML, Microsoft .NET Framework или T-SQL (Transact-SQL).
В итоге платформу программирования баз данных расширили в нескольких областях. Во-первых, способность служить хостом для .NET Framework CLR (common language runtime) позволяет применять при работе с базой данных процедурное программирование и управляемый код. Во-вторых, благодаря такой интеграции с .NET Framework базы данных SQL Server теперь обладают мощными объектными средствами. Введение полнофункционального типа данных XML, обладающего всеми возможностями реляционных типов, обеспечивает углубленную поддержку XML. Также добавлена поддержка стандартов XQuery (XML Query) и XSD (XML Schema Definition) на серверной стороне. Наконец, в Yukon внесены значительные усовершенствования в язык T-SQL.
Новые модели программирования и расширенные языки образуют среду программирования, которая опирается на текущую модель реляционной базы данных и дополняет ее. Конечным результатом работы над новой архитектурой являются возможность создавать более масштабируемые, надежные, устойчивые к сбоям приложения и ускорение разработки. Другой результат появления этих моделей — новая инфраструктура SQL Service Broker. Это распределенная прикладная инфраструктура асинхронной доставки сообщений. В дальнейшем я подробнее расскажу о Yukon SQL Service Broker, но сначала ознакомимся с основными изменениями и усовершенствованиями в модели программирования. Начнем с T-SQL.
В Yukon в T-SQL введено столько новых конструкций и примитивов, что полностью перечислить их здесь нельзя. Все они описаны в SQL Server Yukon Books Online. Усовершенствования языка T-SQL заключаются в большей совместимости со спецификацией SQL ANSI-99, что отражает пожелания пользователей. Многие усовершенствования T-SQL направлены на повышение четкости (expressiveness) запросов. Введено несколько новых типов запросов, позволяющих использовать код T-SQL при решении типичных задач. Например, при генерации счетов или иерархического набора результатов можно применять рекурсивные запросы.
T-SQL в Yukon поддерживает операторы PIVOT и UNPIVOT. Эти операторы обрабатывают входное табличное выражение и генерируют табличный набор результатов. Оператор PIVOT по записям исходной таблицы формирует поля выходной, при этом может выполняться агрегация или какие-либо другие математические операции. Он расширяет входное табличное выражение в соответствии с заданным сводным полем (pivot column) и генерирует выходную таблицу, в которой имеется свое поле для каждого уникального значения сводного поля. Оператор UNPIVOT выполняет противоположную операцию: формирует записи по полям. Оператор UNPIVOT сужает входное табличное выражение в соответствии со значениями сводного поля.
В Yukon введен простой, но мощный механизм обработки исключений — конструкция TRY/CATCH языка T-SQL. Cтало возможным перехватывать и обрабатывать ошибки аварийного прекращения транзакций, которые раньше приводили к завершению работы пакетов. Кроме того, появились новые языковые конструкции для поддержки защиты, репликации, Notification Services, XML и всей функциональности, предоставляемой .NET Framework. Реализация .NET Framework на сервере — важный этап эволюции SQL Server.
Теперь разработчики могут писать хранимые процедуры, триггеры и пользовательские функции (UDF) на любом языке, совместимом с Microsoft .NET, в частности на Visual Basic .NET и C#. В управляемом коде можно создавать три новых объекта — пользовательские типы (UDT), агрегаты и функции. CLR является сердцевиной .NET Framework и предоставляет среду выполнения любому коду, основанному на .NET Framework. CLR поддерживает различные функции и сервисы, необходимые для выполнения программ: компиляцию по запросу, управление памятью, введение строгого контроля типов, обработку исключений, управление потоками и защиту. SQL Server Yukon служит хостом для всех этих функций, что во многом аналогично тому, как операционная система служит хостом для приложения.
