
Цель SOA - быстрая адаптация бизнеса под меняющиеся условия, а способ достижения такой адаптации - идентификация базовых бизнес-компонентов. После идентификации компонентов можно идентифицировать и указать ассоциированные с ними бизнес-процессы и сервисы. Декомпозиция бизнес-процесса помогает обнаружить повторно используемые ИТ-сервисы, необходимые для обеспечения этих бизнес-процессов и сервисов. Необходимо также указать входные и выходные сообщения ИТ-сервисов и доменные объекты, которыми эти сервисы управляют. С точки зрения ИТ эти сервисы можно смоделировать как варианты использования, а функциональные и нефункциональные требования этих вариантов использования можно отследить (например, в Requisite Pro). Как справиться со сложностью такой среды, с таким количеством меняющихся составляющих? В частности, как построить эти сервисы, чтобы удовлетворить предъявляемые к ним нефункциональные требования?
Один из способов преодоления этих сложностей - использование шаблонов. Шаблон представляет собой воспроизводимое решение конкретной проблемы в конкретном контексте и обычно описывается спецификацией шаблона. Спецификации шаблонов содержат раздел forces, в котором указывается, когда этот шаблон должен использоваться. Осуществимость решения в конечном итоге определяется такими нефункциональными требованиями, как масштабируемость, производительность, защищенность, работа с транзакциями, удобство обслуживания и способность к взаимодействию. Отображая эти нефункциональные требования в раздел forces спецификации шаблона, мы получаем возможность отслеживания и идентификации в архитектурных решениях.
В данной серии статей рассматриваются четыре SOA-шаблона, удовлетворяющих определенные нефункциональные требования к SOA-приложению. Ниже приведен список шаблонов и краткое описание нефункциональных требований, которые удовлетворяет каждый из них
- Шаблон WS response template обеспечивает гибкость интерфейса сервиса, способность к взаимодействию и удобство обслуживания. Спецификация шаблона requestor-side caching повышает производительность сервиса.
- Шаблон preferred data source является шаблоном микропотоков для агрегации сервисов.
- Шаблон logging обеспечивает отслеживаемость вызовов сервиса.
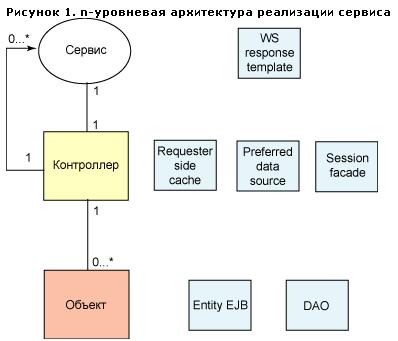
Перед подробным исследованием этих шаблонов полезно рассмотреть представленную ниже n-уровневую архитектуру. Простая трехуровневая архитектура включает уровень представления, бизнес-уровень и уровень персистентности. В SOA-среде мы можем разделить бизнес-уровень на уровень сервисов, уровень контроллера и уровень управления объектами (сущностями) (см. рисунок 1). Можно рассматривать разбиение на уровни в контексте контейнера сервера приложений.
Уровень сервиса отвечает за указание операций, используемых в сервисе, и содержимого сообщений, используемых этими операциями. Он также отвечает за сериализацию и десериализацию сообщений, передаваемых в контейнер и из него. Уровень контроллера отвечает за реализацию бизнес-логики сервиса, достигаемую путем вызовов других сервисов, других контроллеров или уровня управления объектами. Уровень управления объектами занимается управлением объектами и гарантирует целостность транзакций данного объекта внутри контейнера.
Шаблон WS response template, который мы исследовали в третьей части данной серии статей, можно применить на уровне сервиса. (На этом уровне также применяются и другие шаблоны, которые непосредственно влияют на определение сервиса, например, шаблон WS-security.) Шаблон requester-side caching применяется на уровне контроллера. Шаблон aspect logging также будет применяться на уровне контроллера. Шаблон preferred data source, который мы исследуем очень подробно в последующих статьях, может применяться на уровне контроллера. Базовые шаблоны Enterprise Java™Beans session facade, message facade и business delegate принадлежат уровню контроллера. Наконец, шаблон data management логического объекта и базовые Enterprise JavaBeans-шаблоны Data Access Object (DAO) принадлежат уровню логических объектов. На рисунке 1 представлена n-уровневая архитектура реализации сервиса и показано, где применяются перечисленные выше шаблоны.
Рисунок 1. n-уровневая архитектура реализации сервиса
Производительность, производительность, производительность…
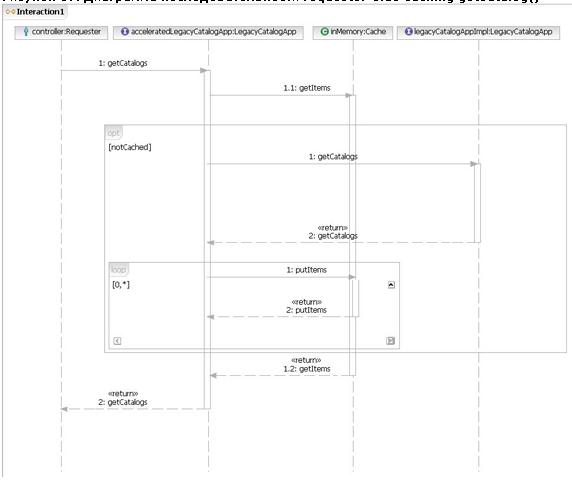
В третьей части данной серии статей мы применили шаблон WS response template к UML-модели сервиса catalog. При этом была создана новая, более гибкая модель сервиса catalog. Затем при помощи преобразований UML-to-WSDL и UML-to-XSD из этой модели были сформированы соответствующий код заглушки (stub) и скелетный код сервиса. Затем сервис catalog был реализован контроллером сервисов, который обращался к унаследованному приложению каталога за данными, необходимыми для сервиса catalog. Вся последовательность событий показана на рисунке 2.
