
Подмножества совместимых/несовместимых.
Наличие хотя бы одной пары несовместимых тест-значений в ВКТЗ является признаком отнесения его к категории несовместимых. Таким образом, все входное множество ВКТЗ разделяется на два класса: подмножество совместимых и подмножество несовместимых.
Связные подмножества.
Некоторые подмножества входов могут иметь более высокий приоритет в пользовательской подзадаче (например, быть теснее связанными или оказывать большее влияние на результат). В этом случае выделить тестовые подмножества можно, введя ограничиваемое комбинирование. Для его реализации достаточно при комбинировании «заморозить» не приоритетные входы, выбрав одно допустимое значение для каждого.
Метод замораживание можно использовать для «разложения» полного множества ВКТЗ по значениям выбранного входа. Пусть i-й вход описывается mi тест-значениями. Будем последовательно замораживать тест-значения этого входа. Тогда объединение получающихся при таком ограничиваемом комбинировании mi подмножеств даст полное множество комбинаций.
При «замораживании» всех входов комбинационное подмножество сводится к одному ВТКЗ.
Подмножества субинтервалов.
Если хотя бы у одного входа арифметического типа область определения содержит субинтервалы, то возможно выделение подмножеств, каждое из которых содержит ВКТЗ, содержащие тест-значения, принадлежащие выбранному субинтервалу.
Методы c -арных частичных комбинаций
МРС-выборка - простейший алгоритм
При увеличении числа входов размер полного множества ВКТЗ экспоненциально возрастает и его использование становится нереализуемым практически. Так для комплекта, включающего 13 входов с 3 опорными тест-значениями каждый размер полного множества составляет 313 ВКТЗ. Компромиссный выход из положения - использование специальных случайных выборок.
Равномерная случайная выборка полного множества комбинаций тест-значений не является оптимальным тестовым подмножеством. Рассмотрим, например, следующий фрагмент таблицы ВКТЗ (таблица 4):
Таблица 4. Пример списка КТЗ.
|
Input 1 |
Input 2 |
Input 3 |
Input 4 |
Input 5 |
|
Value 3 |
Value 2 |
Value 4 |
Value 7 |
Value 1 |
|
Value 3 |
Value 2 |
Value 4 |
Value 7 |
Value 2 |
|
Value 3 |
Value 2 |
Value 4 |
Value 7 |
Value 3 |
Перечисленные в примере ВКТЗ отличаются только в одном входе. Можно ожидать, что при равномерной случайной выборке в полученном подмножестве не избежать появления «избыточности» в этом смысле. Однако, интуитивно ясно, то эффективность выборки должна возрастать, если в содержащихся в ней векторах будет участвовать как можно больше различающихся тест-значений.
Простейший способ «концентрации» различающихся тест-значений - использование выборки «максимально различимых» ВКТЗ. На каждом шаге формирования подмножества каждый вектор случайной вспомогательной выборки (Wi) сравнивается с уже отобранными ВКТЗ (ViJ) и выбирается для включение в подмножество максимально отличающийся кандидат. В качестве меры отличия используется число несовпадающих по каждому i-му входу значений (D = ∑J∑i ~d (Wi - ViJ) ® max, d - функция Кронекера, ~d = 1 - d).
Этот простейший алгоритм можно пояснить в статистических аналогиях как формирование выборки с максимальной дисперсией.
Максимально c-частично различающаяся случайная выборка
Введем для ВКТЗ более глубокое различие, чем просто неравенство значений в одноименных входах. Рассмотрим с этой целью парные комбинации входов гнезда (см. нижеприведенный пример сочетаний пар для 5 входов в таблице 5). Обозначим парную комбинацию I-го и J-го входов через cIJ, а множество всех возможных парных комбинаций для N входов через C2(N). Мощность этого множества l2 = / C2(N)/
Таблица 5. Парные комбинации входов для 5-входового гнезда.