Yukon за счет интеграции с CLR также обеспечивает автоматическое управление памятью, выделение ресурсов и сбор мусора. SQL Server предоставляет .NET-сборкам прямой доступ к объектам базы данных через пространство выполнения (execution space) SQL Server. Доступ к данным осуществляется с помощью специальной разновидности ADO.NET. Описание функциональности ADO.NET, реализуемой в базе данных, выходит за рамки этой статьи, но, поскольку методы доступа аналогичны методам, уже знакомым разработчикам, использовать функциональность CLR несложно.
Интеграция .NET Framework с SQL Server Yukon предоставляет разработчикам баз данных несколько существенных преимуществ.
В предыдущих версиях SQL Server программистам баз данных при написании кода, работающего на сервере, приходилось ограничиваться применением T-SQL. Благодаря интеграции CLR разработчики баз данных теперь могут решать задачи, которые сложно или нельзя решить на одном только T-SQL. Visual Basic .NET и C# — современные языки программирования с полноценной поддержкой массивов, структурной обработки исключений и наборов (collections). Интеграция с CLR позволяет писать код, имеющий более сложную логику и более приспособленный для решения вычислительных задач, чем код на T-SQL.
Более того, Visual Basic .NET и C# поддерживают объектно-ориентированное программирование: инкапсуляцию, наследование и полиморфизм. Код, работающий с базой данных, теперь легко упорядочить в классы и пространства имен. Благодаря этому, когда приходится писать большой объем кода, работающего на сервере, становится проще упорядочивать и сопровождать код. Возможность логически и физически упорядочить код в сборки и пространства имен — огромное преимущество, облегчающее поиск и связывание блоков кода при реализации больших баз данных.
Проектируя UDT, придется учитывать такие ограничения, как допустимость пустых значений и выполнение условий. Можно даже использовать закрытые функции, чтобы расширить возможности типа данных; например, можно добавить встроенную поддержку XML-сериализации.
После регистрации сборки могут ссылаться на другие сборки, хранящиеся на сервере. Следовательно, можно загрузить сборку, реализующую общие функции, которые нужны другим сборкам на сервере. Это позволяет повторно использовать универсальный код. Разработчики баз данных, конечно, будут приветствовать такой модульный подход, поскольку объектные модели приложений становятся все сложнее.
В SQL Server Yukon реализованы три уровня защиты, ограничивающие возможности сборок, зарегистрированных в базе данных. Эта модель защиты интегрирует модель SQL Server, основанную на аутентификации и авторизации пользователей, и модель CLR, использующую защиту по правам доступа кода.
Самый высокий уровень защиты, SAFE, допускает лишь вычисления и доступ к данным. Следующий уровень, EXTERNAL_ACCESS, дополнительно разрешает доступ к внешним системным ресурсам. Самый низкий уровень защиты, UNSAFE, не накладывает никаких ограничений, кроме запрета операций, которые могут нарушить стабильность работы сервера.
Управляемый код на уровне доступа к данным позволяет производить над объектами базы данных сложные математические расчеты и применять любую логику. .NET Framework обеспечивает обширную поддержку работы со строками, регулярных выражений, перехвата ошибок и др. Функциональность базовой библиотеки классов .NET Framework позволяет получить полный доступ к тысячам уже разработанных классов и подпрограмм, к которым легко обратиться из любой хранимой процедуры, триггера или UDF. В ситуациях, где нужны обработка строк, математические функции, работа с датами, доступ к системным ресурсам, продвинутые алгоритмы шифрования, доступ к файлам, обработка изображений или манипулирование XML-данными, оказывается, что управляемые хранимые процедуры, функции, триггеры и агрегаты предоставляют значительно более простую программную модель, чем T-SQL.
Еще одно преимущество управляемого кода — контроль типов. Перед выполнением управляемого кода CLR осуществляет на стороне сервера проверки, чтобы удостовериться, что запуск кода действительно безопасен. Например, проверяется, как код обращается к памяти, чтобы не было чтения из той области, в которую ничего не записано.
