| СТАТЬЯ |
23.04.01
|
Явное получение блокировок строк
Вы можете перекрывать умалчиваемое блокирование, выдав предложение SELECT с фразой FOR UPDATE. Предложение SELECT ... FOR UPDATE используется для получения монопольных блокировок строк для выбираемых строк в предвидении действительного обновления выбранных строк.
Вы можете использовать предложение SELECT ... FOR UPDATE для блокирования строк без фактического изменения этих строк. Например, некоторые триггеры в главе 8 показывают, как можно реализовать ссылочную целостность. В триггере EMP_DEPT_CHECK (страница 8-22) строка, содержащая адресуемое значение родительского ключа, блокируется для того, чтобы гарантировать ее неизменность на время транзакции; если бы родительский ключ был обновлен или удален, ссылочная целостность была бы нарушена.
Предложения SELECT ... FOR UPDATE часто используются интерактивными программами, позволяющими пользователю модифицировать поля в одной или нескольких выбранных строках (что может потребовать некоторого времени); по этим строкам запрашиваются блокировки строк, чтобы только один пользователь в любой данный момент времени мог обновлять эти строки.
Если предложение SELECT ... FOR UPDATE используется для определения курсора, то строки в возвращаемом множестве блокируются перед первым извлечением, когда курсор открывается; строки не блокируются по одной по мере их извлечения из курсора. Все блокировки освобождаются не при закрытии курсора, а при подтверждении или откате транзакции, открывшей этот курсор.
Каждая строка в возвращаемом множестве предложения SELECT ... FOR UPDATE блокирована индивидуально; если какая-либо строка захвачена конфликтующей блокировкой другой транзакции, то предложение SELECT ... FOR UPDATE будет ожидать освобождения этой блокировки. Поэтому, если предложение SELECT ... FOR UPDATE блокирует много строк в таблице, для которой высока активность одновременных обновлений, вы, скорее всего, улучшили бы производительность, запросив вместо этого монопольную блокировку таблицы.
Запрашивая блокировки строк с помощью предложения SELECT ... FOR UPDATE, вы можете указать, хотите ли вы ожидать получения блокировок. Если вы специфицируете опцию NOWAIT, то вы получите блокировки строк лишь в том случае, если они доступны немедленно. В противном случае возвращается ошибка, указывающая, что блокировка в данный момент недоступна. В этом случае вы можете повторить попытку заблокировать строки позже. Если опция NOWAIT опущена, то транзакция не будет продолжена, пока не получит запрошенную блокировку. Если ожидание блокировки строк становится слишком долгим, вы можете захотеть снять операцию блокирования и повторить ее позже; вы можете предпочесть закодировать эту логику в ваших приложениях.
Для распределенной транзакции, ожидающей блокировки строк, может иметь место таймаут, если истекшее время ожидания блокировки достигнет значения, установленного параметром инициализации DISTRIBUTED_LOCK_TIMEOUT. Обратитесь к секции "Сбои, препятствующие доступу к данным" для дополнительной информации об этом параметре.
По умолчанию модель согласованности данных ORACLE гарантирует согласованность по чтению на уровне предложения, но не обеспечивает согласованности по чтению на уровне транзакции (повторяемости чтений). Если вы хотите выполнить несколько запросов по одной или нескольким таблицам и не осуществляете обновлений, вы можете предпочесть ТРАНЗАКЦИЮ READ-ONLY. Указав, что ваша транзакция является транзакцией read-only, вы можете выполнять сколько угодно запросов по любым таблицам, будучи уверенными, что результаты каждого запроса согласованы по отношению к одной и той же стартовой точке времени.
Транзакция read-only не получает каких-либо дополнительных блокировок данных, чтобы обеспечить согласованность по чтению на уровне транзакции. Такая согласованность обеспечивается мультиверсионной моделью согласованности данных; все запросы возвращают информацию по состоянию на момент системного номера изменения (SCN), определяемого в момент начала транзакции read-only. Как следствие, никакие блокировки данных не требуются, другие транзакции могут опрашивать и обновлять те же данные, которые одновременно опрашивает транзакция read-only.