Рисунок 2. Диаграмма последовательности WS response template getCatalog()
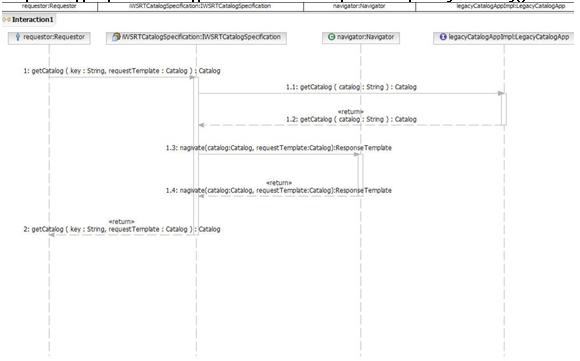
Диаграмма последовательности показывает, что при каждом вызове сервиса catalog (поиск SKU из конкретного каталога) из существующего унаследованного приложения каталога приходится извлекать весь каталог для его последующей передачи в навигатор. Поскольку существующее приложение каталога является неизменяемым, а элементы каталога в основном только читаются, здесь идеально подходит шаблон requester-side caching. Шаблон requester-side caching будет кэшировать запрашиваемые каталоги на запрашивающей стороне для будущих запросов. Перед более подробным рассмотрением шаблона requester-side caching мы немного отклонимся в сторону, чтобы разобраться в том, как этот шаблон может появиться в результате взаимодействия с реальным клиентом. В данном случае клиент является вымышленным, но сценарий создания шаблона абсолютно реален.
Разработка шаблона requester-side caching
Этот шаблон является примером разработки на месте (field-based), когда шаблон приложения (архитектуры) создается в результате взаимодействия с реальным клиентом. Имя клиента изменено, но технические детали проблемы и решения описаны точно.
Рассмотрим вымышленную организацию HIPPO, которая координирует и обрабатывает заявки на медицинское обслуживание и другие социальные сервисы. HIPPO имеет несколько бизнес-процессов для управления заявками (например, "обработать новую заявку"). Каждый из этих бизнес-процессов состоит из нескольких задач, которые необходимо выполнить для завершения конкретного бизнес-процесса. Типичный бизнес-процесс HIPPO является долгоживущим, с возможностью прекращения работы, и в среднем состоит из 10 бизнес-задач. Некоторые из этих задач можно автоматизировать, например, извлечение заявки, а некоторые требуют вмешательства человека, например, подтверждение (отклонение) заявки. HIPPO обычно обрабатывает около 3000 заявок в день. Для повышения эффективности работы HIPPO было принято решение перейти на схему с единым центром обработки заявок. HIPPO имеет функциональные требования по автоматизации этих бизнес-процессов, а также несколько нефункциональных требований, связанных с производительностью, работой с транзакциями, целостностью данных и т.д.
Для удовлетворения этих функциональных требований HIPPO смоделировала свои бизнес-процессы в WebSphere® Business Integration (WBI) Modeler. Затем в WBI Modeler были сгенерированы описания на Business Process Execution Language (BPEL) с целью размещения бизнес-процессов на сервере WebSphere Process Server и обеспечения существования нескольких экземпляров бизнес-процессов. Каждый бизнес-процесс может иметь несколько экземпляров в системе в любой момент времени. Каждый экземпляр процесса имеет несколько задач пользователя (human tasks), причем для отправки запроса WPS и отображения этих задач используется WebSphere Portal Server. После этого задача может быть обработана в центре обслуживания, где сотрудник HIPPO, зарегистрировавшийся в системе, видит, какие задачи ему назначены. Задачи можно сортировать по приоритету, дате и другим метаданным. Также в системе имеется менеджер, который может назначать новые задачи сотрудникам и просматривать состояние задач конкретного сотрудника.
Основным нефункциональным требованием HIPPO к порталу была производительность. Портал должен был выводить список задач за определенное время, например, в течение двух секунд. Однако при каждом запросе пользователем обновления системы, например, для сортировки по сроку выполнения, портал должен был выдавать новый запрос в WPS для заполнения списка задач. По мере роста количества активных экземпляров процесса производительность системы значительно снижалась.
После долгих размышлений было принято решение создать на запрашивающей стороне (портал) кэш для информации о пользовательских заданиях. При получении приложением портала заданий из WPS они локально кэшировались. При обновлении списка задач портал сначала проверял бы их наличие в кэше, а затем, если они там отсутствовали, запрашивал бы WPS. Такое решение удовлетворяло нефункциональные требования к производительности.