Теперь при написании хранимых процедур, триггеров и UDF программист должен решить, что использовать — традиционный T-SQL или CLR-совместимый язык, например Visual Basic .NET или C#. Ответ зависит от потребностей конкретного проекта. T-SQL лучше использовать, когда код в основном обращается к данным и содержит минимум процедурной логики (или вообще не содержит ее). CLR-совместимые языки предпочтительнее для интенсивных математических вычислений и написания процедур со сложной логикой, а также для решений на основе базовых библиотек классов .NET Framework.
Еще одна важная особенность интеграции с CLR — размещение кода (code placement). И T-SQL-, и CLR-код выполняются ядром баз данных на сервере. Тот факт, что код для .NET Framework и база данных работают в одной среде, позволяет использовать мощные возможности сервера по обработке данных. Я рекомендую использовать SQL Server Profiler для оценки производительности приложений, а затем делать выбор, основываясь на эмпирических результатах тестирования. SQL Server Profiler теперь позволяет профилировать производительность CLR-кода, выполняемого в SQL Server, в частности используется новый графический формат вывода, позволяющий сравнивать производительность.
Теперь рассмотрим некоторые возможности .NET Framework и то, как они дополняют Yukon.
Yukon поддерживает расширяемую систему типов CLR. Эти типы можно использовать как часть определений таблиц на сервере, а на клиенте — для манипуляций как объектами. Кроме того, UDT позволяют расширять существующую систему типов, создавая новые типы, реализованные в управляемом коде. Примерами UDT являются нестандартные типы финансовых данных, специфические типы даты/времени и т. д. UDT можно рассматривать как контракт между серверным ядром и кодом.
С точки зрения .NET, UDT — это структурный или ссылочный тип, а не класс или перечислимое. Это значит, что использование памяти будет оптимальным. Однако UDT не поддерживают наследование и полиморфизм. В них могут присутствовать как открытые, так и закрытые функции. В сущности, такие задачи, как проверка ограничений, следует решать с помощью закрытых членов классов. Если ваш UDT состоит из нескольких фрагментов информации, как, например, в случае географического типа, содержащего долготу, широту и, возможно, высоту, вам потребуется определить закрытые поля, содержащие эти фрагменты. После создания UDT можно воспользоваться T-SQL для регистрации типа в SQL Server.
UDF бывают двух видов: скалярные и табличные. Скалярная функция возвращает единственное значение такого типа, как string, integer или bit, а табличная функция — набор результатов, содержащий одно или несколько полей.
Возможность создавать помимо встроенных дополнительные агрегатные функции (aggregate functions) не была доступна разработчикам, применявшим предыдущие версии SQL Server. В Yukon разработчики могут создавать собственные агрегатные функции в управляемом коде и обеспечивать доступ к этим функциям из T-SQL или из другого управляемого кода. Пользовательский агрегат также является .NET-классом, ожидающим ссылку на сборку, уже доступную в базе данных.
Для преобразования данных, хранящихся в базе данных, в математические значения можно использовать UDAgg (user-defined aggregates). Возьмем, например, статистические функции. Допустим, есть некая таблица, где хранятся результаты сбора количественной информации. Чтобы узнать средневзвешенное значение или среднеквадратичное отклонение этих результатов, вы могли бы вызвать UDAgg, который вычисляет и возвращает эту информацию.
Подпрограммы управляемого кода, работающие как хранимые процедуры, наиболее эффективны, когда вам нужно вернуть вызвавшему коду простой набор результатов с изменениями или просто выполнить оператор DML (data manipulation language) либо DDL (data definition language). После регистрации на сервере этот код используется по аналогии с хранимой процедурой.
