Инструменты и технологии
аналитической обработки данных
Обзор современных решений в области
анализа данных
© Андрей
Суслов
Статья была опубликована в издании "Сетевой
журнал" №12.2001
Сегодня
практически каждый специалист, использующий информационные технологии как инструмент
для решения задач бизнеса, знаком с термином OLAP и раскрывающим его понятием
«аналитическая обработка данных». Однако между начальным знанием о технологиях
и принятием решения о внедрении аналитической системы пролегает большой путь
-- от сомнений, а надо ли, до конкретного выбора среди множества различных по
функциональности программных инструментов и вариантов внедрения системы. Статья,
предлагаемая вашему вниманию, призвана помочь найти верное решение на этом пути.
Системы
анализа и отчетности
Все современные
программные системы, связанные с обработкой накопленных данных, а именно результатов
первичной деятельности компании, можно условно разбить на три основные категории:
средства регламентированной отчетности; OLAP-системы, т. е. системы аналитической
обработки данных; средства поддержки Data Mining.
Системы
регламентированной отчетности
Традиционно
именно инструменты для построения регламентированных отчетов используются наиболее
активно. И это объяснимо - ежемесячная и ежеквартальная отчетность существовала
задолго до повсеместной компьютеризации предприятий, а простейшие системы, позволяющие
автоматизировать рутинную работу, появились еще до выхода на рынок Windows.
Кроме того, системы регламентированной отчетности (не будем впредь бояться этого
термина, он означает всего лишь заранее запланированную деятельность, например
в конце месяца или года) наиболее просты и потому относительно дешевы. Традиционно
такие инструменты относились к разряду Desktop-приложений, чего, впрочем, до
определенного времени было вполне достаточно. Простейшие отчеты можно подготовить
в популярных текстовых редакторах и электронных таблицах. Производители специализированных
пакетов, например 1С, поддерживают отчетность как неотъемлемую часть сервиса.
Лишь относительно
недавно многие предприятия и организации по-настоящему перешли на использование
вычислений в среде «клиент -- сервер». Это обусловлено значительным ростом объема
используемых данных, усложнением их локального сопровождения и очевидной выгодой
от перехода на централизованное управление ими. Преимущества это приносило всем
- и конечным пользователям, и специалистам технической поддержки. В этот момент
получили второе рождение и системы регламентированной отчетности. С продуктами,
реализующими их функциональность в среде «клиент -- сервер», вышли на рынок
основные производители систем управления базами данных и фирмы, занимающиеся
разработкой инструментария для СУБД, такие, как Oracle, SPSS, Business Objects.
Эти программные продукты используют данные из реляционных систем и скрывают
от пользователя SQL-запросы за дружественным интерфейсом и «мастерами», по шагам
реализующими создание отчета. Сам же пользователь оперирует привычными для него
понятиями, а не терминами реляционных таблиц.
Некоторые системы
генерации отчетов предлагают отдельные утилиты для пользователей и для администраторов
систем. Администраторы пользуются многими преимуществами, предоставляемыми механизмами
СУБД: авторизация пользователей, контроль над полномочиями пользователей, контроль
над выполнением отчетов и т. д. Запланированные отчеты могут выполняться по
таймеру в неактивное время суток, когда сервер баз данных не перегружен текущей
деятельностью пользователей. Таким образом, по своей функциональности «продвинутые»
инструменты генерации отчетов выходят за рамки подготовки регламентированных
отчетов и приближаются к классу OLAP-систем.
OLAP-системы
Основное назначение
OLAP-систем - поддержка аналитической деятельности, т. е. произвольных (часто
используется термин ad-hoc) запросов пользователей-аналитиков. Если системы
регламентированной отчетности отвечают на вопросы типа «сколько было продано
товара?» или «какова прибыль за последний месяц», то OLAP призван дать ответы,
скажем, на вопросы «насколько надо увеличить расходы на рекламу, чтобы прибыль
выросла на 15%?», или «какие продукты будут в пятерке лучших по показателю прибыльности
из наиболее продаваемых в Нижнем Новгороде?». Цель OLAP-анализа - проверка возникающих
гипотез. Далее мы рассмотрим технологии, позволяющие эффективно выполнять подобного
рода запросы.
