
Стандартом SQL предусматривается возможность, вкладывать запросы друг в друга, что имеет большое практическое применение. Еще раз - одни запросы могут управлять другими. Чтобы разобрать все тонкости данного понятия, предлагаю, вначале, рассмотреть практический пример использования подзапроса, а затем перейти к его теоретическому обсуждению.
К примеру, нас интересуют книги издательства BHV. Для это, как вариант одного из решений, мы можем использовать подзапрос.
SELECT *
FROM Books
Where Books.ID_PRESS=
(SELECT ID
FROM Press
WHERE Name='BHV');
Чтобы выполнить основной (он же внешний) запрос, SQL прежде всего должен выполнить подзапрос (он же внутренний запрос) в предложении WHERE. Таким образом, вначале выполняется подзапрос, как если бы он был единтсвенным запросом. Другими словами, просматриваются все записи таблицы Press и выбираются все записи, для которых значение поля Name='BHV'. Полученный результат подставляется в основной запрос и выполняется основной запрос. В конечном результате, оказывается выбранными записи, содержащие информацию только об издательстве BHV.
Теперь поговорим об ограничениях, которое накладывает использование подзапросов... Подзапрос должен выбирать одно и только одно поле. Более того, тип данных этого поля должен соответсвовать типу значения, используемому в основном запросе. К примеру, запрос представленный ниже, должен привести к ошибке, так как в нем на выходе подзапрос дает несколько значений:
SELECT *
FROM Books
Where Books.ID_PRESS=
(SELECT ID
FROM Press
WHERE Name='BHV' OR Name='Бином');
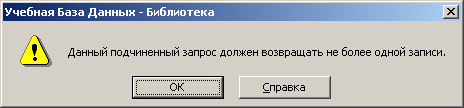
Почему ошибка? Выходные данные содержат более одной строки (возвращается ID для издательства BHV и Бином ). Таким образом, используя подзапросы, основанные на операторах отношения, необходимо быть уверенным, что конечными выходными данными подзапроса является только одна строка.
Отлично, с перебором (то есть когда на выходе из подзапроса оказывается несколько значений) разабрались. А что если подзапрос вообще не вернет никаких данных, так называемый NULL-выход? Это приведет к тому, что подзапрос будет оценен не как TRUE или FALSE, а как имеющий значение UNKNOWN. Результат UNKNOWN аналогичен результату FALSE - основной запрос не выберет ни одной строки, т.е. тоже приведет к NULL-выходу. Например, среди издательств представленных в нашей БД издательство Agatone отсутсвует, таким образом рассмотренный выше вариант с NULL-выходом сработает и в данном случае.
SELECT *
FROM Books
WHERE Books.ID_PRESS=
(SELECT ID
FROM Press
WHERE Name='Agatone');
Естественно, возникает вопрос: " а сработает ли следующий подзапрос?"
SELECT *
FROM Books
WHERE Books.ID_PRESS=
(SELECT ID
FROM Press
WHERE Name='Agatone' or Name='BHV');
Да сработает, так как подзапрос на выходе вернет одну строку.
В некоторых случаях, возможно использовать DISTINCT для гарантии получения единственного значения на выходе подзапроса. То есть, если Вы не уверены в том, что подзапрос вернет только одну строку, Вы можете подстраховаться, используя DISTINCT с подзапросами.
Следующее ограничение использования подзапросов, это некоммутативность или, более доступными словами, неперемещаемость. В соответсвии с соглашениями ANSI это обозначает, что рассмотренный ранее запрос
SELECT *
FROM Books
Where Books.ID_PRESS=
(SELECT ID
FROM Press
WHERE Name='BHV');
нельзя перписать в виде
SELECT *
FROM Books
Where
(SELECT ID
FROM Press
WHERE Name='BHV') = Books.ID_PRESS;
Однако наш "визуальнейший их все СУБД" играет по своим правилам. На приведенный последний запрос, Access сгенерирует точно таки же выходные данные как и на предпоследний (правильный) запрос.
Немного о взаимосваязи агрегатных функциий с подзапросами. Учитывая тот факт, что агрегатные функции на выходе ывдают единственно значение для любого колличесвта строк, то, логчно сделать вывод, что любой подзапрос, использующий единственную агрегатную функцию без предложения GROUP BY, дает в результате единственное значение для использования его в основном запросе.
Вспомним прошлое занятие... А именно, оператор IN. Почему вспомним именно о нем? Дело в том, что благодаря оператору IN возможно сформулировать подзапросы, в результате выполнения которых получается любое колличесво строк. Сразу оговорюсь, что операторы BETWEEN, LIKE, IS NULL к подзапросам применять нельзя. Пример, выбрать имена и фамилии всех студентов, которые брали книги в промежутке между 1 Января 2001 года и текущей датой:
SELECT FirstName & " " & LastName AS [Имя и Фамилия] FROM Students WHERE first.Id In ( SELECT ID_STUDENT FROM S_Cards WHERE DateIn >#1-1-2001# AND DateIn<DATE() );
Рассмотрим реализацию следующего запроса: "найти всех студентов, кто на данный момент работает с книгой "Реестр Windows 2000" автора Ольга Кокорева".
SELECT *
FROM Students
WHERE Students.Id IN
(SELECT ID_Student
FROM S_Cards
WHERE ID_BOOK=
(SELECT ID
FROM Books
WHERE Name='Реестр Windows 2000' AND ID_Author=
(SELECT ID
FROM Authors
WHERE FirstNAme='Ольга' AND LastName='Кокорева'
)));
Еще один пример, узнаем информации об авторах, средний объем книг которых (в страницах) более 600 страниц.
SELECT *
FROM Authors
WHERE ID IN (
SELECT IDA
FROM (
SELECT ID_Author AS IDA, AVG(Pages)
FROM Books
GROUP BY ID_Author
HAVING AVG(Pages)>600)
);
Анализ данного запроса, естественно, начинается из внутреннего подзапроса. Вначале, выбираются все записи удовлетворяющие самому внутреннему подзапросу, выбираются записи сгруппированные по идентификатору автора. Из полученного множества строк, выбрасываются все строки не удовлетворяющиее условию AVG(Pages)>600. Полученный результат, подставляется в предложение FROM, первого подзапроса, откуда выбираются значения поля ID_Author (в нашем случае используется синоним IDA для столбца ID_Author). В результате выполнения данного подзапроса на выходе получаем опять-таки несколько значений. Но благодаря оператору IN, наш подзапрос выполняется корректно, так как, еще раз напомню, оператор IN позволяет работать со множеством значений.
Таким образом, как мы убедились на практике, подзапросы могут быть использованы нетолько в предложении WHERE, но и в предложении FROM. По аналогии с предложением WHERE подзапрос может быть использован в предложении HAVING.
Отдельная разновидность подзапросов выделяется в группу связанных подзапросов. Выясним, что это такое. Когда в SQL используются подзапросы, во внутреннем (вложенном) запросе можно ссылаться на таблицу, имя которой указано в предложениее FROM внешнего запроса. Именно таким образом формируется связанный подзапрос. В этом варианте использования подзапросов, подзапрос выполняется повторно, точнее по одному разу для каждой строки таблицы из основного запроса. Например, узнаем всю информацию об издательствах, у которых общее колличество страниц выпущенных ними книг больше 700:
SELECT * FROM Press first WHERE 700<( SELECT SUM (Pages) FROM Books second WHERE first.ID=second.ID_Press ) ORDER BY 2;
К всеобщему счастью тема поздапросов объемная. По этой причине мы еще не раз затроним тему подзапрсов в последующих занятиях.