|
Входы пар |
Input 1 |
Input 2 |
Input 3 |
Input 4 |
Input 5 |
Число пар |
|
Input 1 |
- |
X |
X |
X |
X |
4 |
|
Input 2 |
- |
- |
X |
X |
X |
3 |
|
Input 3 |
- |
- |
- |
X |
X |
2 |
|
Input 4 |
- |
- |
- |
- |
X |
1 |
|
Input 5 |
- |
- |
- |
- |
- |
0 |
|
Итого |
10 | |||||
Каждый вход представляется некоторым числом опорных тест-значений (а гнездо - комплектом опорных тест-значений, {TI}, где TI - множество тест-значений I-го входа). Наряду с комбинациями входов введем в рассмотрение и комбинации тест-значений входов. Для получения полного множество парных комбинаций тест-значений для каждой возможной комбинации входов из C2(N) образуем множество пар тест-значений соответственно из TI и TJ. Например, если I-й вход представлен mI значениями, а J-й - mJ значениями, то для IJ-й комбинации входов, cIJ, всего возможны mI * mJ парных комбинаций значений.
Для каждого N-входового ВКТЗ возможно I2 парных комбинаций входов (в каждом входе - одно значение). Число различных парных комбинаций значений для двух ВКТЗ в общем случае не равно 2* I2, т. к. они могут иметь одинаковые пары.
Условимся в списке полного множества парных комбинаций использовать всегда один и тот же постоянный порядок следования единичных пар комбинаций тест-значений. Для описания покрытия произвольного подмножества ВКТЗ введем маску покрытия множества парных комбинаций - булев массив, каждый элемент которого соответствует члену полного списка парных комбинаций, причем его значение равно true , если соответствующая парная комбинация значений присутствует в подмножестве и false - в противоположном случае.
Обобщение метрики дальности предыдущего алгоритма использует в качестве меры отличия вектора-кандидата от накопленного подмножества - различие масок для соответствующих покрытий между маской вектором V и подмножеством векторов S:
DVS = ∑s ∑p ~d(V, Ws)p ® max,
где
- V - маска пробного вектора;
- Ws - маска вектора подмножества S;
- p - индекс cуммирования по всем элементам масок;
- s - индекс cуммирования по всем векторам подмножества S .
Случай парных частичных комбинаций естественно обобщается на c -арные частичные комбинации входов/значений - с -частичные или, просто, с -комбинационные случайные подмножества.вход
В алгоритме максимально различающейся по c-комбинациям случайной выборки (c-МРС-выборки) в качестве критерия отбора кандидата использована метрика «дальности» вектора КТЗ от подмножества, DVS,.
Продолжая статистическую аналогию, алгоритм c -МРС-выборки можно интерпретировать как переход к главным компонентам (т. н. преобразование Хотеллинга в статистике), при котором происходит концентрация дисперсии во вложенных подпространствах наименьшей размерности.
c -Покрытие множества ВКТЗ - доля c -комбинаций тест-значений подмножества ВКТЗ в полном множестве c -комбинаций тест-значений гнезда. При накоплении максимально c -различающихся ВКТЗ важным порогом является достижений 100%-го с -частичного покрытия.
100%-покрывающая c-МРС-выборка обладает замечательными свойствами. При весьма небольшом размере она гарантирует совместное присутствие в тест-наборе всех, по-крайней мере, с -арных комбинаций тест-значений полного комплекта.
Процедура формирования с -МРС-подмножества осуществляется путем генерации на каждом шаге отбора новой вспомогательной случайной выборки фиксированного размера и поиска в ней вектора, максимально отличимого от уже накопленного подмножества. Процесс завершается, когда с -покрытие полного множества накопленным подмножеством достигает 100%. ВКТЗ вспомогательной выборки формируются путем случайного выбора тест-значений входов из полного комплекта опорных тест-значений гнезда (общее с -МРС-покрытие).
Для минимизации размера с -МРС-подмножества процедуру повторяют с увеличивающимся размером вспомогательной выборки до тех пор, пока не наступит насыщение. В таблице 11 приведен соответствующий пример для комплекта, включающего 13 входов с 3 опорными тест-значениями каждый. Размер полного множества ВКТЗ составляет 1594323. Параметр комбинирования с = 2.