Шаблон requester-side caching часто может обеспечить эффективное решение проблемы производительности, но разработчик должен тщательно рассмотреть ряд факторов. К ним относятся нефункциональные требования к кэшируемым данным, например, изменяемость данных, латентность кэша и то, должен ли кэш заполняться заранее или нет. В следующем разделе рассматриваются факторы, влияющие на решение использовать шаблон requester-side caching. Давайте рассмотрим шаблон более детально.
Шаблон requester-side caching является посредником при взаимодействии между одним или несколькими клиентами и одним или несколькими провайдерами данных. Функции посредника заключаются в хранении элементов данных, формируемых провайдером, и использовании их для обслуживания запросов от клиентов. Целью является ускорение и (или) уменьшение стоимости доступа к данным. Этот очень общий шаблон имеет много вариаций, предназначенных для различных целей. Шаблон должен облегчить принятие решений по дизайну и документирование принятых решений, касающихся кэша и политик.
Рисунок 3. Диаграмма классов шаблона requester-side caching
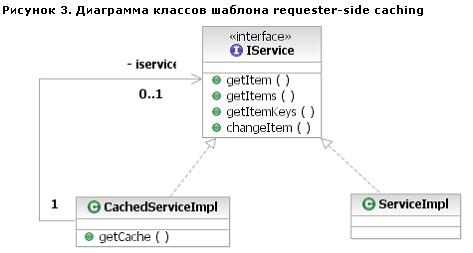
Диаграмма класса (рисунок 3) демонстрирует "декораторскую" природу нашего шаблона (decorator в терминах книги "Шаблоны проектирования" Гамма, Хелма, Джонсона и Влиссидеса). Провайдером является класс ServiceImpl, который реализует интерфейс IService. Этот интерфейс обычно имеет такие операции, как getItem() и getItems(), где item - это некоторый логический объект. Операция getItem() принимает первичный ключ для идентификации элемента, а getItemKeys() обычно принимает критерий выбора, который может преобразовываться в набор первичных ключей при помощи операции getItemKeys(). Интерфейс IService может также иметь операцию changeItem(), которая, по определению, вызывает изменения внутренней структуры элемента. Декоратором (decorator) является класс CacheServiceImpl. CacheServiceImpl реализует интерфейс IService и заключает в себе ServiceImpl, предоставляя возможности кэширования операциям getItem() и getItems().
Рисунок 4. Диаграмма последовательности шаблона requester-side caching
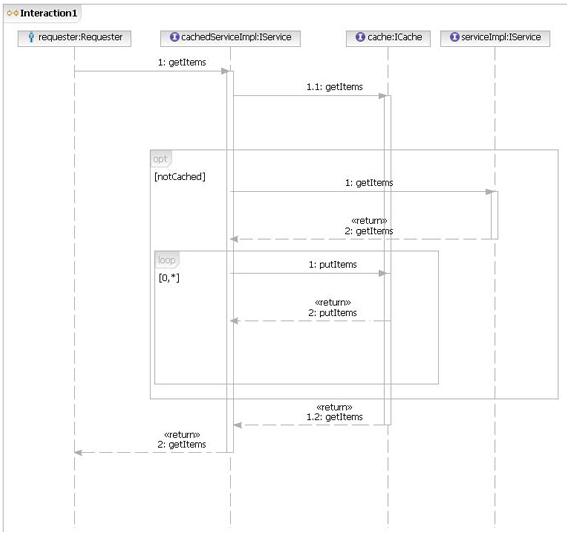
Диаграмма последовательности (рисунок 4) показывает, что запрашивающая сторона использует клиентский прокси CacheServiceImpl для вызова getItems(). Реализация getItems() сначала проверяет кэш на присутствие в нем элементов. Если их в кэше нет, getItems() получает элементы от провайдера, а затем сохраняет их в кэше для последующего использования. Метод getItems() с помощью операции getItemKeys() получает уникальный набор первичных ключей, а затем вызывает операцию getItem() с каждым из этих ключей.
Реализации шаблона requester-side caching
Теперь на базе спецификации шаблона можно создать множество реализаций шаблона requester-side caching (различие между спецификацией шаблона и реализацией шаблона объясняется на боковой врезке в третьей части. Обычно любая реализация должна обеспечивать некоторый уровень автоматизации применения шаблона. Реализации, которые мы будем рассматривать, будут использовать среду управляемой моделями разработки Rational Software Architect (дополнительная информация по моделированию с использованием основанной на аспектах реализации спецификации данного шаблона приведена на боковой врезке). Для целей данного раздела мы будем рассматривать реализацию шаблона requester-side caching, использующую механизм шаблонов RSA.
Эта реализация механизма шаблонов RSA предполагает наличие UML-модели сервиса или интерфейса, который нужно ускорить. При использовании этого шаблона в соответствии с методикой управляемой моделями разработки значения параметров шаблона сопоставляются конкретным элементам UML-модели сервиса или интерфейса. После связывания параметров шаблона автоматически создаются дополнительные UML-элементы, к частности, кэш и умеющий работать с кэшем прокси сервиса. Вызов преобразования UML-to-Java для полученной модели сгенерирует артефакты Java-реализации. Эта реализация также позволяет сделать выбор между специализированным пользовательским кэшем в оперативной памяти или динамическим кэшем WebSphere Platform. Если пользователь выбирает последний, реализация шаблона автоматически сгенерирует конфигурационные файлы, которые будут использоваться с dynacache.