Блоки данных, изменившиеся с момента начала транзакции read-only, реконструируются для этой транзакции из сегментов отката. Поэтому долго выполняющиеся транзакции read-only могут иногда получать ошибку "snapshot too old" ("снимок слишком стар"). Чтобы избежать таких ошибок, создайте больше сегментов отката или увеличьте их размеры. Альтернативно, вы можете запускать долго работающие транзакции в те периоды времени, когда активность интерактивных транзакций минимальна, или можете получить разделяемую блокировку по опрашиваемой вами таблице, тем самым запрещая любые ее модификации на время вашей транзакции.
Транзакция read-only начинается предложением SET TRANSACTION, включающим опцию READ ONLY. Например:
SET TRANSACTION READ ONLY;
Предложение SET TRANSACTION должно быть первым предложением в новой транзакции; если предложению SET TRANSACTION READ ONLY предшествует любое предложение DML или предложение, отличное от предложения DDL (например, SET ROLE), то будет возвращена ошибка. Внутри транзакции SET TRANSACTION READ ONLY допускаются только предложения SELECT (без фразы FOR UPDATE), COMMIT, ROLLBACK, а также предложения не-DML (такие как SET ROLE, ALTER SYSTEM, LOCK TABLE); в противном случае вы получите ошибку. Транзакция SET TRANSACTION READ ONLY заканчивается предложением COMMIT, ROLLBACK или предложением DDL (предложение DDL неявно подтверждает транзакцию read-only, а затем подтверждает свою собственную транзакцию).
Просмотр и мониторинг блокировок
ORACLE предоставляет два средства для выдачи информации о блокировках для работающих транзакций в инстанции:
|
(LOCK и LATCH) |
Средство мониторинга предоставляет два SQL*DBA монитора для отслеживания блокировок инстанции. Обратитесь к документу ORACLE7 Server Utilities User's Guide за полной информацией о мониторах SQL*DBA. |
|
|
Скрипт UTLLOCKT.SQL выдает простой символьный граф ожиданий в форме дерева. Вызываемый через любой инструмент разовых запросов (SQL*DBA или SQL*Plus), этот скрипт распечатывает те сессии в системе, которые ожидают блокировок, а также соответствующие блокировки. Местоположение этого скрипта зависит от операционной системы. (Еще один скрипт, CATBLOCK.SQL, создает обзоры, необходимые для UTLLOCKT.SQL, и должен быть выполнен до того, как будет использоваться UTLLOCKT.SQL). |
Параметры инициализации SERIALIZABLE и ROW_LOCKING
При запуске инстанции два параметра инициализации определяют, как эта инстанция будет обрабатывать блокировки: SERIALIZABLE и ROW_LOCKING. По умолчанию SERIALIZABLE имеет значение FALSE, а ROW_LOCKING имеет значение ALWAYS. Эти параметры почти никогда не должны изменяться. Они предусмотрены для тех установок, которые должны работать в режиме совместимости со стандартами ANSI/ISO, или для тех, кто хочет использовать приложения, написанные для более ранних версий ORACLE. Только на таких установках следует изменять эти параметры инициализации, потому что установка их значений, отличных от умалчиваемых, приводит к серьезному падению производительности. За детальным описанием этих параметров обратитесь к документу ORACLE7 Server Administrator's Guide.
Значения этих параметров должны изменяться лишь тогда, когда инстанция остановлена. Если с одной базой данных работают несколько инстанций, то все инстанции должны использовать одни и те же значения этих параметров.
Сводка опций неумалчиваемых блокировок
Два названных выше параметра инициализации могут изменить поведение блокировок на уровне системы. В совокупности это дает три глобальных режима поведения, отличных от умалчиваемого. Табл.4-1 суммирует эти неумалчиваемые значения и показывает, по какой причине вы можете выбрать тот или иной образ поведения базы данных, отличный от умалчиваемого.
Табл.4-1Сводка неумалчиваемых опций блокировки
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Табл.4-2 иллюстрирует отличия в поведении блокировок для трех возможных случаев установки параметров инициализации, которые показаны в табл.4-1.
