
Введение
В начале 90-х годов прошлого столетия возник огромный интерес к парадигме объектов и смежным технологиям. Были разработаны и приняты новые языки программирования, основанные на этой парадигме (такие как Smalltalk, Eiffel, C++ и Java). Все это сопровождалось чрезмерным и сбивающим с толку количеством методов проектирования объектно-ориентированного программного обеспечения (ОО) и систем обозначений процесса моделирования. Так, в своем исчерпывающем обзоре объектно-ориентированных методов проектирования и анализа (охватывающем более 800 страниц) Грэхем (Graham) перечислил более 50 основополагающих методов. Исходя из того, что объектная парадигма состоит из относительно небольшого набора фундаментальных концепций (включая инкапсуляцию, наследование и полиморфизм), было не просто перекрыть и концептуально охватить все эти методы - многие из них скрыты за обозначениями, другие имеют незначительные различия. Это вызвало большое непонимание и излишнюю фрагментацию рынка, которые в свою очередь препятствовали принятию новой полезной парадигмы. Разработчики программного обеспечения должны были делать трудный, связывающий их выбор между внутренне несовместимыми языками, инструментальными средствами, методами и поставщиками.
По этой причине, когда Rational Software предложила инициативу Unified Modeling Language (UML) (под руководством Гради Буча (Grady Booch), Ивара Якобсона (Ivar Jacobson) и Джима Рамбо (Jim Rumbaugh)) реакция была немедленной и позитивной. Целью проекта было не предложение чего-то нового, а (через совместную работу лидеров передовой технической мысли) объединение наилучших функциональных возможностей различных ОО подходов в один, независимый от производителей язык моделирования и систему обозначений. По этой причине UML очень быстро стал широко практикуемым стандартом. После его принятия организацией Object Management Group в 1996 он стал утвержденным промышленным стандартом.
С тех пор, UML:
- Был принят и поддержан большинством производителей средств моделирования.
- Стал важнейшей частью компьютерной науки и инженерных учебных планов в университетах по всему миру и различных профессиональных программ обучения.
- Используется академическими и другими исследователями как удобный общий язык.
UML также помог сформировать всеобщее понимание значения моделирования при работе со сложным программным обеспечением. И хотя эта чрезвычайно полезная методика почти также стара, как и само программирование (как очень ранние примеры - блок-схемы и машины с конечным числом состояний), большинство разработчиков медленно принимают ее за нечто большее, нежели полезное второстепенное средство. Справедливости ради надо сказать, что такое положение вещей доминирует до сих пор. Вот почему управляемые моделями методы встречают большое сопротивление в сообществе.
Существуют очень веские причины такой ситуации (так же как и некоторые несущественные причины, такие как присущее человеку недоверие к нововведениям). Основная причина заключается в том, что программные модели часто могут быть непредсказуемым образом ужасно неадекватны: естественно, практическая ценность любой модели прямо пропорциональна ее адекватности. Если модели нельзя доверять в том, что она соответствует истинному положению вещей, которое вы хотите знать о представляемой ею программной системе, то это много хуже бесполезности такой модели, поскольку может привести вас к ошибочным выводам. Следовательно, ключом повышения ценности программных моделей является сужение разрыва между ними и системами, которые они моделируют. Парадоксально, но, как будет показано в данной статье позднее, это легче сделать в области программирования, чем в любой другой инженерной дисциплине.
Некоторая неадекватность программных моделей может быть объяснена чрезвычайно детализированной и чувствительной природой современных технологий языков программирования. Небольшие опечатки и едва обнаруживаемые ошибки кодирования (такие как не выровненные указатели или не инициализированные переменные) могут иметь огромные последствия. Например, существует хорошо документированная ситуация, когда один отсутствующий break в операторе switch привел к недоступности службы переговоров на большие расстояния для большой части Соединенных Штатов, что привело к незамедлительным экономическим потерям. Если такая с виду незначительная деталь может привести к столь ужасным последствиям, как мы можем гарантировать адекватность моделей (поскольку модели по определению скрывают или устраняют детали)?
Управляемая моделями разработка
Решением этой головоломки является формализованная связь модели с ее соответствующей программной реализацией через одно или несколько автоматизированных преобразований модели. Возможно, наилучшим и наиболее успешным примером этого является компилятор, который преобразует язык программирования высокого уровня в эквивалентную реализацию на машинном языке. Моделью в этом случае является программа, написанная на языке высокого уровня, которая, как и все полезные модели, скрывает несущественные детали об индивидуальных особенностях нижележащей технологии вычислений (такие как внутренний размер слова, количество аккумуляторов и индексных регистров, тип ALU и т.д.).