ЭЭта реализация шаблона requester-side caching создается с использованием механизма шаблонов RSA. Разработка шаблона с использованием механизма шаблонов RSA приводит к созданию Eclipse-плагина, который может упаковываться как повторно используемый ресурс с помощью спецификации Reusable Asset Specification (RAS), также обратитесь к первой части данной серии статей, чтобы лучше изучить шаблоны и повторно используемые ресурсы). Результатом такой упаковки является RAS-ресурс. RAS-ресурс вместе с ассоциированными с ним метаданными может затем развертываться на RAS-сервере, например, в репозитории developerWorks RAS. В следующем разделе мы покажем, как обратиться к этому шаблону в репозитории developerWorks RAS, используя RAS-клиент. Этот RAS-актив будет импортирован в RSA, в результате чего RSA-функциональность будет расширена, и у пользователей появится возможность применять к моделям шаблон requester-side caching.
Применение шаблона requester-side caching
Реализацию шаблона requester-side caching можно импортировать в RSA при помощи нашего типового рецепта. Сначала перейдите в раздел "Apply patterns to a service implementation" в рецепте и разверните раздел под названием "Applying the requester-side caching pattern". Найдите нужный ресурс в данном разделе и выберите Import (см. рисунок 5).
Рисунок 5. Импортирование реализации шаблона requester-side caching
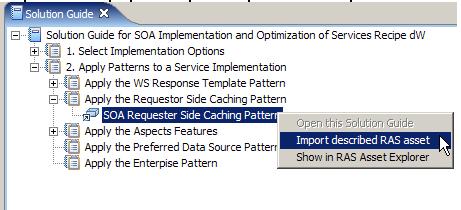
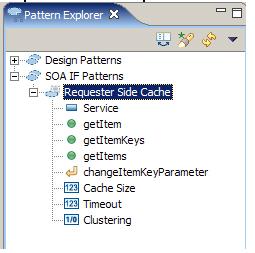
В RSA будет установлена реализация шаблона requester-side caching. После установки шаблона он появится в Pattern Explorer, как показано на рисунке 6.
Рисунок 6. Pattern Explorer с шаблоном requester-side caching
Примечание. Данная статья является продолжением третьей части. Если вы хотите начать с чистого рабочего пространства (workspace), импортируйте готовый interchange project шаблона ответа WS. Далее показано, как перемещаться по рецепту и импортировать существующую модель catalog в RSA. Затем к этой модели применяется шаблон requester-side caching, и генерируется соответствующий код, умеющий работать с кэшем, в преобразовании UML-to-Java.
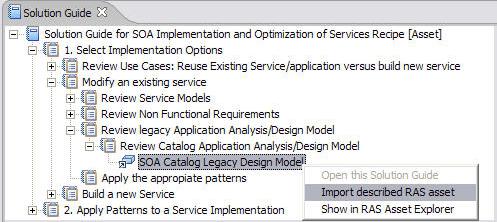
- Откройте SOA Catalog Entity Design Model. На рисунке 7 показана внутренняя структура модели SOA Legacy Catalog Application Design Model.
Рисунок 7. Импортирование модели SOA Catalog Legacy Design Model
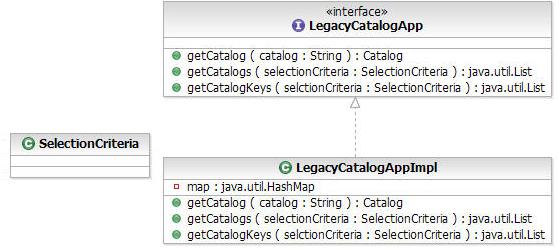
- Перейдите к пакету com.ibm.retail.catalog и откройте диаграмму классов UML. На рисунке 9 показана диаграмма классов UML для сервиса Catalog. Модель отображает интерфейс и реализацию для сервиса catalog. Имеется три операции:
getCatalog(): используется для получения всего каталога.getCatalogs(): используется для получения ряда каталогов на основе критерия выбора.getCatalogKey(): используется для преобразования критерия выбора в набор уникальных ключей.
Рисунок 8. Модель SOA Catalog Legacy Design Model
Рисунок 9. Диаграмма классов UML модели SOA Catalog Legacy Design Model
- В перспективе modeling перетащите шаблон requester-side caching в открытую диаграмму классов UML. На рисунке 10 показана модель дизайна логического объекта catalog до применения шаблона requester-side caching.
Рисунок 10. Модель SOA Catalog Legacy Design Model до применения шаблона requester-side caching
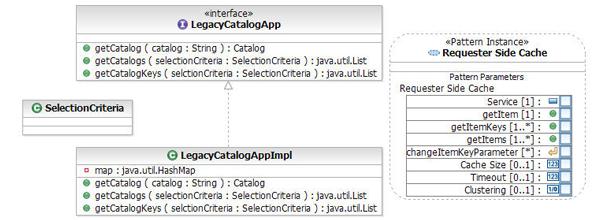
Шаблон requester-side caching принимает следующие параметры:
Service: интерфейс (класс), который содержит операцию, которую мы хотим ускорить посредством кэширования (интерфейсCatalogService).getItem: операция интерфейса (класса), использующаяся для получения одного элемента с данным ключом (операцияgetCatalog()).getItemKeys: операция интерфейса (класса), использующаяся для получения ключей для данного набора критериев (операцияgetCatalogKeys()).getItems: операция интерфейса (класса), использующаяся для получения элементов для данного набора критериев (операцияgetCatalogs()).changeItemKey: параметр в операции change item, соответствующий ключу элемента (например,setItem()).Cache size: размер кэша.Clustering: значение Boolean, где true означает кластерную структуру используемой топологии. (Мы устанавливаем false, поскольку хотим использовать кэш в оперативной памяти. Если вы хотите использовать функциональность WebSphere dynacache, установите это значение в true.)Timeout: значение (измеряемое в миллисекундах), по истечении которого элемент удаляется из кэша.