Таблица 6. Экспериментальный пример зависимости размера полнопокрывающего с-МРС-подмножества от размера вспомогательной выборки.
|
Размер вспомогательной выборки |
10 |
50 |
100 |
200 |
300 |
700 |
1000 |
|
Размер 100% c -МРС-подмножества |
27 |
25 |
24 |
22 |
21 |
21 |
21 |
Размер достигнутой минимальной 100% парнопокрывающей выборки составляет 21.
с-МРС-выборка может формироваться из некоторого подмножества ВКТЗ, полученного, например, путем фильтрации полного множества (случаи специального с-МРС-покрытия). В этом случае максимально достижимое с-МРС-покрытие может не достигать 100%.
Минимальное (или близкое к минимальному) количество векторов, обеспечивающих полное с-покрытие (21 из 1,6*106 в предыдущем примере) можно выбрать огромным множеством способов. Равноценна ли потенциальная тест-эффективность получающихся всевозможных минимальных с -МРС-покрытий? Ответ будет отрицательным. Тест-эффективность соответствующих подмножеств определяется не только полным охватом всех позможных с -арных субкомбинаций, но и индивидуальной эффективностью самих векторов членов с -покрывающей выборки, зависящей от их конкретного состава.
Отсюда возможные методы получения эффективных специальных с -МРС-покрытий.
1. Найти неполное с -МРС-покрытие заданного специального подмножества тест-векторов. Дополнить его до полного общепокрывающим способом (беря кандидаты из полного множества).
2. Найти неполное с -МРС-покрытие заданного специального подмножества тест-векторов. Расширить покрытие за счет использования другого специального подмножества.
3. Если в предыдущем случае полного покрытия не достигается, то расширить его общепокрывающим способом.
Если каждый вход описывается конечным множеством (относительного небольшого рзмера), то использование комбинирования (вместе с учетом несовместимых) позволяет охватить полное входное пространство гнезда. Для арифметических типов комбинационный подход менее адекватен. Однако в этом случае появляется некоторая структура опорных точек в виде границ, областей эквивалентности и особых точек (см. Граничные категории).
Для арифметических типов может быть важно и распределение пробных точек во входном пространстве, не сводящееся к комбинированию опорных тест-значений. Для получения подмножеств таких покрывающих ВТЗ (ВПТЗ) можно использовать методы случайного покрытия полного входного пространства по подходящим законам многомерного распределения пробных точек (генераторы покрытия). Все ВПТЗ принадлежат к одной граничной категории IC (типа ВНУТРИ).
В этом случае можно по аналогии со структурой опорных точек можно говорить о структуре покрытия полного тест-пространства гнезда пробными точками.
В генераторе InputSpace TestGenerator использованы следующие типы генераторов покрытия.
Равномерное случайное покрытие. В этом случае априорная информация о распределении рисков во входном пространстве отсутствует. Структура покрытия - равномерное случайное распределение пробных точек.
Равномерное покрытие субинтервалов. Структура покрытия - равномерное случайное распределение пробных точек, координаты которых по одному или нескольким входам ограничены одним из субинтервалов. Если субинтервалы заданы по всем входам, получаем равномерное случайное покрытие гиперпараллепипеда субинтервалов.
Зонд. Априорная информация о «сгущении» рисков в некоторой небольшой по размерам зоне входного пространства. Некоторый ограниченный кластер пробных точек заданного положения и размера (в пределе одна задаваемая точка входного пространства).
Профильное распределение. Структура покрытия задается распределением рангов приоритетов по входам и диапазонам входных переменных (см. Профили использования). Задавая соответствующее ранжирование, можно поучить покрытие по любому требуемому закону распределения.
Равномерное случайное покрытие, в котором в качестве координат наряду со случайными значениями использует выбранные опорные тест-значения комплекта гнезда. В этом случае по отношению к тест-значениям можно говорить о «рандомизации» (комбинационное распределение размывается случайными значениями).
Приоритизация тест-наборов
Назначение генератора тестов генерировать потенциально наиболее эффективные тест-примеры, т. е. тесты с наибольшей вероятностью обнаружения ошибок функционирования программного объекта. Эта задача может быть формально представлена как
1) упорядочение всех «точек» полного входного пространства приложения или соответствующих тест-примеров в порядке убывания тест-эффективности;
2) собственно генерация списка требуемого (или допустимого а соответствие с имеющимися ресурсами) числа первых тест-примеров, соответствующих этому упорядоченному множеству.