Интересно отметить, что мало какие (если таковые вообще есть) иные инженерные области могут обеспечить такую тесную связь между моделью и соответствующим инженерным артефактом. Дело в том, что моделируемым артефактом является программа, а не аппаратура. Модель физического артефакта любого типа (например, автомобиль, здание, мост и т.д.) неизбежно включает неформальный этап абстрагирования физических характеристик в соответствующую формальную модель (например математическую или иерархическую модель). Аналогично и реализация абстрактной модели с использованием физических материалов включает неформальное преобразование от абстракции в нечто конкретное. Неформальная природа этого этапа приводит к неадекватности, которая, как было отмечено выше, может перевести модели в разряд неэффективных или даже контрпродуктивных. Однако в программировании такое преобразование может быть в принципе выполнено формально в любом направлении.
Потенциал, скрытый за этой мощной комбинацией абстракции и автоматизации, ведет к появлению новых технологий моделирования и соответствующих методов разработки, относящихся к так называемой управляемой моделями разработке (model-driven development - MDD). Определяющей особенностью MDD является то, что модели становятся основными артефактами дизайна программы, перемещая, таким образом, фокус с соответствующего кода программы. Они выступают в качестве чертежей, из которых различные автоматизированные и полуавтоматизированные процессы извлекают программы и соответствующие модели. Степень автоматизации, используемая сегодня в MDD, варьируется от извлечения простого скелетного кода до генерирования полного автоматического кода (что сравнимо с традиционной компиляцией). Очевидно, что чем выше уровни автоматизации, тем более адекватными являются модели и тем большими преимуществами обладает MDD.
Управляемые моделями методы разработки программного обеспечения не являются чем то кардинально новым - они использовались с переменным успехом и раньше. Причиной возросшего внимания к ним в настоящее время является то, что поддерживающие технологии достигли такого уровня, при котором практической автоматизации поддается значительно больше процессов, чем раньше. И не только с точки зрения эффективности, но и масштабируемости, а также способности таких инструментальных средств интегрироваться с традиционными средствами и методами. Это развитие отражается в появлении MDD-стандартов, что ведет к унификации соответствующих средств и очевидным выгодам для пользователей. Одним из таких стандартов является пересмотренная версия Unified Modeling Language.
Обоснование пересмотра UML 1
UML2.0 - это первая основная версия стандарта UML, за которой последовала серия младших редакций. Зачем нужно было пересматривать UML?
Основной мотивацией для пересмотра языка было желание обеспечить лучшую поддержку MDD-средств и методов. За последнее десятилетие ряд производителей разработали основанные на UML инструментальные средства, которые поддерживали значительно более высокий уровень автоматизации, чем традиционные CASE-средства (computer-aided software engineering).
Для поддержки этого более высокого уровня автоматизации было необходимо определить UML значительно более точным способом, чем это было сделано в оригинальном стандарте. (Оригинальный стандарт UML был главным образом спроектирован как вспомогательное средство для неформального фиксирования и передачи цели проектирования). К сожалению, эти определения менялись от производителя к производителю, угрожая снова однажды привести к тому же типу фрагментации, который оригинальный стандарт намеревался устранить. Новая версия стандарта смогла исправить ситуацию.
Кроме того, после десятилетнего практического опыта использования UML, а также после появления важных новых технологий (таких как Web-приложения и ориентированные на службы архитектуры) были идентифицированы новые возможности моделирования. И хотя практически все они могли бы быть представлены соответствующими комбинациями имеющихся UML-концепций, существовали очевидные преимущества введения некоторых из них как первоклассных встроенных функций языка.
Наконец, в течение этого же периода времени индустрия узнала многое о надлежащих способах использования, структурирования и определения языков моделирования. Например, сейчас появляются теории метамоделирования и преобразований модели, которые налагают определенные требования на то, как должен быть определен язык моделирования. Хотя все еще отсутствует утвердившаяся и систематическая теория проектирования языков моделирования, сравнимая с современной теорией проектирования языков программирования, эти и похожие разработки должны быть включены в UML, чтобы гарантировать ее полезность и долговечность.
Отличительные черты UML 2.0
Новые разработки в UML 2.0 могут быть сгруппированы в следующие пять основных категорий, перечисленных в порядке значимости:
- Значительно увеличена степень точности в определении языка: Это результат требования обеспечить поддержку более высоких уровней автоматизации, необходтмых для MDD. Автоматизация подразумевает исключение двусмысленности и неточности моделей (и, следовательно, в языке моделирования) так, чтобы компьютерные программы могли преобразовывать и манипулировать моделями.
- Улучшена организация языка: Это характеризуется модульностью, которая не только делает язык более доступным для новых пользователей, но и содействует совместной работе инструментальных средств.
- Значительно улучшена способность моделирования широкомасштабных программных систем: Некоторые современные приложения представляют собой интеграцию существующих автономных приложений в более комплексные системы. Эта тенденция вероятно будет продолжаться, что приведет к появлению еще более сложных систем. Для поддержки этих тенденций в язык были добавлены новые гибкие иерархические возможности для поддержки моделирования программного обеспечения на различных уровнях сложности.