Чтобы обернуть метод управляемого кода хранимой процедурой, применяется оператор CREATE PROCEDURE. В CREATE PROCEDURE используется синтаксис, показанный на примере следующего прототипа:
CREATE PROCEDURE mysproc (@username NVARCHAR(4000))
AS
EXTERNAL NAME YukonCLR:[MyNamespace.CLRCode]:: myfunction
На самом деле история применения XML в SQL Server Yukon начинается с SQL Server 2000. В той версии SQL Server была введена возможность возвращать реляционные данные как XML, массовая загрузка (bulk load), шреддинг XML-документов и доступ к объектам баз данных как к Web-сервисам XML. Web Services Toolkit, также известный как SQLXML 3.0, придает хранимым процедурам возможности Web-сервисов и обеспечивает поддержку XML-шаблонов и SQL Server UDF. Но в XML-технологии недоставало двух важных элементов: встроенного механизма хранения XML-данных (типа данных XML) и сложного языка запросов, поддерживающего запросы полуструктурированных данных. В Yukon добавлены эти два элемента, а также некоторые усовершенствования Web-сервисов и расширения оператора FOR XML языка T-SQL. Начнем с основного усовершенствования встроенных типов данных SQL Server — типа данных XML.
XML эволюционировал из технологии представления данных в формат передачи данных по сети, а теперь стал и форматом хранения. Постоянное хранение данных в XML-формате представляет интерес, и тип данных XML получит широкое применение. Во-первых, XML полезен, когда схема объекта не известна. Во-вторых, тип данных XML удобен при использовании динамических схем в случаях, когда структура представления информации постоянно меняется. В-третьих, хранение в XML-формате крайне важно для приложений, работающих с XML-документами. Можно привести много практических примеров, демонстрирующих применение типа данных XML. В примере, который приведу я, XML используется как формат хранения данных с динамической схемой, описывающей заказ клиента в виде сообщения серверу.
Тип данных XML — полноценный тип. Он обладает теми же возможностями, что и остальные типы данных SQL Server. Значимость этого трудно переоценить. Как и поле любого другого типа, XML-поле можно индексировать, накладывать ограничения на записи и поля через XSD-схему (хотя задавать XSD-схему необязательно) и выполнять запросы, используя XQuery-выражения, встроенные в T-SQL. Эти функции добавлены к W3C-спецификации XQuery. Кроме того, с помощью метода xmldt::modify пользователь может добавлять и удалять поддеревья, а также обновлять скалярные значения.
Тип данных XML весьма гибок. При необходимости можно связать с полем XSD-схему (XML Schema Definition). XML-поле, связанное с XSD-схемой, считается типизированным, а XML-поле, не связанное с XSD, — нетипизированным. С помощью XSD-схемы вы можете типизировать XML-поле после импорта в базу данных. Затем эту схему можно задействовать при создании индексов и других метаданных системного каталога. Типизированные XML-поля при поиске запрашиваемой информации обрабатываются гораздо быстрее и гибче, чем нетипизированные. Тип XML-поля зависит от ситуации, в которой оно используется, но в большинстве приложений обычно требуется указывать ссылку на XSD-схему.
Заметьте: в одном поле можно хранить XML-документы и XML-фрагменты. Кроме того, по XML-полям нужно создавать специальный индекс «XML». При этом создаются индексы для тэгов, значений и путей, содержащихся в XML-значении.
Создавая XML-поле, вы должны добавить XSD-документ и связать его с полем. Связь с XSD-схемой можно задать в SQL Server Workbench или DDL-оператором:
CREATE TABLE T (pk INT, xCol('mySchema'))
Когда схема импортируется в базу данных, из нее выделяются компоненты различных типов: ELEMENT, ATTRIBUTE, TYPE (для простых или сложных типов), ATTRIBUTEGROUP и MODELGROUP. Эти компоненты и все пространства имен, связываемые со схемой, затем заносятся в различные системные таблицы. Эти компоненты можно увидеть в специальных системных представлениях. Другими словами, схема не сохраняется в неизменном виде. Из этого вытекает минимум два следствия. Во-первых, тэг схемы и его атрибуты не сохраняются. Вместо этого значения атрибутов тэга XML-схемы — targetNamespace, attributeFormDefault, elementFormDefault и т. д. — присваиваются компонентам схемы. Во-вторых, SQL Server не позволяет после импорта восстановить и просмотреть исходный документ схемы. Рекомендуется сохранять копию каждой схемы или помещать содержимое всех схем в специальную таблицу базы данных. Для этого подойдет XML-поле. Альтернативный вариант — считывать XML-схемы с помощью встроенной функции XML_SCHEMA_NAMESPACE ('uri'). Она возвращает содержимое пространства имен uri.
