| СТАТЬЯ | 07.08.01 |
Средства проектирования данных
© Алексей Федоров, Наталия Елманова
КомпьютерПресс #1 2001
Статья была опубликована в КомпьютерПресс
как часть статьи "Введение в базы данных"
Предыдущие статьи данного цикла были посвящены непосредственно базам данных. Мы говорили о том, какие объекты содержатся в базах данных, чем серверные базы данных отличаются от настольных, каковы особенности наиболее популярных продуктов обеих категорий. Кроме того, мы рассмотрели возможные механизмы доступа к данным и язык SQL, с помощью которого осуществляются манипуляции над данными и метаданными.
Наше введение в базы данных будет неполным, если мы не рассмотрим процесс создания приложений, использующих базы данных, и средства, с помощью которых этот процесс осуществляется. Поэтому заключительная часть нашего цикла будет посвящена инструментальным средствам для проектирования данных (именно этому и посвящена настоящая статья), а также средствам разработки приложений, использующих базы данных, и средствам генерации отчетов и анализа данных (этому будут посвящены последующие статьи цикла).
Прежде чем приступить к рассказу о средствах проектирования данных, давайте рассмотрим, из чего состоит сам «производственный процесс», чтобы понять роль и место каждой из рассматриваемых в данном цикле категорий продуктов.
Жизненный цикл информационной системы в общем случае начинается в момент принятия решения о ее создании и заканчивается в момент выведения ее из эксплуатации. Основными его этапами (если опустить детали) обычно являются:
На этапе предпроектного обследования осуществляются анализ и моделирование бизнес-процессов, подлежащих автоматизации (иногда этот процесс называется структурным моделированием), а также формулируются требования к будущему продукту. Нередко на этом же этапе производится выбор СУБД и инструментальных средств. Обычно подобное обследование проводится с участием потенциальных пользователей.
Этап проектирования данных также обычно происходит с участием потенциальных пользователей. Иногда в процессе проектирования данных создаются прототипы работающих приложений, позволяющих уточнить и дополнить требования к конечному продукту. Если предусматривается, что внедрение новой информационной системы будет сопровождаться выведением из эксплуатации ее предшественника, то принимаются решения о том, каким образом использовать унаследованные данные, и в модель данных, являющуюся итогом этого этапа, вносятся необходимые изменения.
Реальное же создание программного продукта, в том числе клиентских приложений и приложений, ответственных за генерацию отчетов и анализ данных, происходит на этапе разработки. Важной частью работы в этом случае является также тестирование и документирование создаваемого продукта. Данный этап обычно завершается созданием дистрибутива приложения или его частей и документированием процедуры его инсталляции.
Несмотря на то что рассмотрение этапов внедрения, эксплуатации и сопровождения, а также выведения из эксплуатации выходит за рамки нашего вводного цикла статей, нельзя не отметить, что эти этапы не менее важны, чем начальные этапы жизненного цикла информационных систем, связанные с проектированием и разработкой.
Авторы многих работ, посвященных общим принципам разработки проектов информационных систем, утверждают, что стоимость исправления ошибки, допущенной на предыдущем этапе жизненного цикла, примерно в десять раз превышает затраты на ее исправление на текущем этапе. В частности, многие разработчики сталкиваются с тем, что ошибки проектирования данных приводят иногда к написанию кода большого объема, так или иначе их компенсирующего, и нередко вызывают проблемы на этапе сопровождения готового продукта. Поскольку проектирование данных следует непосредственно за предпроектным обследованием, очень важно, чтобы эта часть работы над проектом была выполнена максимально качественно. Именно важность этого этапа обусловила стремительный рост популярности такой категории программного обеспечения, как средства проектирования данных, в течение последних десяти лет.