Рисунок 11. Модель SOA Catalog Legacy Design Model после применения шаблона requester-side caching
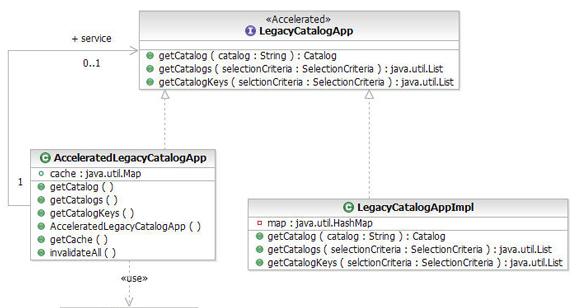
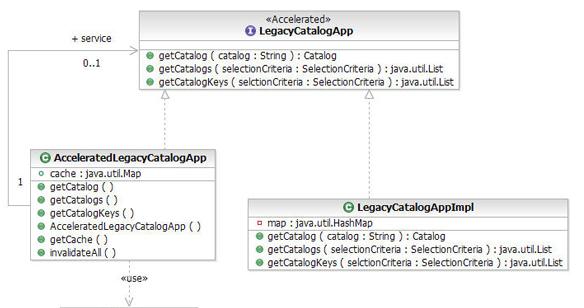
Результатом применения этого шаблона являются несколько артефактов классов UML:
- Создается класс
AcceleratedCatalogService. Данный класс реализует интерфейсCatalogServiceи инкапсулирует его реализацию. Это классический шаблон проектирования decorator по классификации книги Гамма и др.AcceleratedCatalogServiceсодержит также ссылку на классCache. - Также формируется кэш в памяти. Если атрибут clustering был установлен в значение true,
AcceleratedCatalogServiceбудет содержать ссылку на прокси WebSphere dynacache. - Классы
AcceleratedCatalogServiceиCacheпреобразуются в соответствующие Java-классы при помощи преобразования UML-to-Java (как показано на рисунке 12). Оба класса генерируются в папке RetailWeb (см. рисунок 13). Java-файлыAcceleratedCatalogServiceиCache, сформированные при преобразовании UML-to-Java, можно найти в ZIP-файле project interchange.
Рисунок 12. Преобразование UML-to-Java
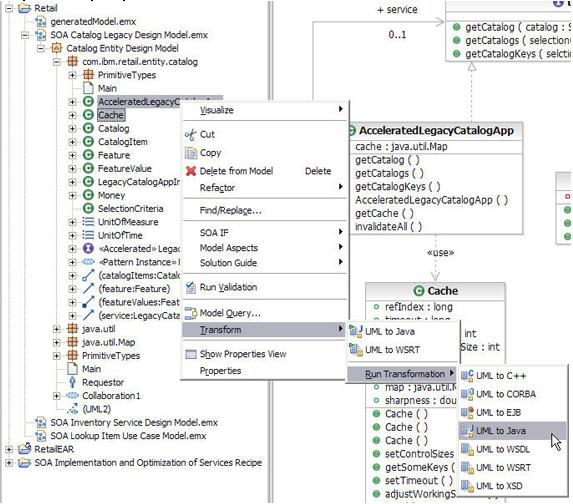
Рисунок 13. Диалоговое окно преобразования UML-to-Java
- Контроллер catalog теперь может использовать
AcceleratedCatalogServiceвместоCatalogServiceдля доступа к существующему приложению catalog. Всего лишь одна строка кода, а контроллер catalog может теперь использовать возможности кэширования каталогов, возвращаемых из существующего приложения catalog.
Листинг 1. AcceleratedCatalogService
**
public javax.xml.soap.SOAPElement getCatalog(
javax.xml.soap.SOAPElement key,
javax.xml.soap.SOAPElement requestTemplate)
throws InvokerException, WriterException {
Object catalog = null;
String keystr = ((javax.xml.soap.Node) key.getChildElements().next()).getValue();
System.out.println(keystr);
// Получить ссылку на сервис catalog
com.ibm.retail.entity.catalog.CatalogService catalogImpl =
new com.ibm.retail.entity.catalog.CatalogServiceImpl();
// Использовать сгенерированный сервис Accelerated Catalog
com.ibm.retail.entity.catalog.CatalogService cachedCatalogImpl =
new com.ibm.retail.entity.catalog.AcceleratedCatalogService(catalogImpl);
catalog = cachedCatalogImpl.getCatalog(keystr);
// Выполнить навигацию по каталогу для возврата шаблона ответа
return Navigator.navigate(requestTemplate, catalog, context);
} |
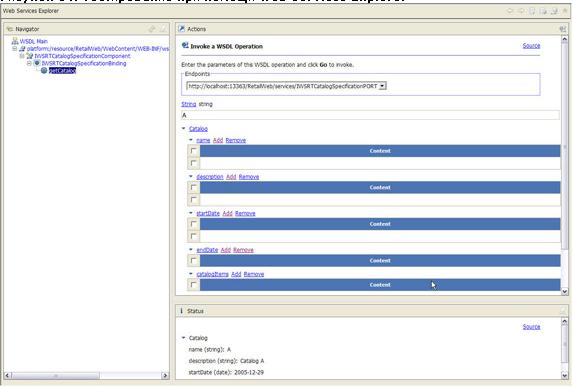
- Протестируйте реализацию при помощи Web Services Explorer. На рисунке 14 показан вызов "Catalog A", когда клиента интересует только название, описание и начальная дата каталога.