Выражаясь математически,
аналитик мыслит многомерными представлениями. Анализируя некоторый показатель,
например объем продаж, он отдает себе отчет, что определяются продажи, собственно,
тем, каков интерес к конкретному товару, какой регион рассматривается и в какой
момент времени.
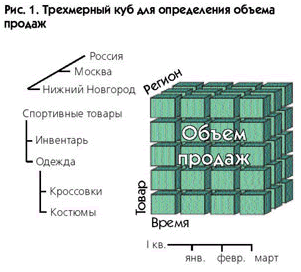
Таким образом, объем продаж может быть представлен в виде трехмерного (в нашем
упрощенном примере) куба (рис. 1), гранями которого изображаются массивы данных
по товарам, регионам и времени, а внутри куба находятся значения объема продаж.
|
|
Выбирая
конкретный товар, регион и временную точку, мы получаем соответствующий
показатель объема продаж. Такое простое, на первый взгляд, представление
данных обеспечивает мощный механизм для аналитических запросов.
Каждый
из массивов данных (граней куба, или, как их называют, размерностей) может
содержать не просто перечень значений, а набор деревьев, или иерархию
значений, где верхнее значение иерархии раскрывается стоящими ниже и т.
д. В каждом кубе обязательно присутствует иерархия времени. На верхнем
уровне расположены годы (десятилетия), ниже - кварталы, затем месяцы,
недели, дни.
Уровень
детализации ниже дней вряд ли будет интересовать пользователя в силу особенности
аналитических задач - один час не меняет общей картины за месяц или квартал,
т. е. не влияет на данные, интересующие аналитика.
|
Для каждой размерности можно
задать более одной иерархии и обобщать их с различных точек зрения. Что важно
- все значения вычисляемого показателя (в нашем примере это объем продаж) будут
физически храниться в иерархиях размерностей, т. е. вычислений «на лету» производиться
не будет. В этом и состоит секрет эффективности выполнения операций аналитических
запросов над многомерными представлениями, ведь аналитик должен получать ответ
на одну из многих своих гипотез практически мгновенно. Производители OLAP-систем
обеспечивают скорость выполнения запросов в пределах одной секунды, максимум пяти.
Однако не стоит уповать на эти цифры - эффективность работы конкретного приложения
очень во многом определяется правильностью построения куба данных, сочетания числа
размерностей с числом иерархий и уровнем детализации данных и даже порядком создания
этих размерностей разработчиком. Например, в одном кубе не следует допускать более
шести-семи размерностей, иначе затрудняется восприятие зависимостей самим аналитиком
и существенно снижается производительность всей системы. В одном аналитическом
приложении, как правило, существует несколько кубов данных, каждый из которых
представляет анализируемый показатель. Для разных кубов может использоваться одна
и та же размерность, причем фактически она будет не дублироваться, а разделяться.
После наполнения куба данными возможно как дополнение, так и обновление значений
размерностей. Значения на более высоких уровнях иерархии и значения внутри куба
будут вычисляться автоматически. Такие обновления производятся не постоянно, а
пакетным образом, раз в несколько дней, в зависимости от требований аналитических
задач. Кубы данных могут быть как физически хранимыми, так и виртуальными, в терминологии
это отражается в названиях "переменная" и "формула" соответственно.
Можно создавать связи (отношения) между размерностями, например, различные категории
товаров, хранящихся в одной размерности, связаны с различными подразделениями
компании, эти товары производящими и выделенными в отдельную компанию.
Все самое интересное с точки
зрения OLAP-анализа начинается с применения этих немногих физических сущностей
и функциональности, поддерживаемой клиентскими средствами. Простая, но достаточно
важная операция над кубом данных - срез и вращение куба, т. е. фиксация одного
или нескольких значений размерностей и просмотр показателя по другим. Современные
интерфейсы позволяют пользователю реализовывать срезы и вращения на уровне drag-and-drop
- с помощью мышки менять на экране местами размерности, столбцы со строками
и т. д. Тем самым пользователь получает возможность анализировать показатель
с различных точек зрения - товара или региона. Данные размерностей можно просматривать
по различным уровням иерархии (например, время по кварталам и месяцам), а можно
задавать и более сложные условия выборки или даже отдельные значения. Многие
программные средства позволяют накладывать условия на анализируемый показатель,
т. е. выбирать только значения показателя выше заданного (например объем продаж
более $150 000), или же минимальные и максимальные значения в каждом регионе
отмечать отдельным цветом. Безусловно, наряду с табличным представлением поддерживается
и графическое, со всеми возможными видами графиков - столбчатых, диаграмм, точками
и линиями на координатной оси, двух и трехмерных. Любая операция вращения и
среза данных выполняется моментально, перепостроение графика занимает доли секунды.
