| СТАТЬЯ | 08.08.01 |
Исследование возможностей CASE-технологии при создании интеллектуальных систем управления
(c) 2000 Семизельникова О.А.
Эта статья была размещена на сайте www.inftech.webservis.ru/
2.1.2. Интеллектуальные системы управления
Как было указано выше, существующие CASE-средства позволяют создавать информационные системы как правило на основе реляционных баз данных, которые несмотря на всю свою привлекательность и “привычность”, являются ограниченными при использовании в ИСУ. Они идеально походят для таких традиционных приложений, как системы резервирования билетов или мест в гостиницах, а также банковских систем, но их применение в системах управления большими корпорациями или сверхсложными объектами с тысячами динамически изменяющихся параметров типа ракетно-космических комплексов, производящих корпораций и т. п. часто является затруднительным. Управление в наземных, полетных и других условиях объектами высшей технической сложности, управление в корпорациях, министерствах, экосистемах и т. д., управление в научных проектах, связанных с динамикой исследуемых объектов является естественной областью приложения для интеллектуальных систем управления (ИСУ).
ИСУ можно определить как автоматические системы, умеющие самостоятельно выделять знание об объекте и внешнем мире из поступающей информации, вырабатывать управляющие воздействия в тех случаях, когда математический аппарат оптимизации не может быть применен, и, в этом случае, удовлетворительно работающие при решении задач управления сложными объектами в условиях неопределенной информации о внутрисистемных связях управляемого объекта и возмущающих воздействиях среды функционирования.
Отличительной особенностью является то, что ИСУ принципиально ориентирована на работу со сложными, функционально неопределяемыми системами без участия человека. Для данных систем ставиться вопрос об автоматической выработке решения внутри управляющей системы на основе накопленного в ней и в управляемой системе знания, без ориентации на нахождение функционального описания управляемой системы.
Определение знания как информационной структуры связи данных, которую можно наблюдать, изучать и изменять, приводит к инженерно понятному подходу к работе со знанием. Кроме того, такое определение наводит порядок в терминологической путанице понятий “база данных” и “база знания”, разобраться с которыми по большинству публикаций крайне затруднительно.
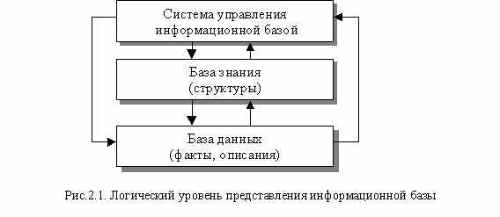
Такая система на логическом уровне представления (рис.2.1) состоит из связанной базы данных (БД) и базы знания (БЗ), которые в совокупности обычно называют просто информационной базой данных, и инструмента (системы) ее разработки и управления (СУБД).
В случае целенаправленной работы со структурами данных, база становится интеллектуальной (ИБ данных и знания или просто ИБ) по определению интеллектуальной системы.
Инструментом создания и управления такой базой (СУИБ) является сама ИСУ, содержащая эту базу, так как одной из ее задач как раз и является накопление, структуризация и использование данных и их контекстных связей для принятия управляющих решений.
Введенное понятие интеллектуальной базы в составе базы данных и базы знания является исключительно конструктивным. С одной стороны оно дает возможность построения функциональной схемы ИСУ на основе достаточного количества таких баз разного целевого назначения, но, самое главное, оно обеспечивает возможность формирования новой парадигмы управления.
Классическая парадигма управления (“сигнальная” или “передаточная”) происходит от понятия управляющего сигнала, выражаемого в аналоговой или цифровой форме, контроля достигнутого результата управления и его коррекции за счет изменения передаточных характеристик системы управления с обратной связью.