Рисунок 14. Тестирование при помощи Web Services Explorer
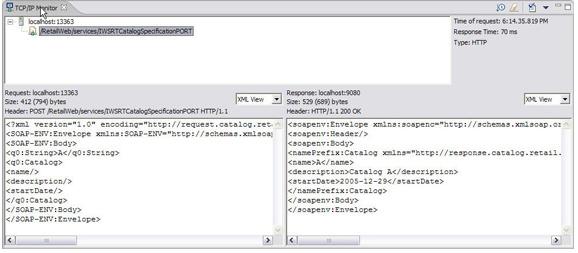
Если при генерировании WSDL-to-Java был отмечен флажок monitor Web service, в TCP/IP tunneller должен появиться SOAP-запрос вызова с пустым SOAP-ответом (см. рисунок 15). Этот запрос содержит два параметра:
- Первичный ключ каталога, в данном случае catalog "A".
- Шаблон запроса, указывающий, что должны возвращаться только название, описание и начальная дата.
Выполните этот вызов дважды и понаблюдайте за консолью output. В первый раз вы увидите следующие данные из существующего приложения catalog (см. рисунок 16):
This took a very very long time
Рисунок 16. Информация, выводимая в консоли WebSphere
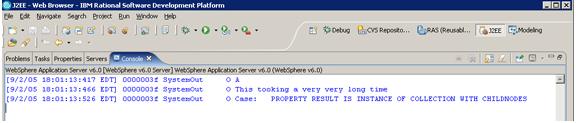
Во второй раз это сообщение исчезнет, поскольку каталог A теперь находится в кэше на запрашивающей стороне. Вы можете поменять параметры запроса, передаваемые в сервис catalog, понимающий шаблон запроса WS.
На рисунке 17 показана диаграмма последовательности действий после применения шаблона requester-side caching. Контроллер catalog сначала всегда обращается к кэшу. Только при отсутствии элементов в кэше контроллер будет запрашивать существующее приложение catalog и обновлять кэш новыми результатами. Применение кэша для существующего приложения catalog на запрашивающей стороне имеет следующие преимущества:
- Обеспечивается корректный подход к реализации кэширования на запрашивающей стороне.
- Контроллер каталога, понимающий шаблон запроса WS, может теперь создать работающий с кэшем прокси, используя одну строку кода.
Рисунок 17. Диаграмма последовательности requester-side caching getCatalog()
Фундаментальным изменением в контроллере catalog является переключение с реализации унаследованного приложения каталога на кэшированный прокси:
Листинг 2. Реализация унаследованного приложения каталога
com.ibm.retail.entity.catalog.CatalogService catalogImpl =
new com.ibm.retail.entity.catalog.CatalogServiceImpl();
catalog = catalogImpl.getCatalog(keystr);
|
на:
Листинг 3. Кэшированный прокси
com.ibm.retail.entity.catalog.CatalogService catalogImpl =
new com.ibm.retail.entity.catalog.CatalogServiceImpl();
com.ibm.retail.entity.catalog.CatalogService cachedCatalogImpl =
new com.ibm.retail.entity.catalog.AcceleratedCatalogService(catalogImpl);
catalog = cachedCatalogImpl.getCatalog(keystr);
|
Шаблон aspect logging
|
Одной из целей обсуждения данного шаблона является реализация какого-либо способа регистрации использования сервиса и кэша. Журналы регистрации можно использовать в среде времени исполнения для оценки реальных преимуществ кэширования и во время разработки в качестве дополнительного средства отладки. Поскольку регистрация событий не является непосредственно частью функциональности сервиса или кэша, ее нельзя рассматривать как часть базового дизайна шаблона. Вместо этого такую функциональность лучше всего рассматривать как ортогональную для кэша и дизайна шаблона, и в идеале она должна создаваться и применяться таким образом, чтобы быть незаметной в дизайне и реализации кэша и сервиса.
AspectJ в данном случае оказывается чрезвычайно удачным архитектурным механизмом, позволяющим распространить такую функциональность, как журналирование событий, на уже скомпилированные кэш и сервис, которые здесь разрабатываются. Организация Eclipse предоставляет большой объем документации по технологии AspectJ.