Многие современные СУБД содержат визуальные средства (нередко входящие в состав утилит администрирования), позволяющие создать новую схему базы данных или просмотреть уже имеющуюся. Существуют также и утилиты (поставляемые отдельно от СУБД), позволяющие разрабатывать или редактировать метаданные. Однако в последнее время все более популярными становятся CASE-средства (Computer-Aided System Engineering). Существует несколько типов CASE-средств, но для создания баз данных чаще всего используются те из них, что содержат в своем составе инструменты для создания диаграмм «сущность-связь» и проектирования данных.
Ниже мы рассмотрим процесс проектирования данных с помощью подобных инструментов.
Процесс проектирования данных можно условно разделить на два этапа: логическое моделирование и физическое проектирование. Результатом первого из них является так называемая логическая (или концептуальная) модель данных, выражаемая обычно диаграммой «сущность-связь» или ER (Entity-Relationship) диаграммой, которая представлена в одной из стандартных нотаций, принятых для отображения подобных диаграмм. Результатом второго этапа является готовая база данных либо DDL-скрипт для ее создания.
Логическая модель данных описывает факты и объекты, подлежащие регистрации в будущей базе данных. Основными компонентами такой модели являются сущности, их атрибуты и связи между ними. Как правило, физическим аналогом сущности в будущей базе данных является таблица, а физическим аналогом атрибута — поле этой таблицы.
С логической точки зрения сущность представляет собой совокупность однотипных объектов или фактов, называемых экземплярами этой сущности. Физическим аналогом экземпляра обычно является запись в таблице базы данных. Как и записи в таблице реляционной СУБД, экземпляры сущности должны быть уникальными, то есть полный набор значений их атрибутов не должен дублироваться. И так же, как и поля в таблице, атрибуты могут быть ключевыми и неключевыми.
На этапе логического проектирования для каждого атрибута обычно определяется примерный тип данных (строковый, числовой, BLOB и др.). Конкретизация происходит на этапе физического проектирования, так как различные СУБД поддерживают разные типы данных и ограничения на их длину или точность.
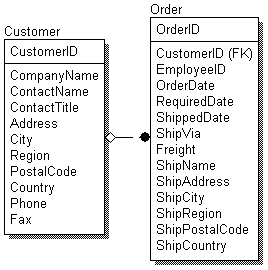
Связь с логической точки зрения представляет собой соотношение между сущностями, которое нередко может быть выражено обычными фразами, например: «Клиент размещает заказ» («A customer places an order» — этой фразой вполне можно описать связь, изображенную на рис. 1), где существительными являются названия связанных между собой сущностей.
Подавляющее большинство средств проектирования данных позволяют создавать ER-диаграммы визуально, изображая сущности и соединяя их связями с помощью мыши. Интерфейс таких средств нередко настолько прост, что позволяет освоить логическое проектирование данных не только разработчику, но и пользователю-непрограммисту, если таковой участвует в проектировании данных как эксперт в предметной области.
Отметим, что на этапе логического проектирования можно описать поведение СУБД при нарушении правил ссылочной целостности, определяемых данной связью (например, при удалении сведений о заказчике, разместившем хотя бы один заказ, для связи, изображенной на рис. 1).
Рис. 1. Пример связи между сущностями логической модели
Для этого многие (но не все!) средства проектирования данных обладают языком шаблонов, не зависящим от СУБД, на котором можно описать алгоритм обработки подобной ситуации, например с помощью соответствующих триггеров или иных объектов базы данных, а также набором стандартных шаблонов, реализующих некоторые типовые алгоритмы подобной обработки (например, отказ от удаления с последующей генерацией диагностического сообщения, каскадное удаление дочерних записей и др.). В процессе создания физической модели (о ней будет рассказано чуть ниже) эти шаблоны преобразуются в код на процедурном расширении языка SQL, применяемом в конкретной СУБД.