При использовании XML-поля, связанного с XSD-схемой, возможности запросов XML-данных дополняют таковые запросов обычных реляционных данных. Хотя я не советовал бы хранить все данные в XML-полях, возможность применения XML в базе данных резко упрощает управление XML-документами и решение других прикладных задач.
Итак, с хранением данных мы разобрались, теперь перейдем к XQuery. Без него мой рассказ был бы неполным.
XML Query Language, обычно называемый XQuery, — это «интеллектуальный» и надежный язык, оптимизированный для запросов всех типов XML-данных. С помощью XQuery можно выполнять запросы к переменным и полям типа XML с помощью методов, связанных с этим типом. При вызове метода запроса допускается запрашивать в одном и том же пакете реляционные и XML-данные.
Как и в случае многих других XML-стандартов, разработка XQuery, в настоящее время находящаяся в стадии рабочего проекта, ведется под наблюдением W3C. Yukon поддерживает подмножество XQuery 1.0 Working Drafts, опубликованных в период с 20 декабря 2001 г. по 15 ноября 2002 г. (см. все рабочие проекты по ссылке www.w3c.org (EN)).
XQuery — результат эволюции языка запросов Quilt, основанного на ряде других языков, таких как XPath 1.0, XQL и SQL. Он также включает подмножество XPath 2.0. Вы можете использовать свои навыки работы с XPath — изучать совершенно новый язык не придется. Однако в SQL Server Yukon внесены значительные усовершенствования, выходящие за рамки XPath, в частности специальные функции и улучшенная поддержка итераций, сортировки результатов и конструирования.
XQuery-операторы состоят из пролога и тела. Пролог содержит одно или несколько объявлений пространств имен и/или объявлений импорта схем, создающих контекст обработки запроса, а тело — последовательность выражений, задающих критерий запроса. Эти операторы используются одним из вышеупомянутых методов типа данных XML (query, value, exist или modify).
С помощью XQuery можно запрашивать типизированные XML-данные (данные, связанные с XML-схемой) и XML-документы.
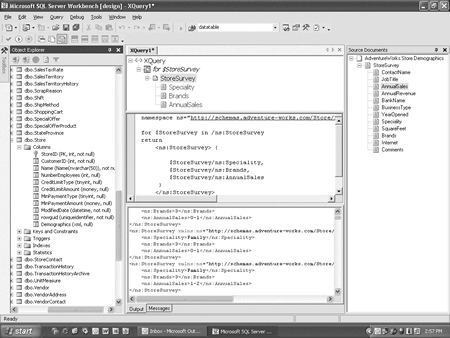
XQuery Designer — новое средство, интегрированное в SQL Server Workbench и облегчающее работу с XML-данными. XQuery Designer помогает писать запросы для выборки и манипулирования данными как из XML-полей, так и из XML-документов. Основной мотив разработки XQuery Designer — предоставить возможность создания XQuery-запросов без освоения всех тонкостей XML Query Language. Пример работы с XQuery Designer показан на рис. 1.
Рис. 1. XQuery Designer
До настоящего момента я говорил о новой .NET- и XML-функциональности Yukon как о чем-то раздельном. Сочетание этих технологий открывает новые возможности в решении прикладных задач в таких популярных областях, как электронная коммерция. При разработке для SQL Server основное внимание будет уделяться распределенным приложениям, где бизнес-процессы и бизнес-логика определены в программе, работающей с базой данных. Рассмотрим мощную поддержку Web-приложений, встроенную в Yukon, и углубимся в новые функциональные возможности, о которых я расскажу ниже.