Для количественной характеристики тест-эффективности в InputSpace TestGenerator вводится ряд характеристик и, в первую очередь, ранг приоритета .
Приоритетные характеристики в InputSpace TestGenerator можно разбить на следующие типы.
1. Ранги приоритета, присваимые отдельным (структурированным) множествам тест-примеров:
- Ранги приоритета отдельных функций приложения.
- Ранги приоритета программных гнезд, гнезд/состояний, дубликатов гнезд.
- Ранги приоритета субнаборов тест-примеров.
2. Рейтинги векторов тест-значений.
- Профиль использования.
- Рейтинг граничных категорий.
Наинизший уровень задания ранга приоритета - субнабор. Он задается при генерации треков и присваивается всему субнабору тест-примеров. Дифференцировать субнаборы по рангу можно, увеличивая число субнаборов.
Тест-проект организован как совокупность тест-наборов для отдельных гнезд/состояний приложения. Программный цикл InputSpace TestGenerator - последовательность шагов формирования тест-набора для текущего гнезда (рисунок 5).

Рисунок 5: программный цикл InputSpace TestGenerator на уровне разделов.
Рабочий цикл может быть прерван и возобновлен на том шаге, на котором был прерван, после нового запуска программы (переход с главной страницы).
Представление о композиции формы дает рисунок 6. Центральное место формы занимает таблица пробных подмножеств ВТЗ - объект и результат методов и процедур.
Слева от таблицы - полоса унифицированных управляющих блоков, объединяющих кнопки выполнения, относящиеся к одной процедуре (инициализация, вызов диалоговой панели, выполнение, откат). Обозначение кнопок стандартизировано. Отличия более сложных блоков от типичного интуитивно понятны. Аналогичный стиль интерфейса использован и в диалогах.
На каждой странице в верхней части приведена предупреждающая справка NB (сокр. от латинского nota bene; нотабене, обрати особое внимание). В нижней части страниц расположена полоса блоков управления накоплением результатов формирования тест-наборов.
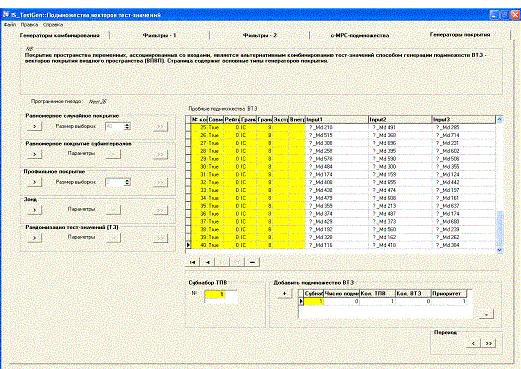
Рисунок 6: скриншот формы Подмножество векторов тест-значений .
Форма 1 - раздел Тест-проект - главная форма IS_TestGen - исходная позиция очередного рабочего цикла. В таблице Тест-плана открывается каждое новое программное гнездо (а также состояние или вариант одноименного гнезда). Открытие нового гнезда может быть произведено только после завершения формирование тест-набора для предыдущего.
Форма 2 - раздел Описание гнезд содержит средства ввода входных данных для формирования тест-наборов:
- страница Входы/Комплект тест-значений (входы гнезда, опорные тест-значения, эквидистантные Md_ , ε-окрестности);
- страница Ранжирование (ранжирование входов и диапазонов входных значений);
- страница Несовместимые пары (задание списка пар несовместимых значений).
Форма 3 - раздел Последовательности содержит средства формирования субнаборов ВТПВ (генерация типов, случайная выборка, ручной ввод). Каждый субнабор может включать одно или несколько подмножеств ТПВ. Субнабор ТПВ - это множество последовательностей, для каждой из которых разработчик планирует один и тот же субнабор векторов тест-значений (ВТЗ). Формирование субнабора включает генерацию или/и ввод пробных подмножеств ТПВ и накопление их в субнаборах.