- Улучшена поддержка зависимой от домена (domain-specific) специализации: Практика использования UML продемонстрировала ценность так называемых механизмов "расширения". Они были объединены и улучшены для разрешения более простой и более точной детализации базового языка.
- Общая консолидация, рационализация и прояснение различных концепций моделирования: Это привело к упрощению и более согласованному языку. Сюда входит консолидация и, в некоторых случаях, удаление избыточных концепций, уточнение многочисленных определений и добавление текстовых пояснений и примеров.
Сейчас мы подробно исследуем каждую из них
Степень точности
Большинство ранних языков моделирования программ были определены неформально, мало внимания уделялось точности. Чаще концепции моделирования выражались с использованием неточных и естественных языков. Это считалось достаточным на то время, поскольку большинство языков моделирования использовались либо для документирования, либо для того, что Мартин Фоулер (Martin Fowler) назвал созданием эскиза дизайна (design sketching). Идея состояла в передаче основных свойств дизайна, оставляя работу с деталями на время реализации.
Однако это часто приводило к путанице, поскольку модели, выраженные на таких языках, могли быть (и часто были) интерпретированы по-разному различными индивидуумами. Более того, пока вопрос интерпретации модели не возникал явно, эти отличия могли остаться незамеченными и обнаружиться только на последних этапах разработки (когда стоимость исправления возникающих проблем намного выше).
Для минимизации двусмысленности (и в отличие от большинства языков моделирования того времени) было специфицировано первое стандартизованное определение UML, использующее метамодель. Это модель, определяющая характеристики каждой UML-концепции моделирования и свои взаимоотношения с другими концепциями моделирования. Метамодель была определена при помощи элементарного подмножества UML и дополнена набором формальных ограничений, написанных на языке Object Constraint Language (OCL).
Примечание: Это подмножество UML, первоначально охватывающее концепции, определенные в диаграммах классов UML, называется Meta-Object Facility (MOF). Это подмножество было выбрано потому, что его можно было использовать для определения других языков моделирования.
Эта комбинация представляла формальную спецификацию абстрактного синтаксиса UML, называемого так из-за его независимости от реальной системы обозначений, или конкретного синтаксиса (то есть, текста и графики), который использовался для представления моделей. Другими словами, она определила набор правил, которые можно было использовать для проверки грамматической правильности данной модели. Например, такие правила позволили бы нам определить, что подключение к двум UML-классам при изменении состояния конечного автомата является некорректным.
Однако степень точности, используемая в этой первой UML-метамодели, была недостаточной для поддержки всего потенциала MDD. В частности, спецификация семантик (или значений) UML-концепций моделирования оставалась неадекватной для таких основанных на MDD операциях, как автоматическое генерирование кода или формальная верификация.
Поэтому используемая в определении UML 2.0 степень точности была значительно увеличена. Это было достигнуто следующими средствами:
- Существенным рефакторингом инфраструктуры метамодели: Инфраструктура UML 2.0 включает в себя набор низкоуровневых концепций моделирования и шаблонов, которые в большинстве случаев слишком рудиментарны или слишком абстрактны для того, чтобы быть использованными непосредственно в моделировании программных приложений. Однако их относительная простота дает им возможность быть значительно более точными по своей семантике и соответствовать правилам грамматической корректности. Такие тонко настроенные концепции затем комбинируются различными способами для создания более сложных концепций моделирования пользовательского уровня. Например, в UML 1 обозначение права собственности (то есть, элементы, владеющие другими элементами), концепция пространства имен (именованный набор элементов с уникальными именами) и концепция классификаторов (элементы, которые могут быть классифицированы в соответствии с их функциями) были запутанным образом связаны в одну семантически сложную конструкцию. (Обратите внимание, что это также означало невозможность использования любой из этих концепций без использования двух других.) В новой инфраструктуре UML 2.0 эти концепции были разделены и их синтаксис и семантики определены раздельно.
- Расширенным и более точным описанием семантики: Определение семантики концепций моделирования в UML 1 было во многом проблематичным. Уровень описания был крайне неравномерным, некоторые области имели расширенные и детализированные описания (например, конечные автоматы), в то время как другие имели краткое объяснение, либо не имели его вовсе. В UML 2.0 было уделено значительно больше внимания семантике и, в частности, в ключевой области - основах динамики поведения (см. ниже).
- Четко определенной динамической семантической средой: Спецификация UML 2.0 разъясняет некоторые из критических пробелов семантики оригинальной версии. Эта среда изображена на рисунке 1. В частности, в этой среде четко определены следующие вопросы:
- Структурная семантика ссылок и экземпляров во время исполнения
- Взаимоотношение между структурой и поведением
- Основы семантики и модель обусловленности разделяется всеми современными высокоуровневыми поведенческими формализмами в UML (то есть, конечными автоматами, активностями и взаимодействиями), также как и потенциальными будущими. Это также гарантирует, что объекты, чье поведение выражается различными формализмами, могут взаимодействовать друг с другом.