Наиболее интересные и сложные
возможности анализа данных заключаются в прогнозировании и выявлении тенденций.
Подобные вычисления основаны на построении функции экстраполяции на базе имеющегося
(определяемого пользователем) набора исходных данных. Прогнозирование всегда
существенно зависит от особенностей предметной области, поэтому универсальных
алгоритмов экстраполяции не существует. Различные инструменты создания аналитических
приложений содержат несколько алгоритмов, основанных на линейном, экспоненциальном
тренде и учете сезонных колебаний. В ряде систем (например, Oracle Express)
помимо этого предлагается мощный математический аппарат, позволяющий создавать
собственные алгоритмы на основе известных законов, но не более того. Таким образом,
точность прогноза реально определяется разработчиком системы. На практике использование
прогнозирования максимально просто - пользователь задает интервал времени, на
которое производится расчет. В виде таблицы или диаграммы отображается значение
анализируемого показателя, известное для заданного интервала времени, и нажатием
кнопки или вызовом функции меню вычисляются значения этого показателя на будущее.
Другая интересная возможность
OLAP-систем заключается в определении начальных условий по заданному желаемому
результату. Примером такого запроса может служить приведенный в начале данного
раздела вопрос «на сколько надо увеличить расходы на рекламу, чтобы объем продаж
увеличился на 15%?». Другим не менее распространенным видом аналитических запросов
является анализ по принципу «что, если?». В этом случае аналитик имеет возможность
менять значения показателей или размерностей, чтобы проследить зависимость от
них результата.
Современные OLAP-системы
поддерживают многопользовательскую работу. Что же будет, если все вдруг начнут
менять исходные данные? На самом деле изменения выполняются в отдельном адресном
пространстве пользовательского приложения; реально исходные данные при этом
не меняются. Для того чтобы внести изменения, пользователь должен обладать эксклюзивными
правами. На это есть определенные технологические причины, зависящие от архитектуры
аналитических систем и их взаимосвязи с хранилищами данных.
Data Mining
Data Mining, или, в устоявшемся
переводе, извлечение знаний, стоит несколько обособленно в среде аналитических
систем. Системы класса Data Mining наиболее сложны в реализации и решают широкий
класс задач, связанных с выявлением скрытых взаимосвязей в данных. Если OLAP
занимается проверкой возникающих у аналитика гипотез, то Data Mining помогает
формулировать эти гипотезы в том случае, когда аналитик не до конца представляет
цель своего запроса и соответственно не может четко определить его. Класс прикладных
задач для Data Mining потенциально очень широк - от маркетинговых исследований
и оценки надежности клиентов (например, для биллинговых систем) до проверки
существования связей между физическими и юридическими лицами.
В основе систем Data Mining
лежит математический аппарат, базирующийся на алгоритмах систем искусственного
интеллекта. Создание приложений начинается с оценки предметной области и выявления
алгоритмов, дающих наиболее точные результаты для рассматриваемой задачи. Затем
следует настройка и "обучение" алгоритмов, т. е. их прогонка на каком-то
количестве (иногда на сотнях и тысячах) наборов исходных данных с заранее известными
результатами. Прогонка, как правило, проводится в несколько этапов с дальнейшей
настройкой алгоритмов до достижения требуемой точности. Существенную роль играет
анализ и интерпретация полученных результатов.
Современные системы Data
Mining обладают полнофункциональным графическим интерфейсом, поддерживающим
все стадии разработки приложения и развитым пользовательским интерфейсом, упрощающим
применение системы и интерпретацию результатов. Однако от аналитиков, использующих
Data Mining, требуется глубокое знание предметной области, владение математическим
аппаратом и высокая квалификация пользователей программного обеспечения. Среди
подобных инструментов наиболее известны Darwin компании Thinking Machines, ныне
входящей в Oracle Corporation, и Intelligent Miner for Data корпорации IBM.