Форма 4 - раздел Векторы тест-значений объединяет различные процедуры и методы формирования подмножеств ВТЗ, сгруппированные по страницам:
- страница Генераторы комбинирования (полное множество, ограничиваемое комбинирование, фильтр-подмножества);
- страница Фильтры - 1 (граничные категории, профили, совместимость, субинтервалы);
- страница Фильтры - 2 (экстремальность, число внеграничных);
- страница с-МРС-подмножества (общее с-МРС-подмножество, последовательное с-МРС-покрытие, дополнение до полного);
- страница Генераторы покрытия (равномерное случайное покрытие, субинтервалы, профильное покрытие, зонд, рандомизация тест-значений).
Субнаборы ВТЗ формируются способом, аналогичным формированию субнаборам ВТПВ.
Форма 5 - раздел Тест-набор гнезда - завершающая. Здесь формируются итоговые субнаборы элементарных тестовых примеров гнезда, которые могут быть архивированы в базу данных тест-проекта (итоговые тест-наборы, тест-категория, сортировка).
Технология использования InputSpace TestGenerator
InputSpace TestGenerator представляет собой инструмент, позволяющий формировать тест-наборы с помощью набора функций генерации и фильтрации подмножеств ВТПВ и ВТЗ. Подготовка входных данных и выбор плана формирования тест-набора являются прерогативой пользователя-разработчика тест-проекта. Здесь можно дать только общие указания.
Соотношение подмножеств ВТПВ и ВТЗ в тестовых субнаборах.
Поскольку размер субнабора равен произведению подмножеств ВТПВ и ВТЗ, то равноправное их использование может привести к чрезмерному росту объема тест-наборов. В свете этого целесообразно указать на предельные варианты.
1. Риски для подмножества ТПВ малы (по-видимому, чаще всего встречающийся вариант). Крайний вариант - исключение тестирования последовательностей ввода. В этом случае используется условное подмножество ТПВ из одного вектора «произвольной последовательности». На размеры подмножества ВТЗ не делается каких-либо специальных ограничений.
2. Противоположный случай. Размеры подмножества ВТПВ выбираются произвольно большого размера (вплоть до использования полного множества). Подмножество ВТЗ представляется одним или небольшим числом «типичных» векторов.
Основные способы покрытия входного пространства.
1. Метод эквивалентных классов. Использует выделение граничных категорий и при отсутствии субинтервалов требует только 3 тест-значения на каждый вход ( Mn_ , _ Md и Mx_ ). Для типичных значений числа входов в гнезде допускает получение полного множества ВКТЗ. Критичные категории BN > BA > BF . Допускается детализация по параметру Экстремальность .
2. Метод граничного анализа. Использует выделение граничных категорий с заданием комплекта 4 опорных тест-значений на каждый вход ( Mn_ , Mn-, Mx_, Mx +). Допускается детализация по параметрам Экстремальность и Число внеграничных орестностей .
3. Метод профилей использования. Требует оценочную информацию о приоритетах, но позволяет гибко регулировать размер тестового подмножеств. Однако высокоприоритетные зоны могут не покрывать граничные области и метод профилей необходимо дополнять методами эквивалентных классов и граничного анализа.
4. Ограничиваемое комбинирование. Применимо, когда имеется информация о тесной связи отдельных групп входов. В этом случае можно значительно уменьшить размер актуального подмножества ВКТЗ. Специальный случай случай ограничиваемого комбинирования, когда «замораживаются» все входы, кроме одного, позволяет проводить тестирование граничных интервалов.
5. Методы c -арных частичных комбинаций. Обладают универсальной применимостью (применим практически при любом числе входов) и не требуют сколько-нибудь заметных ресурсов тестирования. Наиболее эффективны при совмещении их с методами эквивалентных классов и граничных значений. При использовании любых комбинационных методов целесообразно, если в результирующем подмножестве полного покрытия не достигается, расширить его общепокрывающим способом.
6. Методы случайного покрытия. Случайное покрытие можно рассматривать как дополнение к комбинационным методам и использовать при наличии значительных ресурсах тестирования. Методы случайного покрытия имеют определенные перспективы при тестировании взаимозависимых входов. Метод зондирования, хотя и не требует значительных ресурсов, требует знания локализации проблемной области входного пространства.