Исторически сложившаяся парадигма управления берет начало от подходов и математических аппаратов, связанных с теорией сигналов и не претендует ни на что, кроме моделирования сложных систем методами прикладной математики. Такого рода парадигма естественна и допустима для систем, сложность которых допускает их кибернетическое представление или моделирование. Сохранение этой парадигмы для системно-сложных объектов автоматически сводит систему к уровню кибернетической модели, что влечет за собой бессмысленность любых попыток организации ее управления на языках высокого уровня.
Автоматическая интеллектуальная система, в пределах своего знания и возможностей управления, достигает цели, не ориентируясь на управляющее воздействие.
Обратная связь, как способ коррекции передаточной функции, здесь не существует, в связи с полным отсутствием выраженной передаточной функции. Ее место занимает структура данных и аппарат согласования структур данных для выработки удовлетворительных соглашений между объектом и субъектом.
Система управления структурой данных является обязательным компонентом автоматической интеллектуальной (а значит и управляющей) системы, как верно и то, что данные не существуют без отношений между ними (того или иного варианта упорядочения) и соответственно, не отличаются, а неразделимы со знанием.
Любое управление может осуществляться только с использованием некоторого механизма обеспечения такого взаимодействия – языка. Языки, на которых возможно представление информации для управления, можно понятийно разделить на три группы.
Во-первых, это так называемые “математические языки” - языки описания функциональных связей, использующие математические символы, существующие и специально разрабатываемые математические функции. Они базируются на тех или иных непротиворечивых наборах исходных посылок и соглашений, аксиоматика которых является отдельным предметом математики. Примерами “математических языков” могут являться: “язык дифференциальных уравнений”, “язык (той или иной) алгебры” и др.
Во-вторых, это алгоритмические языки, языки программирования, разработанные для записи командных посылок для устройств типа компьютера. Они служат в тех случаях, когда управляющие действия не могут быть заданы более экономным математическим представлением. Эти языки базируются на некотором наборе изначально введенных соглашений, заданных на метаязыке, что позволяет гарантировать однозначность понимания допустимых терминов и команд во всех возможных ситуациях. В качестве примера здесь можно назвать “процедурные языки”, “объектно-ориентированные языки” и др.
В-третьих, это контекстно-зависимые (КЗ) языки, используемые как командные сообщения для систем управления способных воспринимать такие команды. Базирование управления на любых автоматах, включая сети Петри, ведет к упрощению КЗ языка, его обеднению, связанному с искусственным обеднением синтаксиса, семантики и прагматики с целью обеспечения их однозначного понимания. Примерами КЗ языков являются “иерархическая классификация”, “языки с фиксированными отношениями”, “проблемно-ориентированные языки, приближенные к естественным” и др.
В настоящее время для реализации ИСУ мы можем использовать пока только компьютер и, следовательно, можем применять только алгоритмические языки управления, которые с точки зрения управления обладают некоторыми достоинствами и недостатками. Самым главным вопросом, на который не дают ответа перечисленные подходы к организации языков программирования, является вопрос о том, существует ли в управлении сколько-нибудь сложный объект, стабильный по своей структуре и свойствам, необходимым для того, чтобы можно было в полной мере применять тот или иной язык?
Конечно, всегда можно предложить модель – выделенную ситуацию рассмотрения объекта как стабильного образования, не связанного с внешним миром или не изменяющегося под его воздействием. В общем же случае структура объекта находится в состоянии непрерывного изменения, связанного как с физической стороной его существования, так и с изменением целей, задач и “точки взгляда” на этот объект со стороны управляющей системы.
Требованием к языку управления даже и для интеллектуализированного подхода является даже не столько его объектная ориентированность, сколько автоматическая адаптация построений на том или ином языке к изменяющейся структуре объекта.