В последнее время намечается тенденция к интеграции возможностей Data Mining
в серверы баз данных. Так, например, корпорация Microsoft реализовала некоторые
алгоритмы в версии своей СУБД SQL Server 2000.
И снова о хранилищах
данных…
Данные для аналитических
систем не набиваются вручную пользователем и не перекачиваются непосредственно
из OLTP-систем, т. е. баз данных оперативной обработки. Аналитик должен располагать
проверенными данными, отражающими реальную ситуацию в бизнесе. Для создания
достоверной картины и предназначены хранилища данных (Data Warehouses) - непротиворечивые
интегрированные источники данных, собранных из многих других источников и внешних
словарей и зачастую представленных в специальных, удобных для анализа структурах.
В рамках одной системы предполагается наличие избыточности данных для повышения
скорости выполнения аналитических запросов.
Бум развития хранилищ данных
(ХД) пришелся на конец 90-х годов. Сегодня для многих технология хранилищ данных
олицетворяет огромные массивы собранной информации, на создание которых затрачены
масса времени и колоссальные средства, неокупившиеся и поныне. Многие проекты
по созданию хранилищ данных действительно заканчивались провалом, однако не
стоит преждевременно хоронить идеи, разумное применение которых уже неоднократно
приносило огромные прибыли.
 |
Неудачи
проектов по созданию ХД зачастую объясняются желанием интегрировать «всё
и вся» и в результате получить единый источник информации для всех подразделений
компании. Чем больше источников данных было вовлечено в этот процесс, тем
сложнее становилось получить работающую высокопроизводительную систему.
ХД по определению ориентировано на потребности конечных пользователей --
аналитиков, а не на функциональность какого-либо приложения. В этой связи
логично и разумно ограничиваться требованиями отдельной группы аналитиков,
работающих в рамках одной тематики. Практически одновременно с понятием
хранилищ данных появился термин "витрины данных" (Data Marts),
означающий по сути ХД для отдельной группы пользователей. Изначально предлагалось
использовать витрины данных над хранилищем как его подмножества на уровне
детальных данных с необходимыми собственными агрегациями.В современной литературе
|
довольно редко встречается
термин "витрины данных", а под хранилищами теперь понимают массивы информации,
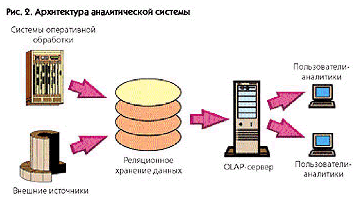
пригодные и специально подготовленные для аналитической обработки. Таким образом,
современная OLAP-система может выглядеть, как представлено на рис. 2. Все компоненты
системы, от источников данных до пользовательских мест, могут быть как физически
распределены, так и локализованы на одном компьютере.
Что важно знать при построении
аналитических систем
В литературе можно встретить
несколько аббревиатур, обозначающих различные варианты реализации OLAP-систем
- MOLAP, ROLAP, HOLAP и DOLAP.
MOLAP - многомерный (multidimensional)
OLAP. Предполагает создание явного, физически хранимого многомерного куба (или
нескольких кубов) с выполнением аналитических запросов только над ними, без
обращения к хранилищу данных. Скорость выполнения запросов определяется только
правильностью построения многомерной базы. Однако в этом случае многомерная
база избыточна, поскольку копирует все детальные (и, возможно, агрегатные) данные
из хранилища.
ROLAP - реляционный (relational)
OLAP. Аналитические запросы строятся над виртуальным многомерным представлением
данных, реально их выполнение происходит на уровне хранилища данных, т. е. выполняются
SQL-запросы над реляционной системой. В дальнейшем будем предполагать, что ХД
реализованы именно над реляционными СУБД, поскольку, как показал мировой опыт,
это единственно возможная схема при сколько-нибудь существенных объемах данных.
При такой архитектуре ядро многомерного сервера баз данных отвечает за представление
данных в многомерном виде, передачу запросов на выполнение реляционному серверу
и интерпретацию результатов.