Табл.4-2Поведение неумалчиваемых блокировок
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
| SELECT |
|
|
|
|
|
|
| INSERT |
|
|
|
|
|
|
| UPDATE |
|
|
|
|
|
|
| DELETE |
|
|
|
|
|
|
| SELECT ... FOR UPDATE |
|
|
|
|
|
|
| LOCK TABLE ... IN ... |
|
|||||
| ROW SHARE MODE ROW EXCLUSIVE MODE SHARE MODE SHARE ROW EXCLUSIVE MODE EXCLUSIVE MODE |
RX S SRX X |
RX S SRX X |
RX S SRX X |
RX S SRX X |
RX S SRX X |
RX S SRX X |
| Предложения DDL |
|
|
|
|
|
|
Использование обработки массива
ОБРАБОТКА МАССИВА может улучшить производительность за счет сокращения количества обращений к ORACLE из вашего приложения. Обработка массива позволяет вашему приложению многократно исполнить одиночное предложение SQL за одно обращение к ORACLE. Эта секция рассказывает вам:
Как обработка массива улучшает производительность
Каждое предложение SQL, выдаваемое приложением, передается этим приложением в ORACLE. Чтобы передать ORACLE предложение SQL, приложение должно осуществить вызов функции. Эти вызовы функций приводят к накладным расходам, которые могут снижать производительность, особенно, если приложение взаимодействует с ORACLE через сеть.
При обработке массива, приложение может выдать предложение SQL несколько раз подряд за один вызов ORACLE. Например, единственный вызов ORACLE может исполнить предложение SQL 100 раз. Без обработки массива ваше приложение должно было бы 100 раз вызвать ORACLE, один раз на каждое исполнение. Сокращая средние накладные расходы на каждое исполнение, обработка массива улучшает производительность, особенно в сетевых окружениях.
Выгода в производительности от обработки массива зависит от размера этого массива. Увеличивая размер массива, вы сокращаете количество вызовов ORACLE. Однако, дальнейшее увеличение размера массива после некоторого предела невыгодно, так как улучшение производительности не компенсирует больших затрат памяти. Как общую рекомендацию, примите размер массива за 100.
Например, предположим, что ваше приложение выполняет одно и то же предложение SQL 10000 раз. Без обработки массива приложение должно было бы 10000 раз обратиться к ORACLE, один раз на каждое исполнение. Однако при обработке массива и размере массива 100, приложение должно вызвать ORACLE всего 100 раз, один раз на каждые 100 исполнений. В этом случае, увеличение размера массива до 100 сокращает число вызовов на 9900.
Однако дальнейшее увеличение размера массива улучшает производительность лишь незначительно. Размер массива 1000 сократит число вызовов до 10. Этот выигрыш производительности относительно мал в сравнении с тем выигрышем, который был получен при увеличении размера массива от 1 до 100. В то же время увеличение размера массива до 1000 в десять раз увеличит память, потребную для хранения этого массива.
Применение обработки массива в ваших приложениях
Многие прикладные инструменты ORACLE могут использовать преимущества обработки массивов. Некоторые из таких инструментов, такие как SQL*Forms, используют обработку массивов автоматически. В других инструментах вы имеете некоторую степень контроля над обработкой массивов. К таким инструментам относятся:
Использование обработки массивов с прекомпиляторами ORACLE
В среде прекомпиляторов ORACLE, вы можете использовать обработку массива для того, чтобы многократно исполнить встроенное предложение SQL. Рассмотрим следующее предложение SQL, встроенное в программу прекомпилятора Pro*C:
EXEC SQL INSERT INTO accounts (acc_no, acc_type, interest, balance) VALUES (:acc_no, :acc_type, :interest, :balance);
Если все переменные ACC_NO, ACC_TYPE, INTEREST и BALANCE имеют целочисленный тип, то это предложение SQL передается ORACLE и исполняется один раз. ORACLE вставляет единственную строку в таблицу ACCOUNTS. Значения столбцов этой строки задаются переменными.
Однако, если переменные ACC_NO, ACC_TYPE, INTEREST и BALANCE представляют собой целочисленные массивы длины 100, то данное предложение SQL передается ORACLE и выполняется 100 раз. ORACLE вставляет в таблицу ACCOUNTS 100 новых строк. Значения столбцов каждой строки задаются последовательными элементами соответствующих массивов переменных.