Последнее десятилетие ознаменовалось бурным развитием приложений электронной коммерции, вследствие чего возникла потребность в более совершенном управлении приложениями, работающими с базами данных. Если вы разрабатывали систему ввода заказов или совершали онлайновую покупку, то знакомы с моделью рабочего процесса (workflow model). Когда покупатель размещает заказ на книгу, нужно зафиксировать транзакцию в системах учета товаров (inventory), отгрузки (shipping) и операций с кредитными картами, а затем отправить подтверждение заказа через другое Web-приложение. Ожидание завершения каждого из этих процессов в синхронном режиме отрицательно скажется на масштабируемости. Раньше разработчикам приходилось писать сложные хранимые процедуры и использовать удаленный вызов процедур для постановки сообщений в очередь. Yukon предоставляет новую масштабируемую архитектуру, которая позволяет направлять сообщения асинхронно.
SQL Server Service Broker — технология Yukon, благодаря которой внутренние или внешние процессы могут гарантированно отправлять и принимать асинхронные сообщения с помощью расширений обычного DML-языка T-SQL. Сообщения можно отправлять в очередь базы данных, используемую совместно с отправителем, другой базе данных того же экземпляра SQL Server или другому экземпляру SQL Server, выполняемому на том же или на удаленном сервере.
В традиционных системах обмена сообщениями за упорядочение сообщений и их координацию отвечает приложение. Борьба с дублированием сообщений, синхронизация, обработка сообщений в правильном порядке — все это проблемы, с которыми приходится иметь дело при разработке корпоративных систем управления данными.
SQL Server Service Broker решает эти проблемы, автоматически управляя порядком сообщений, уникальностью доставки и идентификацией сеансов. После установления сеанса между двумя конечными точками брокера сервисов приложение принимает каждое сообщение только раз, причем в порядке отправки. Приложение обрабатывает каждое сообщение ровно по разу в правильном порядке, причем для этого не нужен какой-то дополнительный код. Service Broker автоматически включает идентификатор в каждое сообщение. Приложение всегда может сообщить, к какому сеансу относится данное сообщение.
Service Broker ставит сообщения в очередь на доставку. Если сервис-получатель в данный момент недоступен, сообщение остается в очереди сервиса-отправителя и попытки доставки повторяются, пока сообщение не удастся доставить. Тем самым достигается надежное взаимодействие между двумя сервисами, даже если в какой-либо момент сеанса один из них становится временно недоступен.
SQL Server Service Broker обеспечивает слабое сопряжение сервиса-инициатора и сервиса-получателя. Сервис может поместить сообщение в очередь и продолжить обработку данных, полагаясь на то, что SQL Server Service Broker гарантированно доставит сообщение адресату. Сервис-инициатор может отправить несколько сообщений, а несколько сервисов-получателей будут обрабатывать их параллельно. Каждый сервис-получатель обрабатывает сообщения в меру своих возможностей, в зависимости от текущей загруженности системы.
Кроме того, очереди позволяют системам равномернее распределять нагрузку, снижая требования к пиковой пропускной способности сервера. А это повышает общую пропускная способность и производительность приложений, работающих с базами данных. Например, при использовании приложения для ввода заказов может оказаться, что каждый раз к полудню количество запросов увеличивается, из-за чего тратится больше ресурсов, а время ответа увеличивается. При применении Service Broker приложение для ввода заказов не обязано выполнять всю обработку заказа при его приеме. Вместо этого оно может принять заказ и отправить запросы на параллельную обработку системам биллинга, отгрузки и учета товаров. Параллельно работающие приложения гарантированно выполнят обработку через некое время, а приложение для ввода заказов продолжит прием поступающих заказов.