HOLAP - hybrid OLAP. Компромиссный
вариант между двумя предыдущими подходами, при котором не все данные переводятся
в многомерное представление. Например, детальные данные остаются на уровне ХД,
в то время как в кубе хранятся только их агрегации. Выполнение запроса над такой
моделью будет включать также обращение к реляционному серверу, если запрос затрагивает
детальные данные. На практике именно гибридная модель применяется наиболее часто,
поскольку за счет распределения нагрузки на многомерный и реляционный серверы
удается достичь оптимальной производительности при выполнении аналитических
запросов.
DOLAP - настольные (desktop)
системы OLAP. Такой термин практически не встречается в литературе, однако класс
DOLAP-приложений вполне успешно существует. Сюда можно отнести, например, продукты
от Brio Software и Business Objects. Настольные системы предназначены для аналитической
обработки небольших объемов данных без выполнения сложных видов анализа. Функциональность
настольных приложений, как правило, ограничивается возможностями визуального
представления данных, вращения и выполнения срезов куба.
Основные поставщики на рынке
OLAP, такие, как Oracle Corporation, Arbor Software и Seagate Software, в своих
продуктах предоставляют возможность использовать любой из трех (MOLAP, ROLAP
и HOLAP) вариантов реализации OLAP-систем.
При создании аналитической
системы необходимо понимать, что ее производительность определяется правильно
выбранной архитектурой системы для поставленного класса задач и заданного объема
данных. Именно поэтому наиболее гибкой считается реализация в гибридной архитектуре,
где разработчик может использовать отработанные механизмы, предоставляемые реляционными
базами данных, такими, как оптимизация выполнения соединений таблиц и материализованные
представления (materialized views), в сочетании с полноиндексной структурой
многомерных баз данных, позволяющей делать мгновенные выборки по кубам данных.
Может возникнуть справедливый
вопрос, насколько все-таки необходимы многомерные базы данных для аналитических
приложений и в каких случаях можно обойтись без них? Ведь популярные электронные
таблицы Microsoft Excel предоставляют многие возможности по визуализации и манипулированию
данными. Стоит ли создавать хранилище или витрину данных только для поддержки
аналитики в компании?
С технологической точки
зрения все определяется объемами данных, доступными для анализа, и функциональными
возможностями, которыми хочет располагать аналитик. Многомерные базы данных
способны обрабатывать сотни мегабайт данных (например, в Oracle Express Server
число значений в одной размерности ограничивается сверху величиной 231), на
их основе могут строиться сложные математические модели прогнозирования и анализа
тенденций. Кроме того, многомерные базы данных предполагают одновременную работу
многих пользователей, в то время как настольные системы визуализации данных
требуют локальной подготовки данных для анализа с дальнейшим их использованием
только одним аналитиком. Создание хранилища дает существенное преимущество не
только в явном определении процедур согласования, фильтрации и приведении данных
к единому формату. ХД может также взять на себя часть накладных расходов по
поддержке агрегаций, реализованных в таблицах суммаризации (summary tables),
или материальные представления, что сократит время ввода данных в многомерную
базу и позволит оптимизировать запросы, используя мощный аппарат реляционных
систем.
Будущее аналитических
систем
В последние годы очевидна
тенденция к централизованной обработке информации и управлению данными. Это
связано с ростом производительности вычислительных систем в целом, быстродействием
средств коммуникации, а также смещением вычислений и технологий в интернет.
Для предприятий и организаций становится выгоднее иметь единый вычислительный
комплекс и много дешевых рабочих мест, настройка и сопровождение которых выполняется
удаленно.
В индустрии программного
обеспечения также заметен постепенный переход от отдельных программных компонентов
к единым вычислительным средам. В стратегические планы развития OLAP-систем
ряда производителей, например Oracle, входит дальнейшая интеграция многомерного
и реляционного серверов, а впоследствии и полное их слияние. Подобная тенденция
наблюдается и применительно к системам извлечения знаний. Microsoft, Oracle
и другие производители встраивают функциональность систем Data Mining в ядро
СУБД и обеспечивают ее поддержку на уровне языка манипулирования данными.
Уже сегодня уровень развития
и многообразие возможностей предлагаемых аналитических систем позволяют с выгодой
использовать накопленные данные и определять оптимальную стратегию развития
бизнеса.
Дополнительная
информация
Обсудить
на форуме
Отправить
ссылку на страницу по e-mail