Рисунок 1. Семантическая среда UML 2.0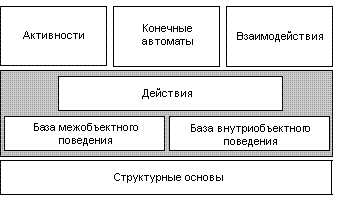
Новая архитектура языка
Одним из прямых последствий повышенного уровня точности в UML 2.0 является то, что определение языка стало объемнее даже без учета новых функциональных возможностей. Это обычно может огорчить, особенно принимая во внимание то, что оригинальный UML критиковали за его чрезмерный объем (и, следовательно, за трудность его изучения и использования).
Такая критика обычно игнорирует тот факт, что UML предназначен для решения одних из наиболее сложных проблем современного программного обеспечения, и что эти проблемы требуют достаточно мощных средств. (Успешные технологии, такие как автомобилестроение и электроника, никогда не станут проще; это часть человеческой натуры - постоянно требовать большего от оборудования, что в конечном итоге ведет к появлению все более усовершенствованных средств. Например, никто даже не думает строить современный небоскреб при помощи основных ручных инструментов.
Тем не менее, учитывая эту сторону вопроса, а также для того, чтобы решить проблему сложности языка, UML 2.0 был разбит на модули таким образом, чтобы разрешить избирательное использование этих модулей языка. Общий вид этой структуры показан на рисунке 2. Она состоит из основы, охватывающей общие концепции (такие как классы и ассоциации), выше которой находится набор вертикальных подъязыков или языковых модулей. Каждый из них предназначен для моделирования конкретной формы или аспекта (таблица 1). Эти вертикальные языковые модули в общем независимы друг от друга, поэтому вы можете использовать их независимо друг от друга. (Обратите внимание, что это отличается от работы UML 1, где, например, формализм "активность" полностью основывается на формализме "конечный автомат".)
Рисунок 2. Архитектура языка UML 2.0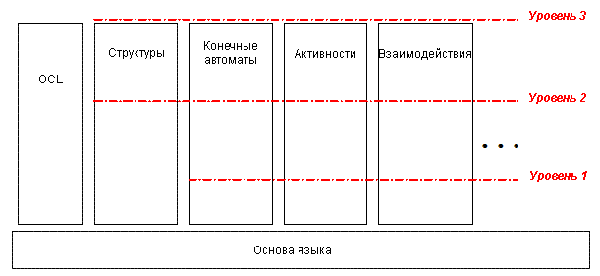
К тому же, вертикальные языковые модули иерархически организованы в три уровня, каждый последующий уровень добавляет новые функциональные возможности моделирования к доступным уровнем ниже. Это придает дополнительную размерность модульности, так что, даже внутри данного языкового модуля является возможным использовать только определенные подмножества.
Такая архитектура дает возможность изучать и использовать только то подмножество UML, которое вам больше подходит. Нет больше необходимости осваивать UML в полном объеме для того, чтобы эффективно его использовать, также как и не нужно изучать английский язык полностью для нормального общения. По мере приобретения опыта вы можете при необходимости последовательно знакомиться с более мощными концепциями моделирования.
Таблица 1. Языковые модули UML 2.0
| Языковый модуль | Предназначение |
|---|---|
| Действия (Actions) | (Основа) моделирование тонко-настроенных действий |
| Активности (Activities) | Моделирования поведения потока данных и управления |
| Классы (Classes) | (Основа) моделирование базовых структур |
| Компоненты (Components) | Сложное структурное моделирование для компонентных технологий |
| Развертывания (Deployments) | Моделирование процесса развертывания |
| Общие поведения(General Behaviors) | (Основа) общая база семантики поведения и моделирование времени |
| Информационные потоки (Information Flows) | Моделирование потока абстрактных данных |
| Взаимодействия (Interactions) | Моделирование поведения взаимодействия объектов |
| Модели (Models) | Организация модели |
| Профайлы (Profiles) | Настройка языка |
| Конечные автоматы (State Machines) | Моделирование управляемого событиями поведения |
| Структуры (Structures) | Моделирование комплексной структуры |
| Шаблоны (Templates) | Моделирование шаблонов |
| Прецеденты (Use Cases) | Моделирование требований неформального поведения |
Как часть такой же реорганизации архитектуры в UML 2.0 были значительно упрощены определение и структура совместимости. В UML 1 базовые модули совместимости были определены пакетами метамодели с буквально сотнями возможных комбинаций. (Фактически, поскольку UML 1 формализовал обозначение незавершенной совместимости в данной точке согласования, возможное количество различных комбинаций возможностей, которые позволили производителям объявлять о совместимости, было на порядок выше.) Это означало, что было очень маловероятно найти два или более средств моделирования, которые могли бы обмениваться моделями, поскольку каждый, вероятно, поддерживал бы различную комбинацию пакетов.