7. Комбинации методов. Методы могут «складываться» (результирующие подмножества объединяются) или «умножаться» (результат первого метода обрабатывается вторым). В качестве примера приведем выделение категории BN с последующим расширением тестового подмножества до полного c -арного покрытия.
Соотношение размеров полного множества ВКТЗ с доступными ресурсами тестирования.
Даже несмотря на то, что в комплекте опорных тест-значений используется ограниченная выборка, из-за экспоненциального роста числа с увеличением числа входов гнезда получаемое множество ВКТЗ может получиться недопустимо большим. Принадлежность полного множества к той или иной критической градации размеров определяет стратегию генерации тестовых наборов (см. таблицу 7).
Таблица 7. Стратегии формирования тест-наборов в зависимости от градации размеров полного множества ВКТЗ.
|
№№ п./п. |
Градации размеров полного множества ВКТЗ |
Стратегии формирования тест-наборов ВКТЗ |
|
1 |
Размер полного множества не превосходит допускаемого по имеющимся ресурсам тестирования величины. |
Полное множество ВКТЗ. |
|
2 |
Размер полного множества превосходит ресурс тестирования, но не превосходит величины, допускаемой ресурсами дисковой памяти. |
Для получения возможно использование всех методов и их комбинаций. |
|
3 |
Размер полного множества превосходит ресурс памяти, но не превосходит ресурса соответствующему ему времени генерации тест-набора (временной ресурс). |
Возможно выделение подмножеств с размером, не превосходящим величины, допускаемой ресурсами дисковой памяти с последующим использованием остальных методов. |
|
4 |
Размер полного множества таков, что временного ресурса недостаточно. |
Необходимо использование методов c -арных частичных комбинаций. |
Оптимизация размеров тестовых подмножеств ВКТЗ.
В свете принятого подхода задача конструирования тест-набора не сводится только к «сокращению» полного множества, а скорее заключается в гибком балансировании сокращения/сжатия с учетом наличных ресурсов. Так и при ручном тестировании и ограниченных ресурсах актуально сокращение тест-наборов. Однако всякое сокращение такого рода увеличивает риск пропуска программного дефекта. Поэтому, при автоматизации тестирования и значительных ресурсах, напротив, актуальна задача расширения. InputSpace TestGenerator предоставляет широкие возможности в обоих направлениях. В таблице 8 систематизируются способы сокращения/сжатия тест-наборов.
Таблица 8. Методы сокращения/сжатия тестовых подмножеств.
|
Сокращение |
Расширение |
|
Уменьшение размеров комплекта опорных тест-значений. |
Увеличение размеров комплекта опорных тест-значений. |
|
Ограничиваемое комбинирование. |
Полное комбинирование. |
|
Минимальное представление тест-наборов отрицательного тестирования. |
Равное представление тест-наборов положительного и отрицательного тестирования. |
|
Минимальное представление тест-наборов несовместимых комбинаций тест-значений. |
Равное представление тест-наборов совместимых и несовместимых комбинаций тест-значений. |
|
Выделение подмножества граничных категорий с наиболее высоким приоритетом. |
Выделение подмножеств граничных категорий с убывающим приоритетов. |
|
Использование детализации граничных категорий по параметрам Зкстремальность и Число внеграничных окрестностей. |
Использование полных граничных категорий. |
|
Выделение подмножеств в диапазоне максимального рейтинга. |
Выделение подмножеств в диапозоне убывающих значений рейтинга. |
|
Генерация с-МРС-выборок с с = 2. |
Генерация МРС-выборок с c > 2, вплоть до m -1 , где m - число входов. |
|
Наложение фильтров («умножение» подмножеств). |
Сложение подмножеств. Увеличение числа подмножеств-слагаемых. |
|
Использование высокоприоритетной части отсортированного тест-набора. |
Использование всего тест-набора. |
|
Использование кодов приоритетов гнезд как показателей актуальности их тестирования. |
Использование при тестировании тест-наборов всех гнезд. |
|
Ограничение лишь генерацией комбинирования. |
Использование как генераторов комбинирования, так и генераторов покрытия. |
|
Использование только прицельное покрытие покрытие одной или нескольких зон входного пространства. |
Использование равномерного случайного покрытия всего входного пространства. Размер выборки не ограничивается. |