Поскольку AspectJ является новой технологией и содержит еще один язык программирования (вариант языка Java), многие отказались от этой потенциально полезной технологии, испугавшись затрат времени на изучение. Чтобы повысить привлекательность этой технологии для более широкого круга разработчиков, мы предоставили средства использования предопределенных аспектов на уровне моделирования. То есть проектировщики и индивидуальные разработчики, знающие об AspectJ, могут создавать и развертывать основанный на AspectJ код для дизайнеров и реализаторов, позволяя им встраивать и применять аспекты в виде абстракций моделирования. Все остальное происходит за кулисами.
Реализация шаблона aspect logging может быть импортирована в Rational Software Architect при помощи рецепта. Сначала перейдите в раздел "Apply patterns to a service implementation" рецепта и разверните раздел "Applying the aspect logging pattern". Найдите ресурс и выберите import (см. рисунок 18).
Рисунок 18. Импортирование реализации шаблона aspect logging
При импортировании реализация шаблона aspect logging установится в RSA.
Для работы данной функциональности в RSA Eclipse должны быть установлены средства разработки AspectJ вместе с шаблоном aspect logging. При этом подключается новая страница предпочтений (Windows>Preferences>SOA IF>AspectJ Model-Based Logging). На этой странице (см. рисунок 19) можно определить шаблоны AspectJ (код AspectJ, который генерируется и включается в скомпилированный ресурс). При нажатии кнопки Add Default Templates добавится пара простых аспектов журналирования событий, но вы можете создать любой код аспекта для ассоциирования с Java-методами.
Рисунок 19. Настройка аспектов при помощи AspectJ в RSA
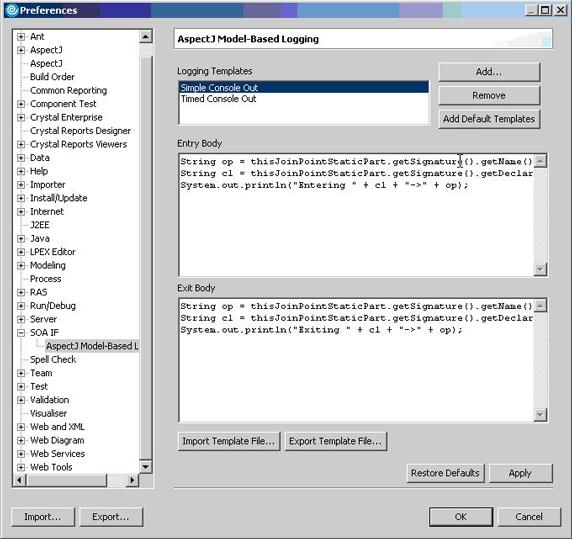
Определение аспектов таким способом позволяет изменять со временем код аспекта, совершенствуя его в последующих версиях. Точно так же можно не только менять код аспекта для сервиса журналирования событий и вызовов кэша, но и вводить код для выполнения других операций, например, вычисления статистических показателей или даже вызова определенного Web-сервиса при обнаружении аварийной ситуации. Применение этой технологии ограничивается только вашими требованиями и воображением.
Применение функциональности aspect logging
Одним из нефункциональных требований к сервису catalog является отслеживаемость каждого вызова унаследованного приложения catalog. Функциональность aspect logging является идеальной кандидатурой для реализации такой "сквозной" задачи "бесконтактным" способом. В следующем разделе показано, как можно применить шаблон aspect logging в среде управляемой моделями разработки Rational Software Architect к контроллеру catalog.
- Снова откройте модель SOA Catalog Entity Design Model. На рисунке 9 показана внутренняя структура модели дизайна существующего SOA-приложения catalog.
- Найдите класс
AcceleratedCatalogServiceи щелкните правой кнопкой мыши на операцииgetCatalog(). На рисунке 20 показано, как аннотировать операциюgetCatalog()при помощи ключевого слова<<Log>>.
Рисунок 20. Применение функциональности aspect logging к операции Accelerated getCatalog()
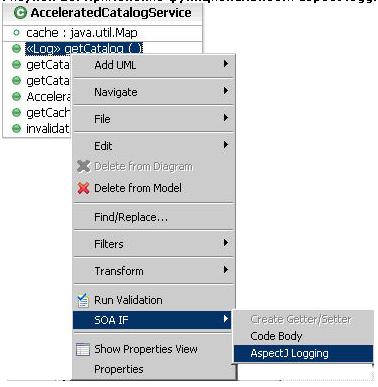
Рисунок 21. Выбор специализированного аспекта
- Выберите класс
AcceleratedCatalogServiceи повторите преобразование UML-to-Java. На этот раз будет создан дополнительный aj-файлAcceleratedCatalogServiceLogger. Сгенерированный aj-файл приведен в следующем листинге:
Листинг 4. Сгенерированный aj-файл
package com.ibm.retail.entity.catalog;
public aspect AcceleratedCatalogServiceLogger {
pointcut SimpleConsoleOut (AcceleratedCatalogService cls) : target(cls) && (
call( * getCatalog(String) )
);
before(AcceleratedCatalogService cls) : SimpleConsoleOut (cls) {
String op = thisJoinPointStaticPart.getSignature().getName();
String cl = thisJoinPointStaticPart.getSignature().getDeclaringType().getName();
System.out.println("Entering " + cl + "->" + op);
}
after(AcceleratedCatalogService cls) : SimpleConsoleOut (cls) {
String op = thisJoinPointStaticPart.getSignature().getName();
String cl = thisJoinPointStaticPart.getSignature().getDeclaringType().getName();
System.out.println("Exiting " + cl + "->" + op);
}
}
|
Теперь при каждом входе и выходе из операции AcceleratedCatalogService.getCatalog() в AspectJ-проекте в консоли будет генерироваться простое сообщение.