В UML 2.0 определены только три уровня совместимости, которые соответствуют уже упоминавшимся уровням иерархии языковых модулей. Они определены таким образом, что модели уровня (n) являются совместимыми с моделями любого старшего уровня (n+1 и т.д.). Другими словами, инструментальное средство, совместимое с данным уровнем, может импортировать модели (без потерь информации) из инструментальных средств, совместимых с любым уровнем, равным или меньшим его собственному.
Примечание: Формально, UML 2 также определяет четыре уровня (Level 0), но это внутренний уровень, предназначенный для использования только разработчиками инструментальных средств.
Определены следующие четыре уровня совместимости:
- Совместимость абстрактного синтаксиса
- Совместимость конкретного синтаксиса (то есть, системы обозначений UML)
- Совместимость абстрактного и конкретного синтаксиса
- Совместимость абстрактного и конкретного синтаксиса, и совместимость со стандартом обмена диаграммами
Таким образом, существует максимум 12 различных комбинаций совместимости с четкими взаимосвязями между ними (например, совместимость абстрактного и конкретного синтаксиса согласуется только с совместимостью конкретного синтаксиса или только абстрактного синтаксиса). Следовательно, в UML 2.0 обмен моделями между совместимыми инструментальными средствами различных производителей становится не только теоретической возможностью.
Возможности моделирования широко-масштабных систем
Количество добавленных в UML 2.0 возможностей относительно невелико. Это сделано преднамеренно для обхода печально известного эффекта второй системы, когда язык "раздувается" от чрезмерного количества новых возможностей, востребованных очень разнообразным сообществом пользователей. Фактически, большинство из новых возможностей моделирования являются, по существу, просто расширениями существующих возможностей, позволяющими вам использовать их для моделирования крупномасштабных программных систем.
Кроме того, все эти расширения были выполнены с использованием одинакового подхода: рекурсивное применение одного и того же базового набора концепций на различных уровнях абстракции. Это означает, что вы можете скомбинировать элементы модели данного типа в модули, которые, в свою очередь, вы можете использовать как строительные блоки для комбинирования таким же способом на следующем уровне абстракции, и т.д. Это аналогично процедурам в языках программирования, которые могут быть вложены внутри других процедур с любой желаемой глубиной.
В частности, таким способом были расширены следующие функциональные возможности моделирования:
- Сложные структуры
- Активности
- Взаимодействия
- Конечные автоматы
На первые три из них приходится более 90 % новых возможностей в UML 2.0.
Сложные структуры
Основой для этого набора функциональных возможностей послужил длительный опыт работы с различными языками описания архитектуры, такими как UML-RT, Acme и SDL. Эти языки характеризуются относительно простым набором графических концепций: базовые структурные узлы, называемые частями (part), которые могут иметь один или несколько портов (port) и которые соединяются через коммуникационные каналы, называемые коннекторами (connector) (как показано на рисунке 3). Эти конструкции могут инкапсулироваться в модулях более высокого уровня, имеющих свои собственные порты, которые могут быть скомбинированы с другими модулями высокого уровня в модулях еще более высокого уровня, и т.д.
Рисунок 3.Концепции моделирования сложной структуры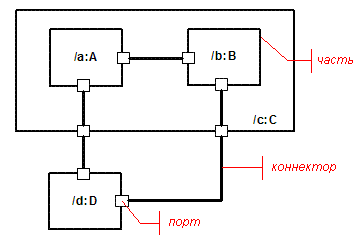
В значительной степени эти концепции уже можно было найти в определении сотрудничества в UML 1, за исключением того, что они не применялись рекурсивно. Для разрешения рекурсии структура сотрудничества вкладывается в спецификацию класса; это означает, что все экземпляры этого класса будут иметь внутреннюю структуру, указанную в определении класса. Например, на рисунке 3, части /a:A и /b:B вложены в часть /c:C, которая представляет экземпляр составного структурного класса C. Другие экземпляры этого класса будут иметь такой же структурный шаблон (включая все порты, части и соединения).
С этими тремя простыми концепциями (и при их рекурсивном применении) вы можете смоделировать сколь угодно сложные архитектуры программного обеспечения.
Активности
Активности в UML используются для моделирования потоков различного типа: потоков сигналов или данных, а также алгоритмических или процедурных потоков. Излишне говорить, что существует огромное число областей применения и приложений, которые интерпретируются наиболее природным способом при помощи таких основанных на потоках описаний. В частности, этот формализм был выбран проектировщиками бизнес-процессов, а также системными инженерами, которые хотят рассматривать свои системы исключительно как процессоры, через которые проходят сигналы. К сожалению, в UML 1 моделирование активности имело несколько серьезных ограничений по типу потоков, которые могли быть представлены. Многие из этих ограничений являлись следствием того факта, что активности были наложены поверх базового формализма конечных автоматов и были, таким образом, ограничены семантикой конечных автоматов.