Ряд публикаций проводит градацию категорий логических моделей по степени детализации описания сущностей, атрибутов и связей. Модель, обсуждаемая с заказчиком, являющимся обычно экспертом в подлежащей автоматизации предметной области, а не программистом или аналитиком, должна содержать, например, основные сущности и связи, но не обязана иметь их детальную техническую проработку (в частности, описания алгоритмов обработки нарушений ссылочной целостности). В то же время модель, служащая основой технического задания на разработку клиентских приложений, обязана содержать детальное представление структуры данных, ключевых атрибутов, их текстовое описание, а также представлять сущности в нормализованном виде (иногда такая модель называется полной атрибутивной моделью). Иными словами, нормализация модели данных обычно происходит на этапе логического проектирования (подробнее о нормализации рассказано в первой статье данного цикла, опубликованной в КомпьютерПресс № 3’2000).
Отметим, что логическая модель данных, как правило, не связана с конкретной СУБД и не учитывает технические особенности конкретных платформ, применяемых при ее последующей физической реализации.
Физическое проектирование данных осуществляется на основе логической модели. Результатом этого процесса является физическая модель, содержащая полную информацию, необходимую для генерации всех необходимых объектов в базе данных. Для СУБД, поддерживающих системный каталог, физическая модель соответствует его содержимому.
Обычно на основании физической модели создается DDL -скрипт для создания объектов базы данных либо эти объекты создаются непосредственно из CASE-средства — подавляющее большинство современных средств такого класса поддерживает различные механизмы доступа к данным и может выступать в роли клиентского приложения, инициирующего выполнение DDL-скриптов.
Сноска: DDL (Data Definition Language) — язык определения данных, подмножество языка SQL
В процессе физического проектирования следует определить наименования таблиц и типы данных для всех полей. Если необходимо, на этом же этапе описываются представления (если таковые будут создаваться) и может быть создан код хранимых процедур. Далее обычно полагается определить, какие именно объекты и как будут создаваться: например, с помощью каких SQL-предложений создаются индексы, с помощью каких объектов — триггеров или серверных ограничений — реализуется ссылочная целостность, создаются ли индексы для альтернативных ключей и т.д.
Пример диаграммы, отображающей физическую модель для SQL Server 7.0, соответствующую приведенной выше логической модели, представлен на рис. 2
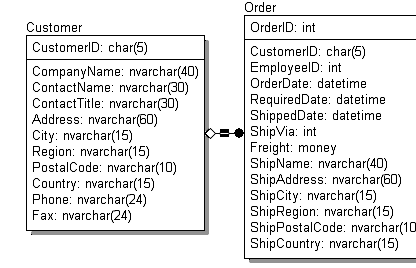
Рис. 2. Пример простейшей физической модели данных
а пример скрипта для создания объектов базы данных, сгенерированный на основании этой модели с помощью одного из рассмотренных ниже CASE-средств, приведен в листинге 1.
CREATE TABLE Customer ( CustomerID char(5) NOT NULL, CompanyName nvarchar(40) NOT NULL, ContactName nvarchar(30) NULL, ContactTitle nvarchar(30) NULL, Address nvarchar(60) NULL, City nvarchar(15) NULL, Region nvarchar(15) NULL, PostalCode nvarchar(10) NULL, Country nvarchar(15) NULL, Phone nvarchar(24) NULL, Fax nvarchar(24) NULL ) ALTER TABLE Customer ADD PRIMARY KEY (CustomerID) CREATE TABLE Order ( OrderID int IDENTITY, CustomerID char(5) NULL, EmployeeID int NULL, OrderDate datetime NULL, RequiredDate datetime NULL, ShippedDate datetime NULL, ShipVia int NULL, Freight money NULL, ShipName nvarchar(40) NULL, ShipAddress nvarchar(60) NULL, ShipCity nvarchar(15) NULL, ShipRegion nvarchar(15) NULL, ShipPostalCode nvarchar(10) NULL, ShipCountry nvarchar(15) NULL, FOREIGN KEY (CustomerID) REFERENCES Customer ) CREATE INDEX XIF1Order ON Order ( CustomerID) ALTER TABLE Order ADD PRIMARY KEY (OrderID)