Одна из самых сложных задач, стоящих перед приложениями, которые обмениваются сообщениями, — сделать так, чтобы несколько программ могли параллельно считывать данные из одной и той же очереди. В таких случаях может оказаться, что сообщения обрабатываются не по порядку, даже если они принимаются в правильном порядке.
Рассмотрим типичное приложение обработки заказов. Сообщение A с инструкциями по созданию заголовка заказа и сообщение B с инструкциями по созданию позиций заказа помещаются в очередь. Если эти два сообщения извлекаются из очереди разными экземплярами сервисной программы и обрабатываются одновременно, может получиться так, что система сначала попытается зафиксировать транзакцию по позициям заказа. Эта попытка потерпит неудачу, поскольку заказ еще не существует, и, следовательно, транзакция откатится назад. Сообщение придется снова поместить в очередь и обработать, что приведет к бесполезному расходованию ресурсов. Обычно эту проблему решают, объединяя информацию из сообщений А и B в одном сообщении. В случае двух сообщений такой подход прост, но он плохо масштабируется, когда приходится координировать десятки или сотни сообщений.
Service Broker решает эту проблему, автоматически блокируя все сообщения, связанные с одной и той же задачей: такие сообщения могут приниматься и обрабатываться только одним экземпляром сервиса. Тем временем другие экземпляры сервиса могут извлекать из очереди и обрабатывать сообщения, относящиеся к другим задачам. Благодаря этому несколько параллельно выполняемых сервисных программ работают надежно и эффективно.
Одна из наиболее полезных функций Service Broker — активизация (activation). При использовании активизации сервис запускаются автоматически и считывает сообщения из очереди по мере их поступления. Если сообщения поступают быстрее, чем обрабатываются, запускаются дополнительные экземпляры сервиса, пока их число не достигнет максимума, заданного в конфигурации. Если интенсивность поступления сообщений снизилась и активный экземпляр сервиса, проверив очередь, обнаруживает, что в ней нет сообщений, ожидающих обработки, он завершается. Благодаря этому количество запущенных экземпляров сервиса автоматически увеличивается и уменьшается в соответствии с изменением нагрузки на систему. Если система остановлена или перезагружена, после возврата системы в рабочий режим экземпляры сервиса автоматически запускаются заново и считывают сообщения. Традиционным системам обмена сообщениями не хватает такой функциональности, и часто бывает, что какой-либо очереди в тот или иной момент выделяется слишком много или слишком мало ресурсов.
Интегрированная архитектура Service Broker обеспечивает выигрыш в производительности и удобстве администрирования приложения. Интеграция с SQL Server позволяет осуществлять транзакционный обмен сообщениями, т. е. каждый рабочий цикл сервиса (прием сообщения, его обработка и отправка ответного сообщения) можно заключить в одну транзакцию базы данных. Если транзакция терпит неудачу, все операции откатываются назад и принятое сообщение снова ставится в очередь, чтобы система попыталась обработать его повторно. Пока приложение не зафиксирует транзакцию, выполняемые операции ни на что не влияют. Приложение остается в целостном состоянии, поэтому можно обойтись без затрат ресурсов и сложностей координации распределенных транзакций.
Администрирование упрощается, когда данные, сообщения и логика приложения хранятся в базе данных. Тогда для аварийного восстановления, управления кластеризацией, защиты, резервного копирования и т. д. достаточно поддерживать только один, а не три или четыре компонента. В традиционных системах обмена сообщениями синхронизация хранилища сообщений и базы данных может нарушиться. Например, если один компонент восстановлен из резервной копии, в тот же момент должен быть восстановлен из резервной копии и другой компонент, иначе целостность базы данных и хранилища сообщений нарушится. Если сообщения и данные хранятся в одной базе, такая проблема больше не возникает.