UML 2.0 заменил фундамент конечных автоматов намного более общей семантической базой, которая устранила все эти ограничения. (Фактически, семантический фундамент представлен вариантом обобщенных помеченных сетей Петри [pet].) Более того, в базовый формализм был добавлен богатый набор новых и усовершенствованных функций моделирования, инспирированный несколькими формализмами описания бизнес-процессов, ставших промышленным стандартом, включая известный BPEL4WS. К ним относятся следующие возможности :
- Прерываемые потоки активности
- Усовершенствованные формы управления параллельными процессами
- Разнообразные схемы буферизации
В результате в UML имеется очень богатый набор средств моделирования, который может представлять широкое разнообразие типов потоков.
Как и в случае со сложными структурами, вы можете рекурсивно сгруппировать активности и их взаимодействующие потоки в активности более верхнего уровня с четко определенными входными и выходными параметрами. Вы можете, в свою очередь, комбинировать их с другими активностями для формирования более сложных активностей, вплоть до наивысших системных уровней.
Взаимодействия
Взаимодействия в UML 1 были представлены либо как последовательные аннотации о сообщениях, либо как отдельные последовательные диаграммы. К сожалению, отсутствовали две фундаментальных возможности:
- Способность к повторному использованию последовательностей, которые могут повторяться в контексте более экстенсивных (более высокого уровня) последовательностей. Например, последовательность, подтверждающая пароль, может появляться в нескольких контекстах данного приложения. Без возможности записать такую повторяющуюся последовательность в отдельных модулях ее придется определять множество раз. Это не только дополнительные накладные расходы, но также и усложнение эксплуатации модели (например, когда последовательность нужно изменить).
- Способность адекватно смоделировать различные сложные потоки управления, которые являются обычными при представлении взаимодействий сложных систем. Сюда входят повторяющиеся субпоследовательности, альтернативные способы выполнения, параллельное и независимое от очередности выполнение и т.д.
К счастью проблема обозначения сложных взаимодействий была всесторонне изучена в области телекоммуникаций, в которой сформировался стандарт в определении коммуникационных протоколов, основанный на многолетнем практическом использовании. Этот стандарт был использован как основа для представления взаимодействий в UML 2.0.
Ключевым новшеством было представление взаимодействия как отдельного именованного модуля моделирования. Такое взаимодействие представляет собой последовательность межобъектных взаимодействий произвольной сложности. Оно даже может быть параметризованным для возможности спецификации шаблонов контекстно-независимого взаимодействия.
Вы можете активизировать эти объединенные в пакет взаимодействия рекурсивно из взаимодействий более высокого уровня, аналогично активизации макросов (рисунок 4). Как можно было ожидать, вы можете вкладывать их с произвольной степенью глубины. Более того, взаимодействия могут служить в качестве операндов в сложных конструкциях управления, таких как циклы (например, данное взаимодействие может понадобиться повторить несколько раз) и ветвления. UML 2.0 определяет несколько удобных конструкций моделирования этого типа, обеспечивая вас очень богатыми инструментами для моделирования сложного сквозного поведения на любом уровне декомпозиции.
Рисунок 4. Пример модели сложного взаимодействия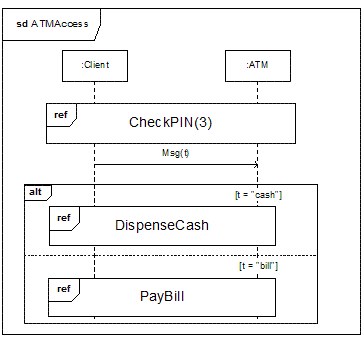
На рисунке 4 изображена модель расширенного взаимодействия. В данном случае взаимодействие ATMAccess сначала "инициирует" другую транзакцию меньшего уровня с именем CheckPIN (содержание этого взаимодействия на диаграмме не показано). Обратите внимание, что последнее взаимодействие имеет параметр (в данном случае, скажем, максимальное количество попыток ввода PIN-кода перед аннулированием транзакции). После этого клиент посылает асинхронное сообщение, указывающее требуемый тип взаимодействия и (в зависимости от указанного значения) выполняется либо взаимодействие DispenseCash, либо взаимодействие PayBill.
Взаимодействия в UML 2.0 могут быть представлены диаграммами последовательностей (как показано в примере выше), а также другими типами диаграмм (включая основанные на кооперации формы, определенные в UML 1). Существует даже неграфическое табличное представление.
Конечные автоматы
Главная новая возможность, добавленная в конечные автоматы в UML 2.0, совершенно аналогична предыдущим случаям. Основная идея: вы можете сделать составное состояние полностью модульным с явными точками начала перехода и конца перехода. Это, в свою очередь, позволяет вам определить внутреннюю декомпозицию этого состояния отдельно при помощи дискретной и пригодной к повторному использованию спецификации конечного автомата. То есть, одна и та же спецификация может повторно использоваться в нескольких местах внутри конечного автомата или другого конечного автомата. Это упрощает спецификацию шаблонов общего поведения в различных контекстах.