Вы можете также использовать обработку массива в программе прекомпилятора ORACLE для того, чтобы извлечь много строк одним предложением FETCH. Для дополнительной информации об обработке массивов в среде прекомпиляторов ORACLE обратитесь к документам Programmer's Guide to the ORACLE Precompilers или Programmer's Guide to the Pro*Ada Precompiler.
Использование обработки массивов с интерфейсами вызовов ORACLE (OCI)
При использовании интерфейсов вызовов ORACLE (OCI) вы можете реализовать обработку массива через следующие вызовы OCI:
| OEXN | Вызов OEXN исполняет предложение SQL несколько раз. Один из аргументов этого вызова указывает, сколько раз должно быть исполнено предложение. |
| OFEN | Вызов OFEN извлекает несколько строк, которые были возвращены запросом SQL. Один из аргументов этого вызова указывает, сколько строк должно быть извлечено. |
Для дополнительной информации об обработке массивов в среде OCI обратитесь к документам Programmer's Guide to the ORACLE Call Interfaces или Pro*Ada Call Interface User's Guide.
Использование обработки массивов с SQL*Plus
SQL*Plus использует обработку массивов автоматически, чтобы возвращать сразу много строк из базы данных. Однако вы можете контролировать количество строк, возвращаемых за один раз.
Системная переменная SQL*Plus с именем ARRAYSIZE определяет, сколько строк возвращается за один вызов ORACLE. Умалчиваемое значение переменной ARRAYSIZE равно 20. Чтобы увидеть текущее значение ARRAYSIZE, введите следующее предложение SQL*Plus:
SQL> SHOW ARRAYSIZE
Вы можете увеличить количество строк, возвращаемых за один вызов, установив большее значение переменной ARRAYSIZE. Например, чтобы установить значение 100, введите следующее предложение SQL*Plus:
SQL> SET ARRAYSIZE 100
ARRAYSIZE также определяет количество строк, копируемых как один пакет командой SQL*Plus COPY. Для дополнительной информации о командах SQL*Plus обратитесь к документу SQL*Plus User's Guide and Reference.
Использование обработки массивов с SQL*Loader
SQL*Loader использует обработку массивов автоматически, чтобы вставлять в базу данных по нескольку строк за один раз. Однако вы можете контролировать количество строк, вставляемых за один вызов.
Аргумент ROWS командной строки SQL*Loader определяет, сколько строк будет вставляться за один раз. Умалчиваемое значение этого аргумента равно 64. Чтобы вставлять больше строк за один раз, задайте большее значение для ROWS. Например, чтобы вставлять массивами по 100 строк, вы могли бы вызвать SQL*Loader с помощью следующей команды:
SQLLOAD USERID=BAM/BIM, CONTROL=C1.CTL, DISCARD=D1.DIS, ROWS=100
Для информации о SQL*Loader обратитесь к документу ORACLE7 Server Utilities User's Guide.
Использование обработки массивов с утилитами экспорта и импорта
Утилиты экспорта и импорта используют обработку массивов автоматически, когда обмениваются данными с базой данных ORACLE. Однако вы можете контролировать количество строк, обрабатываемых за один вызов.
Если вы вызываете Import или Export, задавая аргументы командной строки, то вы можете управлять размером массива через значение ключевого слова BUFFER. Ключевое слово BUFFER определяет размер буфера (в байтах), используемого для обработки данных. Умалчиваемое значение этого параметра зависит от операционной системы.
Чтобы подобрать значение для BUFFER, определить размер ваших строк в байтах. Затем выберите, сколько строк вы хотите обрабатывать за один раз. Произведение этих значений укажите как значение для BUFFER. Например, если вы импортируете строки длиной около 4096 байт, и хотите импортировать по 100 строк за один вызов ORACLE, специфицируйте для BUFFER значение 409600 байт. Вы могли бы вызвать импорт следующей командой:
IMP USERID=BAM/BIM IGNORE=Y FULL=N BUFFER=409600
Если вы вызываете Import или Export, используя интерактивный метод, то утилита запрашивает у вас размер буфера. Размер, который вы специфицируете, должен быть достаточен, чтобы уместить самую большую строку. Если вы специфицируете значение 0, то утилита будет обрабатывать лишь по одной строке за раз.
Для информации об импорте и экспорте обратитесь к документу ORACLE7 Server Utilities User's Guide.