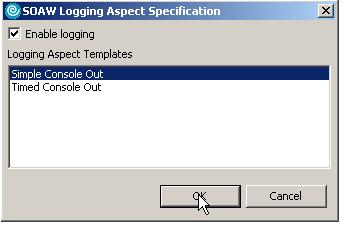
- Протестируйте реализацию в Web Service Explorer. На рисунке 22 показан вызов "Catalog A", когда клиента интересует только название, описание и начальная дата каталога.
Рисунок 22. Тестирование в Web Service Explorer
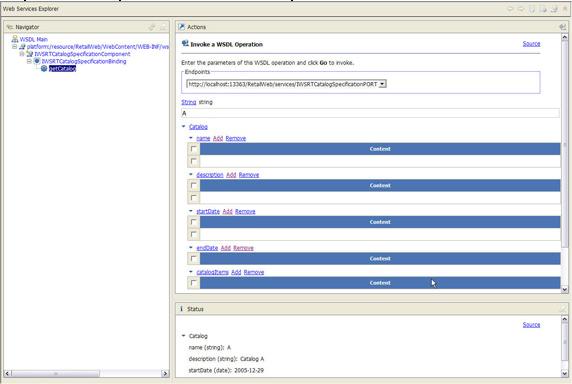
Если во время генерирования WSDL-to-Java был отмечен флажок monitor Web Service, в TCP/IP tunneller должен появиться SOAP-запрос вызова с пустым SOAP-ответом (см. рисунок 23). В этом запросе имеется два параметра.
- Первичным ключом для catalog является каталог "A".
- Шаблон запроса будет указывать, что должно возвращаться только название, описание и начальная дата.
На рисунке 24 показана регистрация сообщений в консоли.
Рисунок 24. Консоль WebSphere output

В результате использования функциональности aspect logging мы получили следующие преимущества:
- Мы применили MDD-подход к работе с аспектами.
- Проектировщик (разработчик) больше не обременен изучением семантики аспектов. Вместо этого к операциям модели теперь можно применить "сквозные" задачи, такие как регистрация событий.
- Для конкретного проекта теперь можно идентифицировать и разработать аспекты в отделе проектирования, а потом распространить получаемую библиотеку аспектов среди групп разработчиков для импортирования в RSA.
- Функциональность logging aspect для операции
AcceleratedCatalogService.getCatalog()можно создать при помощи всего лишь нескольких щелчков кнопкой мыши.
Примечания по совместимости шаблонов
Важным уроком из рассмотренных примеров применения трех шаблонов (WS response template, requester-side cache и aspect logging) является то, что их можно применить к дизайну и реализации одного и того же сервиса (приложения) без негативного влияния друг на друга. Проблема совместимости шаблонов является чрезвычайно важной для тех, кто планирует извлекать из текущих проектов и разрабатывать полнофункциональные библиотеки шаблонов, основываясь на успешных работающих проектах и реализациях.
Три рассмотренных шаблона были тщательно разработаны таким образом, чтобы гарантировать решение каждым из них своей собственной специфической задачи безотносительно к другим аспектам дизайна. Например, шаблон WS response template не предназначен для кэширования или регистрации событий и не пытается реализовать их. Шаблон caching не требует реализации в кэшируемом им сервисе дополнительных интерфейсов, например, интерфейса map.
Задачи и функциональность хорошей реализации шаблона в дизайне (реализации) приложения строго ограничены семантикой шаблона и ничем более. Ограничивая влияние шаблона только теми аспектами, для которых он предназначен, мы увеличиваем вероятность того, что этот шаблон будет совместим с другими существующими и будущими шаблонами.
Сервис catalog, рассмотренный в данной статье, демонстрирует, как подход сверху-вниз к идентификации SOA-сервиса позволяет выявить готовые к повторному использованию ИТ-сервисы, предоставляемые обычно унаследованными приложениями. Однако в рамках SOA-архитектуры к готовым к повторному использованию ИТ-сервисам часто предъявляются радикально другие, значительно более жесткие нефункциональные требования (способность к взаимодействию, производительность, работа с транзакциями, отслеживаемость), чем к унаследованным приложениям.
В данной статье рассматриваются нефункциональные требования к производительности и отслеживаемости сервиса catalog. Для оптимизации реализации сервиса catalog в среде управляемой моделями разработки к контроллеру сервиса catalog был применен шаблон requester-side caching. Этот шаблон был заимствован из другого SOA-контекста и повторно использован в других SOA-приложениях. Шаблон aspect logging тоже был применен к контроллеру сервиса каталога для обеспечения отслеживаемости вызовов сервиса каталога, не влияющей на дизайн и реализацию остальных компонентов.
В данной статье было продемонстрировано, как можно использовать шаблоны для удовлетворения нефункциональных требований с целью оптимизации повторно используемых реализаций сервисов. При внимательном согласовании этих нефункциональных требований с разделами context, problem и forces шаблона можно уменьшить сложность и обеспечить архитектурную отслеживаемость и контролируемость при разработке корпоративной архитектуры.