Еще одним примечательным новшеством конечных автоматов в UML 2.0 является уточнение наследования конечных автоматов между классами и его подклассами.
Возможности специализации языка
Опыт UML 1 показал, что самый обычный способ применения UML - сначала определить UML-профиль для конкретной проблемы или области применения, а затем использовать этот профиль вместо или как дополнение к общему UML. По существу профили были способом определения языка, широко известного сейчас под названием DSL (domain specific language).
Альтернатива использования UML-профилей - определить новый традиционный язык моделирования, используя стандарт MOF и инструментальные средства. Последний подход имеет очевидные преимущества чистого листа, разрешая определение языка, который оптимально подходит для текущей проблемы. На первый взгляд это может показаться предпочтительным подходом к определению DSL, но более внимательное исследование показывает, что у этого подхода могут быть серьезные недостатки.
Как упоминалось во введении, слишком большое разнообразие ведет к такому типу проблем фрагментации, которые UML был призван устранять. Фактически, это одна из главных причин такого широкого и быстрого его распространения.
К счастью, механизм профилей обеспечивает удобное решение для многих практических случаев. Причина этого кроется в существовании множества общих свойств даже среди различных DSL. Например, практически любой объектно-ориентированный язык моделирования требует определения концепций классов, атрибутов, ассоциаций, взаимодействий и т.д. UML, являющийся языком моделирования общего назначения, обеспечивает именно эту удобную и тщательно определенную коллекцию полезных концепций. Это делает его хорошей начальной точкой для большого числа возможных DSL.
Но существует еще кое-что, кроме концептуального повторного использования. UML-профиль по определению должен быть совместим со стандартным UML. Другими словами, UML-профиль может только перечислить стандартные концепции UML, определяя ограничения этих концепций, что дает им уникальную, зависящую от области применения, интерпретацию. Например, ограничение может запретить множественное наследование, или может потребовать, чтобы класс обязательно имел конкретный тип атрибута. Это значит, что:
- Любое инструментальное средство, поддерживающее стандартный UML, может использоваться для работы с моделями, основанными на этом профиле
- Все знания и опыт использования стандартного UML применимы непосредственно
Следовательно, многие проблемы фрагментации, вызванные разнообразием, могут быть смягчены и даже полностью устранены. Рассуждения такого рода и привели к тому, что в интернациональных стандартах, отвечающих за язык SDL (DSL широко используется в телекоммуникациях), SDL был переопределен в виде UML-профиля.
Нельзя сказать, что любой DSL может и должен быть реализован как UML-профиль; существует действительно много случаев, когда UML может потерять нужные фундаментальные концепции, которые могли бы быть преобразованы в соответствующие DSL-концепции. Однако, исходя из универсальности UML, он может быть более широко применимым, чем многие могли бы подумать.
Исходя из этих рассуждений, механизм профилей UML 2.0 был усовершенствован, а его возможности расширены. Также была уточнена концептуальная связь между стереотипом и расширяющими его UML-концепциями. В сущности, стереотип UML 2.0 определяется как если бы он был просто подклассом существующего UML-метакласса с ассоциированными атрибутами (представляющими теги для теговых значений), операциями и ограничениями. Были полностью определены механизмы написания таких ограничений с использованием такого языка как OCL.
В дополнение к ограничению индивидуальных концепций моделирования профиль UML 2.0 может также явно скрывать UML-концепции, не имеющие смысла или необязательные в данном DSL. Это разрешает определение очень маленьких DSL-профилей.
Наконец, механизм профилей UML 2.0 может также использоваться как механизм просмотра сложной UML-модели с различных, зависящих от прикладной области, точек зрения, что обычно невозможно в DSL. То есть, любой профиль может быть избирательно применен и наоборот, изъят из применения без влияния каким-либо образом на используемую UML-модель. Например, инженер, ответственный за производительность, может выбрать применение интерпретации моделирования производительности в модели, присоединяя различные измерения производительности к элементам модели. Затем они могут использоваться автоматизированными средствами анализа производительности для определения фундаментальных свойств производительности дизайна программного обеспечения. В то же время (и независимо от отвечающего за производительность инженера) инженер, отвечающий за надежность, может переопределить просмотр той же самой модели с точки зрения надежности для определения общих характеристик ее надежности и так далее.
Общее объединение
Этот элемент охватывает несколько областей, включая удаление перекрывающихся концепций, а так же многочисленные редакционные модификации (такие как добавление уточнений для запутанных описаний, и стандартизация терминологии и форматов спецификации).