Общая среда разработки также является преимуществом. В приложении с поддержкой Service Broker части, осуществляющие обмен сообщениями и работу с данными, могут быть созданы с помощью одних и тех же языков и средств. Это позволяет разработчикам использовать свой опыт программирования баз данных при создании приложений, обменивающихся сообщениями. Хранимые процедуры, реализующие сервис Service Broker, можно писать на T-SQL или на одном из CLR-совместимых языков.
Благодаря интеграции с базой данных становится возможным автоматическое управление ресурсами. Service Broker выполняется в контексте экземпляра SQL Server, поэтому брокер может получить совокупное представление всех готовых к передаче сообщений от всех баз данных экземпляра. Благодаря этому каждая база данных может поддерживать собственные очереди, при этом сохранится равноправный доступ к ресурсам экземпляра SQL Server в целом.
Посмотрим, как все эти концепции применяются при разработке приложения ввода заказов, размещаемых клиентами на Web-сайте. Сообщения, которыми обмениваются сервисы, хранятся в XML-поле. В иллюстративных целях я воспользуюсь Web-сервисом ASP.NET, который регистрируется и выполняется в экземпляре CLR, хостом для которого служит SQL Server. Чтобы отправлять и получать информацию о заказах на покупку товара, этот сервис взаимодействует с другими сервисами. Применение XML-поля для хранения сообщений позволяет инкапсулировать схему и упростить обработку данных.
Клиент размещает заказ на Web-сайте. Когда транзакция заказа фиксируется, сообщение с информацией о заказе помещается в очередь Order Entry Service. Заказ отправляется сервису Order Entry Service как XML-поле. Благодаря этому вся информация о заказе объединяется в одном поле. Полностью процесс ввода заказов показан на рис. 2.
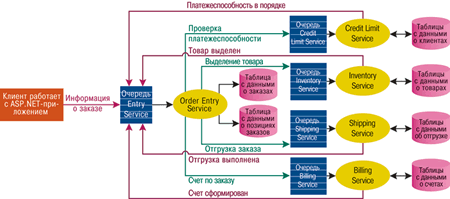
Рис. 2. Приложение Order Entry Service
Order Entry Service начинает транзакцию, принимает сообщение и обрабатывает его. Затем он отправляет запрос сервису Credit Limit Service, чтобы проверить платежеспособность клиента. Если все в порядке, Order Entry Service переходит к следующему этапу.
Order Entry Service проверяет наличие товара по каждой позиции заказа. Проверка выполняется с помощью XQuery-запроса. В этот момент, если товар по этой позиции можно отгружать, отправляется сообщение в очередь Shipping Service.
Shipping Service — это хранимая процедура T-SQL, использующая XQuery для анализа XML-сообщения. Для генерации данных по отгрузке заказа используется информация, полученная от клиента. Когда отгрузка завершена, отправляется сообщение в Order Entry Service. Получив сообщение «отгрузка выполнена», Order Entry Service обновляет информацию о состоянии заказа в базе данных, чтобы указать, что заказ доставлен. Все сообщения, принимаемые и отправляемые Order Entry Service, записываются в таблицу аудита для последующего анализа и устранения проблем.
Этот простой пример показывает, как использовать новые возможности программирования Yukon — XML, CLR, Service Broker и расширенный T-SQL — при разработке надежных, масштабируемых и полнофункциональных приложений, работающих с базами данных.
Я затронул лишь некоторые из захватывающих нововведений в архитектуре Yukon. У разработчиков баз данных никогда не было такого широкого выбора способов доступа к данным и хранения информации. Пример использования SQL Server Service Broker показывает только часть новых возможностей SQL Server. Приступайте к работе с бета-версией SQL Server Yukon и продолжайте следить за его освещением в MSDN Magazine. Еще до того, как вы узнаете все новые возможности Yukon, вы будете применять его без оглядки на прошлое.
Дополнительная информация
За дополнительной информацией обращайтесь в компанию Interface Ltd.
| INTERFACE Ltd. |
| ||||