create trigger tU_Customer on Customer for UPDATE as begin declare @numrows int, @nullcnt int, @validcnt int, @insCustomerID char(5), @errno int, @errmsg varchar(255) select @numrows = @@rowcount if update(CustomerID) begin if exists ( select * from deleted,Order where Order.CustomerID = deleted.CustomerID ) begin select @errno = 30005, @errmsg = ‘Cannot UPDATE Customer because Order exists.’ goto error end end return error: raiserror @errno @errmsg rollback transaction end
Как правило, современные средства проектирования данных поддерживают несколько типов СУБД (например, ERwin фирмы Computer Associates поддерживает более 20 различных СУБД). Уровень поддержки той или иной платформы в разных средствах проектирования данных может быть различен. Например, конкретное средство может поддерживать или не поддерживать для данной СУБД такие особенности, как создание хранимых процедур, генерация объектов физической памяти (табличных пространств, сегментов отката и др.), задание местоположения объектов базы данных в физических объектах и т.д. Поэтому, выбирая средство проектирования данных для решения конкретной задачи, стоит поинтересоваться, каковы его возможности с точки зрения поддержки особенностей той или иной платформы — при удачном раскладе можно сэкономить немало времени на «ручное» доведение создаваемой базы данных (или DDL-скрипта для ее генерации) до необходимого состояния. При этом, естественно, чем больше возможностей и платформ поддерживает конкретное средство проектирования данных, тем дороже оно стоит (следует отметить, что CASE-средства вообще относятся к не самым дешевым программным продуктам — цены на них составляют обычно от одной до нескольких десятков тысяч долларов).
Отметим, что физическое проектирование может включать и дополнительную «ручную» работу по доведению базы данных или скрипта для ее генерации до «товарного» вида. Например, нередко в скрипт также включаются SQL-предложения для заполнения некоторых таблиц, данные которых более или менее постоянны, таких, например, как список субъектов Российской Федерации или справочник телефонных кодов различных стран, а также нестандартные триггеры и процедуры.
В последнее время в техническое задание на разработку приложений нередко включается полное описание физической модели данных или ее части, с которой должно иметь дело разрабатываемое приложение. Подавляющее большинство современных средств проектирования данных предоставляют возможность не только документировать модель, но и создавать по ней отчеты, содержащие те или иные сведения о модели, в том числе сведения, необходимые для разработки приложений.
Некоторые средства проектирования данных позволяют хранить их модели в специальных репозитариях, а также осуществлять коллективное проектирование. Нередко средства проектирования данных дают возможность также присваивать таблицам и полям так называемые расширенные атрибуты, то есть свойства, связанные с отображением их в клиентских приложениях, созданных с помощью какого-либо средства разработки, а также генерировать код приложений для ввода и отображения данных.
Кроме того, подавляющее большинство средств проектирования данных позволяют восстанавливать физическую модель данных их системного каталога и представлять ее в виде ER-диаграммы (этот процесс называется обратным проектированием — reverse engineering), а также производить синхронизацию системного каталога и физической модели. При создании информационной системы, которая должна использовать унаследованные от предшествующих ей систем данные, такая особенность весьма полезна — в этом случае логическое проектирование можно начать с модификации уже имеющейся модели (этот процесс получил название round-trip engineering).
Обсудив, что представляет собой процесс проектирования данных, мы можем перейти к рассмотрению наиболее популярных продуктов, с помощью которых можно его осуществить.
Дополнительную информацию Вы можете получить в компании Interface Ltd.
Отправить ссылку на страницу по e-mail
Обсудить на форуме
| Interface Ltd. Отправить E-Mail http://www.interface.ru |
|
| Ваши
замечания и предложения отправляйте
автору По техническим вопросам обращайтесь к вебмастеру Документ опубликован: 07.08.01 |