Удаление перекрывающихся и уточнение слабо определенных концепций являлось еще одним важным требованием для UML 2.0. Это требование влияет на три основных области применения:
- Действия и активности
- Шаблоны
- Концепции основанного на компонентах дизайна
Действия были представлены в UML 1.5. Концептуальная модель действий преднамеренно была сделана достаточно обобщенной для согласования с обеими моделями вычисления - как моделями, основанными на потоке данных, так и моделями, основанными на потоках управления. Это привело к значительному концептуальному подобию модели активностей. В UML 2.0 было использовано это подобие для обеспечения общего синтаксиса и фундамента семантики для действий и активностей. С вашей точки зрения они являются формализмами, возникающими на различных уровнях абстракции, поскольку они обычно моделируют явления на различных уровнях детализации. Однако общая концептуальная база приводит к общему упрощению и большей ясности.
В UML 1 шаблоны были определены очень обобщенно: любая UML-концепция могла быть представлена в шаблоне. К сожалению, такая общность была препятствием для приложений, поскольку разрешала потенциально не имеющие значения типы шаблонов и подстановку шаблонов. Механизм шаблонов в UML 2.0 был ограничен до хорошо понимаемых случаев: классификаторов, операций и пакетов. Первые два были смоделированы аналогично механизмам шаблонов в популярных языках программирования.
В области компонентного проектирования UML 1 имел запутанное изобилие концепций. Вы могли использовать классы, компоненты или подсистемы. Эти концепции имели много общего, но были немного различными. Не было четкого разграничения, какую использовать в данной ситуации. Была ли система просто "большим" компонентом? Если да, насколько большим мог быть компонент, перед тем как стать подсистемой? Классы обеспечивали инкапсуляцию и реализовывали интерфейсы, но это же делали компоненты и подсистемы.
В UML 2.0 все эти концепции были урегулированы, так что компоненты были просто определены как специальный случай более общей концепции структурированного класса; аналогично, подсистемы были попросту специальным случаем концепции компонента. Качественные различия между ними были четко определены, так что вы можете принять решение о том, какую из концепций использовать в зависимости от объективных критериев.
С редакторской точки зрения формат спецификации был объединен с семантикой, а спецификации системы обозначений концепций моделирования были сгруппированы для упрощения ссылок. Спецификация каждого метакласса была расширена информацией, явно идентифицирующей семантически разнообразные особенности, варианты системы обозначений и его взаимосвязь со спецификацией UML 1. Наконец, терминология была сделана непротиворечивой, то есть определенный термин (например, тип, экземпляр, спецификация или событие) имеет одинаковое общее содержание во всех контекстах, в которых появляется.
Итоги
UML2.0 был спроектирован для того, чтобы постепенно познакомить вас с управляемыми моделями методами. Те, кто предпочитает использовать его как средство графического представления (как описывалось выше в данной статье), могут и далее использовать его так же свободно, как и UML 1. Более того, поскольку новые возможности моделирования являются ненавязчивыми, в большинстве ситуаций такие пользователи не увидят каких-либо изменений во внешнем виде и поведении языка.
Однако сейчас доступна возможность перейти к MDD-технологии стандартизованным способом. UML 2.0 содержит необходимую увеличенную точность, и если пожелаете, вы можете использовать его новые возможности на пути к полностью автоматизированному генерированию кода.
Структура языка была тщательно реорганизована для предоставления модульного и дифференцированного подхода к его усвоению - вам необходимо изучить только интересующую вас часть языка и благополучно проигнорировать остальные части. По мере роста вашего опята и знаний вы можете добавлять новые возможности. Вместе с этой реорганизацией значительно упростились определения совместимости, которые будут содействовать возможности взаимодействия между работающими совместно инструментальными средствами, а также между средствами разных производителей.
Было добавлено только небольшое число новых функциональных возможностей (чтобы избежать "раздувания" языка) и практически все они спроектированы по одинаковому принципу рекурсии, что позволяет моделировать очень большие и сложные системы. В частности, были добавлены расширения для более точного моделирования архитектуры программ, для сложных системных взаимодействий и для основанных на потоках моделей, что делает язык идеальным для таких приложений, как моделирование бизнес-процессов и проектирование систем.
Механизмы расширения языка были немного реструктуризированы и упрощены, что предоставило более прямой способ определить специфичные для области применения языки (domain-specific languages - DSL) на основе UML. Эти языки имеют заметную выгоду, поскольку способны непосредственно использовать преимущества инструментальных средств UML и практического применения, которые представлены в полном объеме.
Общим результатом является язык моделирования второго поколения, который поможет вам разрабатывать более сложные программные системы быстрее и с более высокой степенью надежности, в то же время позволяя вам продолжать использовать интуицию и опыт, которые присущи каждому разработчику программного обеспечения. В сущности, это все еще проектирование программы, только на более высоком уровне, что можно сравнить с ситуацией в проектировании аппаратного обеспечения, когда дискретные компоненты отступают перед крупномодульной интеграцией.