Использование PL/SQL для улучшения производительности
Анонимные блоки и хранимые процедуры улучшают производительность за счет сокращения числа вызовов ORACLE из вашего приложения. Сокращение вызовов особенно эффективно в сетевых окружениях, где вызовы ORACLE могут приводить к большим накладным расходам. PL/SQL сокращает эти вызовы следующими способами:
Хранимые процедуры еще более улучшают производительность, устраняя необходимость разбора и автоматически используя преимущества разделяемых областей PL/SQL.
Дальнейшее улучшение производительности обеспечивают пакеты:
Процессор PL/SQL в сервере ORACLE
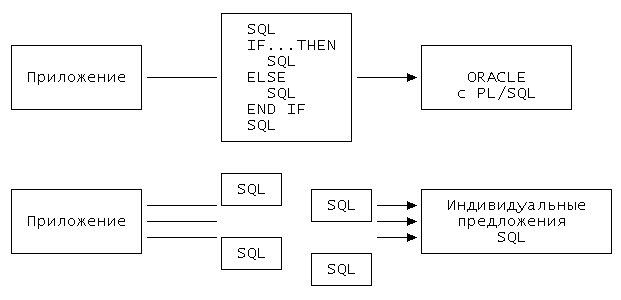
Анонимные блоки и хранимые процедуры позволяют приложениям передавать в ORACLE много предложений SQL за один раз. Блок, содержащий несколько предложений SQL, может быть передан ORACLE за один вызов. Без PL/SQL, предложения должны передавать предложения SQL по одному за раз, с помощью отдельного вызова ORACLE для каждого предложения. Рис.4-2 показывает, как PL/SQL сокращает сетевой трафик и радикально улучшает производительность.
Процессор PL/SQL в прикладных инструментах ORACLE
Анонимные блоки и хранимые процедуры позволяют приложениям SQL*Forms и SQL*Menu выполнять процедурные функции, которые в ином случае потребовали бы вызовов ORACLE. Так как блок PL/SQL может содержать процедурные предложения, ваше приложение может использовать процессор PL/SQL, встроенный в приложение ORACLE, для исполнения таких предложений.
Например, вам следует выполнять вычисления данных в ваших приложениях SQL*Forms путем передачи процедурных предложений процессору PL/SQL, вместо того чтобы выдавать предложения SQL для этих целей. Процессор PL/SQL исполняет все процедурные предложения на стороне приложения, а в ORACLE посылает лишь предложения SQL. Таким образом, большая часть работы выполняется на стороне приложения, а не на стороне сервера. Более того, если блок не содержит предложений SQL, то процессор PL/SQL исполняет весь блок на стороне приложения, вообще не вызывая ORACLE.
Рис.4-2 PL/SQL повышает производительность
Использование PL/SQL в ваших приложениях
Вы должны применять PL/SQL в тех частях вашего приложения, которые выполняют основную долю обращений к базе данных. Следуйте приведенным ниже рекомендациям по использованию PL/SQL с конкретными прикладными инструментами ORACLE, чтобы улучшить производительность ваших приложений:
| Прекомпиляторы | В программах, интенсивно использующих встроенный SQL, передавайте в ORACLE сразу по нескольку предложений SQL, выдавая анонимные блоки или вызывая хранимые процедуры, вместо того чтобы выдавать одиночные встроенные предложения SQL. |
| SQL*Plus | Для небольших процедурных задач, используйте SQL*Plus, выдавая анонимные блоки или вызывая хранимые процедуры, вместо того чтобы использовать SQL*Report или программы прекомпиляторов ORACLE. |
| SQL*Forms | Замените многошаговые триггеры в приложениях SQL*Forms одношаговыми триггерами, содержащими анонимные блоки PL/SQL. |
Для дополнительных рекомендаций по разработке приложений с помощью PL/SQL обратитесь к главе 7.
предыдущая часть | содержание | следующая часть
Дополнительную информацию Вы можете получить в компании Interface Ltd.
Обсудить на форуме Oracle
Отправить ссылку на страницу по e-mail
Interface Ltd.Отправить E-Mail http://www.interface.ru |
|
| Ваши замечания и предложения отправляйте
автору По техническим вопросам обращайтесь к вебмастеру Документ опубликован: 23.04.01 |