Структура объектов, предметной области определяют структуру базы данных. Известно, что база данных - это массив упорядоченных записей в памяти компьютера. Если упорядочение имеет древовидную структуру - это иерархическая база. Если упорядочение существует в виде отношений между таблицами данных - это реляционная база. Если группы записей отражают особенности описываемого объекта - это объектно-ориентированная база данных. Знание существует как отношение между данными, как именованная связь отдельных записей в базе данных. При этом необходимо, чтобы при изменении структуры предметной области эта связь могла легко изменяться и по адресации связей данных и по типу связей между ними. Мы должны изменять текущую структуру базы данных для фиксации знания, как текущего отношения между данными. Анализ таких связей дает информацию, не представленную в явном виде - логические интеллектуальные выводы.
Вот этого-то и не позволяют сколько-нибудь эффективно делать существующие базы данных. Их структура является предметом начального выбора проектировщика. Все современные базы не могут эффективно изменять свою структуру, не могут быть базами знания. Стабильная структура связей сокращает жизненный цикл базы, исключает обращение к ней с заранее не предусмотренными запросами и ведет, в конечном счете, к созданию ограниченных фактографических баз данных, как бы их не пытались в рекламных целях представлять хранилищами знания.
Однако, язык, позволяющий автоматически адаптировать построения к изменяющейся структуре объекта уже давно существует. Ранее известный под названием mumps, ныне он реализован в виде инструментальной системы информационной “Cache-технологии” компании InterSystem Corporation. Языки, ориентированные на структуры объектов, должны являться и базами, и Cache-технология, которую я использовала в работе, является именно таким сочетанием. Более подробная информация о системе Cache, будет приведена в разд. 2.2.
2.1.3. Конкретизация выбора инструментального средства разработки
В рамках Cache-технологии реализовано CASE-средство qWord (qW). Одно из главных положений qW-технологии – полная интеграция инструментальной и прикладной систем в единое целое. При этом модель проблемной области совсем уходит из программной реализации как целостный логический объект, остается вовне, в проблемной области, т.е. там, где она и была изначально.
Текущая реализация отображения модели (или совокупности таковых), которая присутствует в прикладной системе по умолчанию, считается не более чем одномоментной реализацией того состояния объекта (проблемной области), которое на этот момент доступно и актуально для пользователя. То есть становится в точности тем, что она (эта реализация) и есть на самом деле, и никак не более того.
С другой стороны, благодаря полной интеграции инструментальных средств и свойству “самоописания” системы, появляется реальная возможность использования сколь угодно сложных априори неопределяемых “объектов”, количество которых в принципе конструктивно бесконечно.
В qW используется унифицированное представление объектов, которое может изменять свой вид по мере изменения внешней среды – ПО и ее логических моделей, но никак не претендует на то, что априори содержит все логические модели. В качестве такового представления в qW предлагается фрейм - двойственная динамическая структура, которая может быть:
Внешнее, визуальное представление такого фрейма, выполнено в виде комплекта окон со стандартными атрибутами, а также атрибутами, обеспечивающими представление данных в реляционной или иерархической моделях (или их комбинации). Представление по мере надобности может быть изменено или дополнено. Структура хранения фрейма – стандартная, в В*-модели. Таким образом, БД, создаваемая в qW, и все окружение (управление БД) реализуются в единой программной среде и на базе единого представления В*-моделей.
На начальном этапе создания ИС проектируются только логические (внешние) модели ПО, данных и интерфейсов, осуществляется подбор и модификация комплекта фреймов (возможно и из “подходящей” или “похожей” ИС – приложения). Далее, по мере загрузки БД и накопления статистики запросов, при необходимости проводится коррекция моделей данных или создание новых – благо инструмент для этого у нас уже есть. Более того, не только инструмент, но и вся история попыток манипуляции с моделями данных, если, конечно, об этом позаботиться.
Более подробно qW будет рассмотрен в разд. 2.3.
Дополнительную информацию Вы можете получить в компании Interface Ltd.
Отправить ссылку на страницу по e-mail
Обсудить на форуме
| Interface Ltd. Отправить E-Mail http://www.interface.ru |
|
| Ваши
замечания и предложения отправляйте
автору По техническим вопросам обращайтесь к вебмастеру Документ опубликован: 08.08.01 |